Dr. O. Aly
Computer Science
The purpose of this discussion is to address one of the sectors that utilizes a few unique information technology (IT) requirements. The selected sector for this discussion is health care. The discussion addresses the IT needs based on a case study. The discussion begins with Information Technology Key Role in Business, followed by the Healthcare Industry Case Study.
Information Technology Key Role in Business
Information technology (IT) is a critical resource for businesses in the age of Big Data and Big Data Analytics (Dewett & Jones, 2001; Pearlson & Saunders, 2001). IT supports and consumes a significant amount of the resources of enterprises. IT needs to be managed wisely like other significant types of business resources such as people, money, and machines. These resources must return a value to the business. Thus, enterprises must carefully evaluate its resources including the IT resources that can be efficiently and effectively used.
Information system and technology are now integrated with almost every aspect of every business. IT and IS play significant roles in business, as it simplifies the organizational activities and processes. Enterprises can gain competitive advantages when utilizing appropriate information technology. The inadequate information system can cause a breakdown in providing services to customers or developing products which can harm sales and eventually the businesses (Bhatt & Grover, 2005; Brynjolfsson & Hitt, 2000; Pearlson & Saunders, 2001). The same thing applies when inefficient business processes sustained by ill-fitting information system and technology as they increase the cost on the business without any return on investment or value. The lag in the implementation or poor process adaptation reduce the profits and the growth and can place the business behind other competitors. The failure of the information system and technology in business is caused primarily by ignoring them during the planning of the business strategy and organizational strategy. IT will fail to support business goals and organizational systems because it was not considered in the business and organizational strategy. When the business strategy is misaligned with the organizational strategy, IT is subject to failure (Pearlson & Saunders, 2001).
IT Support to Business Goals
Enterprises should invest in IT resources that will benefit them. They should make investment in systems that supports their business goals including gaining competitive advantages (Bhatt & Grover, 2005). Although IT represents a significant investment in businesses, yet, the poorly chosen information system can become an obstacle to achieving the business goals (Dewett & Jones, 2001; Henderson & Venkatraman, 1999; Pearlson & Saunders, 2001). When the IT does not allow the business to achieve its goals, or lack the capacity required to collect, store, and transfer critical information for the business, the results can be disastrous, leading to dissatisfied customers, or excessive costs for production. The Toys R US store is an excellent example of such an issue (Pearlson & Saunders, 2001). The well-publicized website was not designed to process and fulfill orders fast enough. The site could be redesigned with an additional cost which could have been saved if the IT strategy and business goals were discussed together to be aligned together.
IT Support to Organizational Systems
Organizations systems including people, work processes, and structure represent the core elements of the business. Enterprises should plan to enable these systems to work together efficiently to achieve the business goals (Henderson & Venkatraman, 1999; Pearlson & Saunders, 2001; Ryssel, Ritter, & Georg Gemünden, 2004). When the IT of the business fails to support the business’ organization systems, the result is a misalignment of the resources needed to achieve the business goals. For instance, when organizations decide to use Enterprise Resource Planning (ERP) system, the system often dictates how many business processes are executed. When enterprises deploy a technology, they should think through various aspects such as how the technology will be used in the organization, who will use it, how they will use it, how to make sure the application chosen accomplishes what is intended. For instance, an organization which plans to institute a wide-scale telecommuting program would need an information system strategy that is compatible with its organization strategy (Pearlson & Saunders, 2001). The desktop PCs located within the corporate office are not the right solution for a telecommuting organization. Laptop computers application that are accessible online anywhere and anytime are a most appropriate solution. If a business only allows the purchase of desktop PCs and only builds systems accessible from desks within the office, the telecommuting program is subject to failure. Thus, information systems implementation should support the organizational systems and should be aligned with the business goals.
Advantages of IT in Business
Business is able to transform local business to international business with the advent of information system and internet (Bhatt & Grover, 2005; Zimmer, 2018). Organizations are under pressures to take advantages of information technology to gain competitive advantages. They are turning to information technology to streamline services and enhance the performance. IT has become an essential feature in the landscape of the business that aid business to decrease the costs, improve communication, develop recognition, and release more innovative and attractive products.
