"Artificial Intelligence without Big Data Analytics is lame, and Big Data Analytics without Artificial Intelligence is blind." Dr. O. Aly, Computer Science.
The purpose of this discussion is to
address a high-level understanding of the Sarbanes-Oxley (SOX) Act of 2002. The
focus of the discussion will be on the role of IT such as COBIT in the
implementation of SOX. The discussion
also addresses some of the other frameworks that can be used to implement SOX,
with a focus on one selected framework and rationale for such a choice. The
discussion begins with the Controls
Frameworks Background, followed by the Sarbanes-Oxley
(SOX) Act.
Controls Frameworks Background
In 1929, Wall Street crashed (Shofner & Adams, n.d.). In 1934, the
US Security and Exchange Commission (SEC)
was formed, and public companies required
to perform annual audits. In 1987, the
Treadway Commission was formed in
response to corrupt mid-1970s accounting practices, retains Coopers &
Lybrand to perform a project to create an
accounting control framework. In 1992, Internal Control – Integrated Framework,
a four-volume report was released by the
Committee of Sponsoring Organizations (COSO). A survey result shows that 82% of
the respondents used COSO (Shofner & Adams, n.d.). In 1996, the
Information Technology Governance
Institute (ITGI) released the Control Objectives for Information and Related
Technology (COBIT) Framework. In 2002,
Sarbanes-Oxley (SOX) Act passed, requiring companies to adopt and declare a
framework used to define and assess the internal controls (Pearlson & Saunders, 2001; Shofner & Adams, n.d.).
Sarbanes-Oxley (SOX) Act
Sarbanes-Oxley (SOX) Act is a Public Company Accounting
Reform and Investor Protection Act (PCAOB) of 2002. The SOX Act affects organizations that are publicly traded in the United States (Abernathy & McMillan, 2016; Pearlson & Saunders, 2001). It controls
the accounting methods and financial reporting for the organizations and
stipulates penalties and even jail time for executive officers. SOX introduced new
limitations on auditors including mandatory partner rotation and limits on
services (Bannister, 2006). It requires
new disclosure controls that inform corporate officers of material information
during the reporting period. The purpose
of SOX is to reduce the possibilities of corporate fraud by increasing the
stringency of procedures and requirements for financial reporting (Sarbanes-Oxley, 2002). It is worth to mention two significant sections of SOX, section 302 for financial reporting
and section 404 for internal control (Bannister, 2006).
Section 302 of the SOX Act directed the Security and
Exchange Commission (SEC) to adopt rules to require the principal executive and
financial officers of a public company to certify in their company’s annual and
quarterly reports that such reports are accurate and complete and that they have established and maintained adequate
internal controls for public disclosure.
The purpose of this section is to ensure that the CEO and CFO take a
proactive role in their company’s public disclosure and to give investors more
confidence in the accuracy, quality, and
reliability of the company’s SEC periodic reports (Sarbanes-Oxley, 2018a).
Section 404 of the SOX
Act requires the publicly-held company’s auditor to attest to, and report on,
management’s assessment of its internal control. It mandates that all publicly-traded
companies must establish internal controls and procedures for financial
reporting and must document, test and maintain those controls and procedures to
ensure their effectiveness (Sarbanes-Oxley, 2018b).
Business Audit and Strategic Security Risk Assessment
Security Information and Event Management (SIEM or
SIM/SEM) solutions play a significant role in monitoring operational security
and supporting organizations in decision
making (Zhu, Hill, & Trovati, 2016). SIEM
provides a standardized approach to collect information and events, store and
query and provide degrees of correlations, usually driven by rules. The leading
SIEM solutions in the market include HP
ArcSight, IBM Security QRadar, LogRhythm, and EMC Corp. However, SIEM does not cover the business audit and
strategic security risk assessment but instead provide inputs that need to be adequately analyzed and translated into a
suitable format to be used by senior risk assessors and strategic policymakers.
The risk assessment standards such as ISO2700x, NIST
and so forth operate at a macro level and usually do not fully use the
information coming from the logging and auditing activities carried bout by IT
operations. Some frameworks for auditing
the companies IT controls, most notably
COSO and COBIT (Bannister, 2006; Zhu et al., 2016). COBiT and COSO frameworks become more critical in
documenting and testing the effectiveness of the internal controls. However, COSO is not sufficient alone (Bannister, 2006; Shofner & Adams, n.d.).
Other types of detective techniques are concerned
with the cloud computing services adoption rather than the security and
information monitoring. Examples of
these techniques include Sumo Logic,
Amazon Web Services (AWS) CloudTrail, and Logentries.
COBIT IT Control Framework for Sarbanes-Oxley (SOX)
COBIT stands for Control Objectives for Information and Related Technology. It is a documented set of best IT security practices designed by the Information Systems and Control Association (ISACA) (Stewart, Chapple, & Gibson, 2015). COBIT is used to plan the IT security of an organization and also serve as a guideline for auditors. It is a security concept infrastructure used to organize the complex security solution of companies. COBIT has a series of COBIT from COBIT 1, COBIT 2, COBIT 3, COBIT 4 and 4.1, and COBIT 5. Figure 1 illustrates the history of COBIT.
Figure 1. COBIT History (Shofner & Adams, n.d.).
COBIT prescribes goals and requirements for security
controls and encourages the mapping of IT security ideals to business
objectives. COBIT five is based on five fundamental principles for governance and management of enterprise IT (itgovernanceusa.com, 2018; Shofner & Adams, n.d.). Principle
One is about meeting the stakeholder’s
needs. Principle Two is about covering
the Enterprise end-to-end. Principle
Three is about applying a Single, Integrated Framework. Principle Four is about
Enabling a Holistic Approach. Principle
Five is about Separating Governance From Management (Bannister, 2006).
Other standards and guidelines for IT security
include the Open Source Security Testing Methodology Manual (OSSTMM),
ISO/IEC27002 which replaced ISO17799, and the Information Technology Infrastructure Library (ITIL) (Pearlson &
Saunders, 2001; Shofner & Adams, n.d.).
COBIT Advantages and Rationale
COBIT is well suited to organizations focused on risk management and mitigation, and it is detailed (Pearlson & Saunders, 2001). COBIT is chosen for Sarbanes Oxley (SOX) because it is the most widely-recognized internal control framework used to achieve IT SOX compliance (itgovernanceusa.com, 2018). It has more breadth of IT control coverage. COSO, ISO 17799 and ITIL provide medium control coverage, while COBIT provides a high level of control coverage (Bannister, 2006). Figure 2 illustrates the breadth of IT control coverage and the position of COBIT.
Figure 2. COBIT Control Coverage (Bannister, 2006).
COBIT is internationally accepted good practices, a
de facto standard. It is management oriented and supported by tools and
training. It is freely available and
shares knowledge and leverage expert volunteers. COBIT continually evolves and maintained by
reputable, not for profit
organization. It maps 100% onto COSO,
and strongly onto all primarily related
standards.
It is used for
audit planning and audit program development.
It is also used to validate current IT controls and assess and reduce IT
risks. It complements the COSO framework.
It is used as a framework for
improving IT, and to benchmark IT. It is also used as a foundation for IT Governance (Bannister, 2006).
Summary and Conclusion
This
discussion addressed various essential
topics related to Sarbanes-Oxley. The
discussion provides a brief history of the Controls Frameworks since 1929. COSO is not recommended to be used alone, as
it is not detailed enough for IT. ISO
17799 is not enough as it does not cover sound
data management, third-party processes,
IT delivery and support operations, audit and governance issues, software and
hardware development control and segregation of duties. Organizations should consult and agree on the framework with external auditors before implementing the program. Businesses should not select too many COBIT
control objectives and control practices.
Simplification is highly recommended.
The focus should be on Key IT Control deficiencies
that are high or are a critical risk such as change management issues, access
control and segregation of duties, and some data management issues like backups and storage. Organizations should include IT applications
such as SAP with the business process document because most of the business
controls are defined by the systems and
applications (Bannister, 2006).