IT streamlines communication as effective communication is critical to an organization’s success (Bhatt & Grover, 2005; Zimmer, 2018). A key advantage of information system lies in its ability to streamline communication both internally and externally. For instance, online meeting and video conferencing platform such as Skype, WebEx provide business the opportunity to collaborate virtually in real-time, reducing costs associated with bringing clients on-site or communicating with staff who work remotely. IT enables Enterprises to connect almost effortlessly with international suppliers and consumers.
IT can enhance the competitive advantages in the marketplace of the business by facilitating strategic thinking and knowledge transfer (Bhatt & Grover, 2005; Zimmer, 2018). When using IT as a strategic investment and not as a means to an end, IT provides business with the tools they need to properly evaluate the market and implement strategies needed for a competitive edge.
IT stores and safeguards information, as information management is another domain of IT (Bhatt & Grover, 2005; Zimmer, 2018). IT is essential to any business that must store and safeguard sensitive information such as financial data for long periods. Various security techniques can be applied to ensure the data is stored in a secure place. Organizations should evaluate the options available to store their data such as locally using local data center or cloud-based storage methods.
IT cuts costs and eliminate waste (Bhatt & Grover, 2005; Zimmer, 2018). Although IT implementation at the beginning will be expensive, in the long run, it becomes incredibly cost-effective by streamlining the operational and managerial processes of the business. Thus, investing in the appropriate IT is key for a business to gain a return on investment. For instance, the implementation of online training programs is a classic example of IT improving the internal processes of the business by reducing the costs and employees’ time spent outside of work, and travel costs. Information technology enables organizations to implement more with less investment without sacrificing quality or value.
Healthcare Industry Case Study
The healthcare industry generated extensive data driven by keeping patients’ records, complying with regulations and policies, and patients care (Raghupathi & Raghupathi, 2014). The current trend is digitalizing this explosive growth of the data in the age of Big Data (BD) and Big Data Analytics (BDA) (Raghupathi & Raghupathi, 2014). BDA has made a revolution in healthcare by transforming the valuable information, knowledge to predict epidemics, cure diseases, improve quality of life, and avoid preventable deaths (Van-Dai, Chuan-Ming, & Nkabinde, 2016). Various applications of BDA in healthcare include pervasive health, fraud detection, pharmaceutical discoveries, clinical decision support system, computer-aided diagnosis, and biomedical applications.
Healthcare Big Data Benefits and Challenges
Healthcare sector employs BDA in various aspect of healthcare such as detecting diseases at early stages, providing evidence-based medicine, minimizing doses of medication to avoid any side effects, and delivering useful medicine base on genetic analysis. The use of BD and BDA can reduce the re-admission rate, and thereby the healthcare related costs for patients are reduced. Healthcare BDA can be used to detect spreading diseases earlier before the disease gets spread using real-time analytics (Archenaa & Anita, 2015; Raghupathi & Raghupathi, 2014; Wang, Kung, & Byrd, 2018). Example of the application of BDA in the healthcare system is Kaiser Permanente implementing a HealthConnect technique to ensure data exchange across all medical facilities and promote the use of electronic health records (Fox & Vaidyanathan, 2016).
Despite the various benefits of BD and BDA in the healthcare sector, various challenges and issues are emerging from the application of BDA in healthcare. The nature of the healthcare industry poses challenging to BDA (Groves, Kayyali, Knott, & Kuiken, 2016). The episodic culture, the data puddles, and the IT leadership are the three significant challenges of the healthcare industry to apply BDA. The episodic culture addresses the conservative culture of the healthcare and the lack of IT technologies mindset creating rigid culture. Few providers have overcome this rigid culture and started to use the BDA technology. The data puddles reflect the silo nature of healthcare. Silo is described as one of the most significant flaws in the healthcare sector (Wicklund, 2014). The use of the technology properly is lacking in healthcare sector resulting in making the industry fall behind other industries. All silos use their methods to collect data from labs, diagnosis, radiology, emergency, case management and so forth. The IT leadership is another challenge is caused by the rigid culture of the healthcare industry. The lack of the latest technologies among the IT leadership in the healthcare industry is a severe problem.