Organizations are recommended
not to test too many applications and processes, but instead take a Risk & Business Impact Approach. Businesses should also use external
Pricewaterhouse-Coopers five-step process
of inventory spreadsheets, evaluation of the use and complexity, the determination
of the level of controls, the evaluation
of existing controls, and the development remediation. COSO and COBIT
frameworks should be used as benchmarks, as they do not provide answers or
specific controls, and should be tailored to meet the needs of the business.
Organizations should analyze the compliance tools and software as some of them are not matured yet. Accountabilities
for each business and IT process should be
assigned as Segregation of Duties is business
accountability but facilitated by IT (Bannister, 2006).
References
Abernathy, R., & McMillan, T.
(2016). CISSP Cert Guide: Pearson IT Certification.
Information
security plays a significant role in the context of information technology (IT)
governance. The critical decisions as
part of governance for the information security needs are in the areas of
information security strategy, policies, infrastructure, training, and
investments for tools. Cloud computing emerging technology provides a new
business model for accessing computing infrastructure on a virtualized,
scalable, and lower-cost basis. The
purpose of this discussion is to address the impact of cloud computing on
changing decisions related to information security governance.
Cloud Computing Technology
“Cloud computing and big data are conjoined” (Hashem
et al., 2015).
This statement can raise the question about the reason for such a
relationship. Big Data has been
characterized by what is often referred
to as a multi-V model such as variety, velocity, volume, veracity, and value (Assunção,
Calheiros, Bianchi, Netto, & Buyya, 2015). While variety represents the
data types, the velocity reflects the rate at which the data is produced and
processed (Assunção
et al., 2015).
The volume defines the amount of data, and the veracity reflects how
much the data can be trusted given the
reliability of its source. The value, on the other hand, represents the monetary worth which
organizations can derive from adopting Big Data computing. The characteristics of Big Data including the
explosive growth rate, challenges and issues came along (Jagadish
et al., 2014; Meeker & Hong, 2014; Misra, Sharma, Gulia, & Bana, 2014;
Nasser & Tariq, 2015; Zhou, Chawla, Jin, & Williams, 2014).
The growth rate is regarded to be a significant challenge for IT
researchers and practitioners to design appropriate systems that handle the
data effectively, and analyze it to extract relevant meaning for
decision-making (Kaisler,
Armour, Espinosa, & Money, 2013). Other challenges include data
storage, data management and data processing (Fernández et
al., 2014; Kaisler et al., 2013); Big Data variety, Big Data
integration and cleaning, Big Data reduction, Big Data query and indexing, and
Bid Data analysis and mining (Chen et al.,
2013).
Traditional systems could not face all these challenges of
BD. Cloud computing technology emerged to address these challenges of BD. Cloud
computing is regarded as the solution and
the answer to BD challenges and issues (Fernández et al., 2014). Organizations and businesses are under pressure to quickly adopt and implement
technologies such as cloud computing to address the challenges of the Big Data
storage, and processing demands (Hashem et al., 2015). Besides,
the increasing demand of the Big Data on networks, storage, and servers outsourcing the data to the cloud may seem to
be a practical and useful option and approach when dealing with Big Data (Katal, Wazid, & Goudar, 2013). During
the last two decades, this increasing demand for data storage and data security
has been growing at a fast pace (Gupta, 2015). Such a demand lead to the emerging cloud
computing technology (Gupta, 2015). Issues such as scalability of the Big Data has
also pointed towards the cloud computing technology, which can aggregate multiple disparate workloads with
varying performance goals into significant
clusters in the cloud (Katal et al., 2013).
Various studies provided a different definition to cloud computing. However, the National Institute of Standards
and Technology (NIST) proposed an official definition of cloud computing. NIST
defined cloud computing as “a model for enabling ubiquitous, convenient,
on-demand network access to a shared pool of configurable computing resources
(e.g., network, servers, storage, applications, and services) that can be
rapidly provisioned and released with minimal management effort or service
provider interaction” (page 2) (Mell & Grance, 2011).
Cloud computing technology offers various deployment models of
public cloud, private cloud, hybrid cloud, and
community cloud. The public cloud is the least secure cloud model (Puthal, Sahoo, Mishra, & Swain, 2015).
The private cloud has also been referred by (Armbrust et al., 2009) as internal datacenters, which are not available to the general
public. Community cloud supports the specific
community with particular concerns such
as security requirements, policy and compliance consideration, and mission (Yang & Tate, 2012; Zissis &
Lekkas, 2012). It also offers three major service models such as
Infrastructure-as-a-Service (IaaS), Software-as-a-Service (SaaS),
Platform-as-a-Service (PaaS) (Mell & Grance, 2011).
Cloud computing offers various benefits from technological benefits
such as data and storage, APIs, metering and tools, to economic benefits such
as pay per use, cost reduction and return on investment, to non-functional
benefits such as elasticity, reliability, and
availability (Chang, 2015).
Despite these benefits, and the increasing trend in the adoption of
cloud computing is still not widely used. Security
concerns related to virtualization, hardware, network, data, and service
providers act as significant obstacles in adopting cloud computing in IT
industry (Balasubramanian
& Mala, 2015; Kazim & Zhu, 2015).
The security and privacy concern has been one of the major obstacle
preventing the full adoption of the
technology (Shahzad,
2014).
(Purcell,
2014) have stated that “The advantages
of cloud computing are tempered by two
major concerns – security and loss of control.” The uncertainty about security
has lead executives to state that
security is their number one concern for deploying cloud computing (Hashizume,
Rosado, Fernández-medina, & Fernandez, 2013).
Cloud Computing Governance and Data Governance
The enforcement of regulatory laws such
as Health and Human Services Health Insurance Portability and Accountability
Act (HIPAA) and Sarbanes-Oxley becomes an issue especially when adopting cloud
computing (Ali, Khan, & Vasilakos, 2015). Cloud computing fosters
security concerns that hamper the fast rate adoption of the cloud computing.
Thus, cloud governance and data governance are highly recommended when adopting
cloud computing.
Cloud governance is defined as the control and processes that make sure policies are enforced (Saidah & Abdelbaki, 2014). It is a framework applied
to all related parties and the business
process securely to ensure that the cloud
supports the goal of the organization and comply with all required regulations
and rules. Cloud governance model should be
aligned with the corporate governance
and IT governance. It has to comply with
the strategy of the organization to accomplish the business goals. Various studies proposed various cloud
governance models.
(Saidah & Abdelbaki, 2014) proposed a cloud governance model that provides three models; policy model, operational model, and management model. The policy model invovle data policy, service policy, business process management policy and exit policy. The operational model include authentication, authorization, audit, monitoring, adaptations, medata repository, and asset management. The management model includes policy management, security management, and service management. Figure 1 illustrates the proposed cloud governance model.
Figure 1. The Proposed Cloud Governance
Model (Saidah & Abdelbaki, 2014).
(Rebollo, Mellado, &
Fernández-Medina, 2013) proposed a security governance framework for cloud computing
environment (ISGcloud). The proposed governance framework is founded upon two
main standards. It implements the core governance principles of the ISO/IEC
38500 governance standard. The framework proposed a cloud service lifecycle
based on the ISO/IEC 27036 outsourcing security draft.
When organizations decide to adopt the
cloud computing technology, careful considerations must be made toward the
deployment model as well as to the service model to understand the security
requirements and the governance strategies (Al-Ruithe, Benkhelifa, &
Hameed, 2016).
Data governance for cloud computing is not nice to have but is required by rules and regulations to protect
the privacy of the users and employees.
The loss of control on the data is the
most significant issue when adopting cloud computing
because the data is stored on a computer
belonging to the cloud provider. This loss of governance and control could have
a potentially severe impact on the
strategy of the organization, and the capacity to meet its mission and goals (Al-Ruithe et al., 2016). The loss of control and
governance of the data can lead to the impossibility of complying with security
requirements, a lack of confidentiality, integrity, and availability of data, and a deterioration of performance and
quality of services, not to mention the introduction of compliance challenges.
Thus, organizations must be aware of the best practice for safeguarding,
governing and operating data when adopting cloud computing technology. NIST offers many recommendations when
adopting cloud computing technology (Al-Ruithe et al., 2016). The organization should
consider data governance strategy before adopting cloud computing. This
recommendation demonstrates the importance of data governance for organizations
which intend to move their data and services to cloud computing environment as
policies, rules, and distribution of
responsibilities between cloud actors will have to be set. The development of
policies and data governance will assist organizations in monitoring compliance with the current regulations and
rules. The primary benefit of data governance when using cloud environment is
to ensure security measures, privacy protection and quality of data.