Healthcare Data Sources for Data Analytics
The current healthcare data is collected from clinical and non-clinical sources (InformationBuilders, 2018; Van-Dai et al., 2016; Zia & Khan, 2017). The electronic healthcare records are digital copies of the medical history of the patients. It contains a variety of data relevant to the care of the patients such as demographics, medical problems, medications, body mass index, medical history, laboratory test data, radiology reports, clinical notes, and payment information. These electronic healthcare records are the most critical data in healthcare data analytics, because it provides effective and efficient methods for the providers and organizations to share data (Botta, de Donato, Persico, & Pescapé, 2016; Palanisamy & Thirunavukarasu, 2017; Van-Dai et al., 2016; Wang et al., 2018).
The biomedical imaging data plays a crucial role in healthcare data to aid disease monitoring, treatment planning and prognosis. This data can be used to generate quantitative information and make inferences from the images that can provide insights into a medical condition. The images analytics is more complicated due to the noises of the data associated with the images and is one of the significant limitations with biomedical analysis (Ji, Ganchev, O’Droma, Zhang, & Zhang, 2014; Malik & Sangwan, 2015; Van-Dai et al., 2016).
The sensing data is ubiquitous in the medical domain both for real-time and for historical data analysis. The sensing data involve several forms of medical data collection instruments such as the electrocardiogram (ECG) and electroencephalogram (EEG) which are vital sensors to collect signals from various parts of the human body. The sensing data plays a significant role for intensive care units (ICU) and real-time remote monitoring of patients with specific conditions such as diabetes or high blood pressure. The real-time and long-term analysis of various trends and treatment in remote monitoring programs can help providers monitor the state of those patients with certain conditions(Van-Dai et al., 2016).
The biomedical signals are collected from many sources such as hearts, blood pressure, oxygen saturation levels, blood glucose, nerve conduction, and brain activity. Examples of biomedical signals include electroneurogram (ENG), electromyogram (EMG), electrocardiogram (ECG), electroencephalogram (EEG), electrogastrogram (EGG), and phonocardiogram (PCG). The biomedical signals real-time analytics will provide better management of chronic diseases, earlier detection of adverse events such as heart attacks, and strokes and earlier diagnosis of disease. These biomedical signals can be discrete or continuous based on the kind of care or severity of a particular pathological condition (Malik & Sangwan, 2015; Van-Dai et al., 2016).
The genomic data analysis helps better understand the relationship between various genetic, mutations, and disease conditions. It has great potentials in the development of various gene therapies to cure certain conditions. Furthermore, the genomic data analytics can assist in translating genetic discoveries into personalized medicine practice (Liang & Kelemen, 2016; Luo, Wu, Gopukumar, & Zhao, 2016; Palanisamy & Thirunavukarasu, 2017; Van-Dai et al., 2016).
The clinical text data analytics using the data mining are the transformation process of the information from clinical notes stored in unstructured data format to useful patterns. The manual coding of clinical notes is costly and time-consuming, because of their unstructured nature, heterogeneity, different format, and context across different patients and practitioners. Various methods such as natural language processing (NLP) and information retrieval can be used to extract useful knowledge from large volume of clinical text and automatically encoding clinical information in a timely manner (Ghani, Zheng, Wei, & Friedman, 2014; Sun & Reddy, 2013; Van-Dai et al., 2016).
The social network healthcare data analytics is based on various kinds of collected social media sources such as social networking sites, e.g., Facebook, Twitter, Web Logs, to discover new patterns and knowledge that can be leveraged to model and predict global health trends such as outbreaks of infections epidemics (InformationBuilders, 2018; Luo et al., 2016; Van-Dai et al., 2016; Zia & Khan, 2017).
IT Requirements for Healthcare Sector
The basic requirement for the implementation of this proposal included not only the tools and required software, but also the training at all levels from staff, to nurses, to clinicians, to patients. The list of the requirements is divided into system requirement, implementation requirement, and training requirements.
Cloud Computing Technology Adoption Requirement
The volume is one of the significant characteristics of BD, especially in the healthcare industry (Manyika et al., 2011). Based on the challenges addressed earlier when dealing with BD and BDA in healthcare, the system requirements cannot be met using the traditional on-premise technology center, as it cannot handle the intensive computation requirements of BD, and the storage requirement for all the medical information from various hospitals from the four States (Hu, Wen, Chua, & Li, 2014). Thus, the cloud computing environment is found to be more appropriate and a solution for the implantation of this proposal. Cloud computing plays a significant role in BDA (Assunção, Calheiros, Bianchi, Netto, & Buyya, 2015). The massive computation and storage requirement of BDA brings the critical need for cloud computing emerging technology (Mehmood, Natgunanathan, Xiang, Hua, & Guo, 2016). Cloud computing offers various benefits such as cost reduction, elasticity, pay per use, availability, reliability, and maintainability (Gupta, Gupta, & Mohania, 2012; Kritikos, Kirkham, Kryza, & Massonet, 2017). However, although cloud computing offers various benefits, it has security and privacy issues using the standard deployment models of public cloud, private cloud, hybrid cloud, and community cloud. Thus, one of the major requirements is to adopt the Virtual Private Cloud as it has been regarded as the most prominent approach to trusted computing technology (Abdul, Jena, Prasad, & Balraju, 2014).
Cloud computing has been facing various threats (Cloud Security Alliance, 2013, 2016, 2017). Records showed that over the last three years from 2015 until 2017, the number of breaches, lost medical records, and settlements of fines are staggering (Thompson, 2017). The Office of Civil Rights (OCR) issued 22 resolution agreements, requiring monetary settlements approaching $36 million (Thompson, 2017). Table 1 shows the data categories and the total for each year.
Table 1. Approximation of Records Lost by Category Disclosed on HHS.gov (Thompson, 2017)
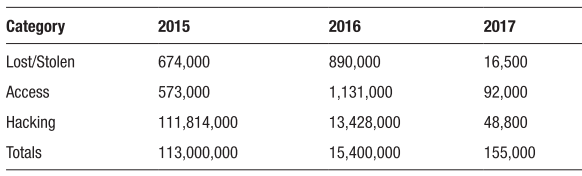
Furthermore, a recent report published by HIPAA showed the first three months of 2018 experienced 77 healthcare data breaches reported to the OCR (HIPAA, 2018d). In the second quarter of 2018, at least 3.14 million healthcare records were exposed (HIPAA, 2018a). In the third quarter of 2018, 4.39 million records exposed in 117 breaches (HIPAA, 2018c).
Thus, the protection of the patients’ private information requires the technology to extract, analyze, and correlated potentially sensitive dataset (HIPAA, 2018b). The implementation of BDA requires security measures and safeguards to protect the privacy of the patients in the healthcare industry (HIPAA, 2018b). Sensitive data should be encrypted to prevent the exposure of data in the event of theft (Abernathy & McMillan, 2016). The security requirements involve security at the VPC cloud deployment model as well as at the local hospitals in each State (Regola & Chawla, 2013). The security at the VPC cloud deployment model should involve the implementation of security groups and network access control lists to allow access to the right individuals to the right applications and patients’ records. Security group in VPC acts as the first line of defense firewall for the associated instances of the VPC (McKelvey, Curran, Gordon, Devlin, & Johnston, 2015). The network access control lists act as the second layer of defense firewall for the associated subnets, controlling the inbound and the outbound traffic at the subnet level (McKelvey et al., 2015).
The security at the local hospitals level in each State is mandatory to protect patients’ records and comply with HIPAA regulations (Regola & Chawla, 2013). The medical equipment must be secured with authentication and authorization techniques so that only the medical staff, nurses and clinicians have access to the medical devices based on their role. The general access should be prohibited as every member of the hospital has a different role with different responses. The encryption should be used to hide the meaning or intent of communication from unintended users (Stewart, Chapple, & Gibson, 2015). The encryption is an essential element in security control especially for the data in transit (Stewart et al., 2015). The hospital in all four State should implement the encryption security control using the same type of the encryption across the hospitals such as PKI, cryptographic application, and cryptography and symmetric key algorithm (Stewart et al., 2015).
The system requirements should also include the identity management systems that can correspond with the hospitals in each state. The identity management system provides authentication and authorization techniques allowing only those who should have access to the patients’ medical records. The proposal requires the implementation of various encryption techniques such as secure socket layer (SSL), Transport Layer Security (TLS), and Internet Protocol Security (IPSec) to protect information transferred in public network (Zhang & Liu, 2010).
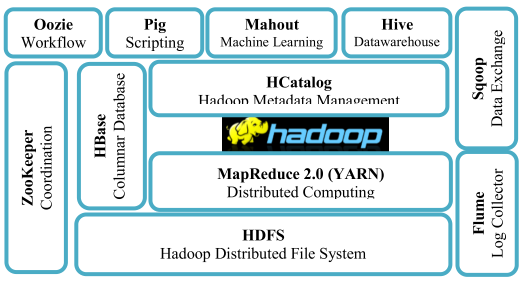
Hadoop Implementation for Data Stream Processing Requirement
While the velocity of BD leads to the speed of generating large volume of data and requires speed in data processing (Hu et al., 2014), the variety of the data requires specific technology capabilities to handle various types of dataset such as structured, semi-structured, and unstructured data (Bansal, Deshpande, Ghare, Dhikale, & Bodkhe, 2014; Hu et al., 2014). Hadoop ecosystem is found to be the most appropriate system that is required to implement BDA (Bansal et al., 2014; Dhotre, Shimpi, Suryawanshi, & Sanghati, 2015). The implementation requirements include various technologies and various tools. This section covers various components that are required when implementing Hadoop technology in the four States for healthcare BDA system.
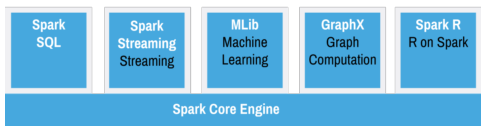
Hadoop has three significant limitations, which must be addressed in this design. The first limitation is the lack of technical support and document for open source Hadoop (Guo, 2013). Thus, this design requires the Enterprise Edition of Hadoop to get around this limitation using Cloudera, Hortonworks, and MapR (Guo, 2013). The final decision for which product will be determined by the cost analysis team. The second limitation is that Hadoop is not optimal for real-time data processing (Guo, 2013). The solution for this limitation will require the integration of real-time streaming program as Spark or Storm or Kafka (Guo, 2013; Palanisamy & Thirunavukarasu, 2017). This requirement of integrating Spark is discussed below in a separate requirement for this design (Guo, 2013). The third limitation is that Hadoop is not a good fit for large graph dataset (Guo, 2013). The solution for this limitation requires the integration of GraphLab which is also discussed below in a separate requirement for this design.
Conclusion
Information technology (IT) play a significant role in various industries including the healthcare sector. This project discussed the IT role in businesses, the requirement to be aligned with the strategic goal and organizational system of the business. If IT systems are not included during the planning of the business strategy and organizational strategy, the IT integration into the business at a later stage is very likely to set for failure. IT offers various advantages to business including the competitive advantages in the marketplace. Healthcare industry is no exception to integrate IT systems. Healthcare sector has been suffering from various challenges including the high cost of services and inefficient service to patients. The case study showed the need for IT systems requirements that can place the industry into competitive advantages offering better care to patients with low cost. Various IT integrations have been used lately in the healthcare industry including Big Data Analytics, Hadoop technology, security systems, and cloud computing. Kaiser Permanente, for instance, applied Big Data Analytics using HealthConnet to provide care to patients with lower cost and better care, which are aligned with the strategic goal of its business.
References
Abdul, A. M., Jena, S., Prasad, S. D., & Balraju, M. (2014). Trusted Environment In Virtual Cloud. International Journal of Advanced Research in Computer Science, 5(4).
Abernathy, R., & McMillan, T. (2016). CISSP Cert Guide: Pearson IT Certification.
Archenaa, J., & Anita, E. M. (2015). A survey of big data analytics in healthcare and government. Procedia Computer Science, 50, 408-413.
Assunção, M. D., Calheiros, R. N., Bianchi, S., Netto, M. A. S., & Buyya, R. (2015). Big Data Computing and Clouds: Trends and Future Directions. Journal of Parallel and Distributed Computing, 79, 3-15. doi:10.1016/j.jpdc.2014.08.003
Bansal, A., Deshpande, A., Ghare, P., Dhikale, S., & Bodkhe, B. (2014). Healthcare data analysis using dynamic slot allocation in Hadoop. International Journal of Recent Technology and Engineering, 3(5), 15-18.
Bhatt, G. D., & Grover, V. (2005). Types of information technology capabilities and their role in competitive advantage: An empirical study. Journal of management information systems, 22(2), 253-277.
Botta, A., de Donato, W., Persico, V., & Pescapé, A. (2016). Integration of Cloud Computing and Internet Of Things: a Survey. Future Generation computer systems, 56, 684-700.
Brynjolfsson, E., & Hitt, L. M. (2000). Beyond computation: Information technology, organizational transformation and business performance. Journal of Economic perspectives, 14(4), 23-48.
Cloud Security Alliance. (2013). The Notorious Nine: Cloud Computing Top Threats in 2013. Cloud Security Alliance: Top Threats Working Group.
Cloud Security Alliance. (2016). The Treacherous 12: Cloud Computing Top Threats in 2016. Cloud Security Alliance: Top Threats Working Group.
Cloud Security Alliance. (2017). The Treacherous 12 Top Threats to Cloud Computing. Cloud Security Alliance: Top Threats Working Group.
Dewett, T., & Jones, G. R. (2001). The role of information technology in the organization: a review, model, and assessment. Journal of Management, 27(3), 313-346.
Dhotre, P., Shimpi, S., Suryawanshi, P., & Sanghati, M. (2015). Health Care Analysis Using Hadoop. Internationaljournalofscientific&tech nologyresearch, 4(12), 279r281.
Fox, M., & Vaidyanathan, G. (2016). Impacts of Healthcare Big Data: A Framwork With Legal and Ethical Insights. Issues in Information Systems, 17(3).
Ghani, K. R., Zheng, K., Wei, J. T., & Friedman, C. P. (2014). Harnessing big data for health care and research: are urologists ready? European urology, 66(6), 975-977.
Groves, P., Kayyali, B., Knott, D., & Kuiken, S. V. (2016). The ‘Big Data’ Revolution in Healthcare: Accelerating Value and Innovation.
Guo, S. (2013). Hadoop operations and cluster management cookbook: Packt Publishing Ltd.
Gupta, R., Gupta, H., & Mohania, M. (2012). Cloud Computing and Big Data Analytics: What is New From Databases Perspective? Paper presented at the International Conference on Big Data Analytics, Springer-Verlag Berlin Heidelberg.
Henderson, J. C., & Venkatraman, H. (1999). Strategic alignment: Leveraging information technology for transforming organizations. IBM systems journal, 38(2.3), 472-484.
HIPAA. (2018a). At Least 3.14 Million Healthcare Records Were Exposed in Q2, 2018. Retrieved 11/22/2018 from https://www.hipaajournal.com/q2-2018-healthcare-data-breach-report/.
HIPAA. (2018b). How to Defend Against Insider Threats in Healthcare. Retrieved 8/22/2018 from https://www.hipaajournal.com/category/healthcare-cybersecurity/.
HIPAA. (2018c). Q3 Healthcare Data Breach Report: 4.39 Million Records Exposed in 117 Breaches. Retrieved 11/22/2018 from https://www.hipaajournal.com/q3-healthcare-data-breach-report-4-39-million-records-exposed-in-117-breaches/.
HIPAA. (2018d). Report: Healthcare Data Breaches in Q1, 2018. Retrieved 5/15/2018 from https://www.hipaajournal.com/report-healthcare-data-breaches-in-q1-2018/.
Hu, H., Wen, Y., Chua, T., & Li, X. (2014). Toward Scalable Systems for Big Data Analytics: A Technology Tutorial. Practical Innovation, Open Solution, 2, 652-687. doi:10.1109/ACCESS.2014.2332453
InformationBuilders. (2018). Data In Motion – Big Data Analytics in Healthcare. Retrieved from http://docs.media.bitpipe.com/io_10x/io_109369/item_674791/datainmotionbigdataanalytics.pdf, White Paper.
Ji, Z., Ganchev, I., O’Droma, M., Zhang, X., & Zhang, X. (2014). A cloud-based X73 ubiquitous mobile healthcare system: design and implementation. The Scientific World Journal, 2014.
Kritikos, K., Kirkham, T., Kryza, B., & Massonet, P. (2017). Towards a Security-Enhanced PaaS Platform for Multi-Cloud Applications. Future Generation computer systems, 67, 206-226. doi:10.1016/j.future.2016.10.008
Liang, Y., & Kelemen, A. (2016). Big Data Science and its Applications in Health and Medical Research: Challenges and Opportunities. Austin Journal of Biometrics & Biostatistics, 7(3).
Luo, J., Wu, M., Gopukumar, D., & Zhao, Y. (2016). Big data application in biomedical research and health care: a literature review. Biomedical informatics insights, 8, BII. S31559.
Malik, L., & Sangwan, S. (2015). MapReduce Framework Implementation on the Prescriptive Analytics of Health Industry. International Journal of Computer Science and Mobile Computing, ISSN, 675-688.
Manyika, J., Chui, M., Brown, B., Bughin, J., Dobbs, R., Roxburgh, C., & Byers, A. H. (2011). Big Data: The Next Frontier for Innovation, Competition, and Productivity. McKinsey Global Institute.
McKelvey, N., Curran, K., Gordon, B., Devlin, E., & Johnston, K. (2015). Cloud Computing and Security in the Future Guide to Security Assurance for Cloud Computing (pp. 95-108): Springer.
Mehmood, A., Natgunanathan, I., Xiang, Y., Hua, G., & Guo, S. (2016). Protection of Big Data Privacy. Institute of Electrical and Electronic Engineers, 4, 1821-1834. doi:10.1109/ACCESS.2016.2558446
Palanisamy, V., & Thirunavukarasu, R. (2017). Implications of Big Data Analytics in developing Healthcare Frameworks–A review. Journal of King Saud University-Computer and Information Sciences.
Pearlson, K., & Saunders, C. (2001). Managing and Using Information Systems: A Strategic Approach. 2001: USA: John Wiley & Sons.
Raghupathi, W., & Raghupathi, V. (2014). Big data analytics in healthcare: promise and potential. Health Information Science and Systems, 2(1), 1.
Regola, N., & Chawla, N. (2013). Storing and Using Health Data in a Virtual Private Cloud. Journal of medical Internet research, 15(3), 1-12. doi:10.2196/jmir.2076
Ryssel, R., Ritter, T., & Georg Gemünden, H. (2004). The impact of information technology deployment on trust, commitment and value creation in business relationships. Journal of business & industrial marketing, 19(3), 197-207.
Stewart, J., Chapple, M., & Gibson, D. (2015). ISC Official Study Guide. CISSP Security Professional Official Study Guide (7th ed.): Wiley.
Sun, J., & Reddy, C. (2013). Big Data Analytics for Healthcare. Retrieved from https://www.siam.org/meetings/sdm13/sun.pdf.
Thompson, E. C. (2017). Building a HIPAA-Compliant Cybersecurity Program, Using NIST 800-30 and CSF to Secure Protected Health Information.
Van-Dai, T., Chuan-Ming, L., & Nkabinde, G. W. (2016, 5-7 July 2016). Big data stream computing in healthcare real-time analytics. Paper presented at the 2016 IEEE International Conference on Cloud Computing and Big Data Analysis (ICCCBDA).
Wang, Y., Kung, L. A., & Byrd, T. A. (2018). Big Data Analytics: Understanding its Capabilities and Potential Benefits for Healthcare Organizations. Technological Forecasting and Social Change, 126, 3-13. doi:10.1016/j.techfore.2015.12.019
Wicklund, E. (2014). ‘Silo’ one of healthcare’s biggest flaws. Retrieved from http://www.healthcareitnews.com/news/silo-one-healthcares-biggest-flaws.
Zhang, R., & Liu, L. (2010). Security models and requirements for healthcare application clouds. Paper presented at the Cloud Computing (CLOUD), 2010 IEEE 3rd International Conference on.
Zia, U. A., & Khan, N. (2017). An Analysis of Big Data Approaches in Healthcare Sector. International Journal of Technical Research & Science, 2(4), 254-264.
Zimmer, T. (2018). What Are the Advantages of Information Technology in Business?