The implementation of data governance for
cloud computing changes based on the roles and responsibilities in the internal
process of the organization (Al-Ruithe et al., 2016). Thus, organizations are
expected to face many issues. The lack
of understanding of data governance is
one of the major issues. The lack of
training and lack of communication plan are additional issues which
organizations will face. The lack of support is another obstacle which includes
lack of top management support, lack of compliance enforcement and lack of
cloud regulation. Lack of policies, process and defined roles in the organization are one of the main obstacles to implement data governance in the cloud. The lack of resources including lack of
funding, technology, people, and skills is considered another data governance
obstacle.
Conclusion
This discussion addressed cloud computing
technology and its relationship with BD and BDA. Cloud computing technology
emerged as a solution to the challenges that BD and BDA faced. However, cloud
computing is confronted with security and
privacy challenges. Executives expressed
security as the number one concern for cloud computing adoption. The governance of cloud computing will
provide a secure environment to protect data
from loss or malicious attacks. Organizations are required to comply with the
various security and privacy regulations and rules. Organizations under pressure for data
protection especially when using cloud
computing technology. Thus, they are
required to implement the data governance and cloud computing governance
framework to ensure such compliance.
References
Al-Ruithe, M.,
Benkhelifa, E., & Hameed, K. (2016). A Conceptual Framework for Designing
Data Governance for Cloud Computing. Procedia
Computer Science, 94, 160-167. doi:10.1016/j.procs.2016.08.025
Ali, M., Khan, S.
U., & Vasilakos, A. V. (2015). Security in cloud computing: Opportunities
and challenges. Information Sciences, 305,
357-383. doi:10.1016/j.ins.2015.01.025
Armbrust, M.,
Fox, A., Griffith, R., Joseph, A. D., Katz, R. H., Konwinski, A., . . . Stoica,
I. (2009). Above The Clouds: A Berkeley View of Cloud Computing. Electrical Engineering and Computer Sciences
University of California at Berkeley.
Assunção, M. D.,
Calheiros, R. N., Bianchi, S., Netto, M. A. S., & Buyya, R. (2015). Big
Data Computing and Clouds: Trends and Future Directions. Journal of Parallel and Distributed Computing, 79, 3-15.
doi:10.1016/j.jpdc.2014.08.003
Balasubramanian,
V., & Mala, T. (2015). A Review On Various Data Security Issues In Cloud
Computing Environment And Its Solutions. Journal
of Engineering and Applied Sciences, 10(2).
Chang, V. (2015).
A Proposed Framework for Cloud Computing Adoption. International Journal of Organizational and Collective Intelligence, 6(3).
Chen, J., Chen,
Y., Du, X., Li, C., Lu, J., Zhao, S., & Zhou, X. (2013). Big Data
Challenge: a Data Management Perspective. Frontiers
of Computer Science, 7(2), 157-164. doi:10.1007/s11704-013-3903-7
Fernández, A.,
Del Río, S., López, V., Bawakid, A., del Jesus, M. J., Benítez, J. M., &
Herrera, F. (2014). Big Data with Cloud Computing: An Insight on the Computing
Environment, MapReduce, and Programming Frameworks. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 4(5),
380-409. doi:10.1002/widm.1134
Gupta, U. (2015).
Survey on Security Issues in File Management in Cloud Computing Environment. Department of Computer Science and
Information Systems, Birla Institute of Technology and Science, Pilani.
Hashem, I. A. T.,
Yaqoob, I., Anuar, N. B., Mokhtar, S., Gani, A., & Khan, S. U. (2015). The
Rise of “Big Data” on Cloud Computing: Review and Open Research Issues. Information Systems, 47, 98-115.
doi:10.1016/j.is.2014.07.006
Hashizume, K.,
Rosado, D. G., Fernández-medina, E., & Fernandez, E. B. (2013). An analysis
of security issues for cloud computing. Journal
of internet services and applications, 4(1), 1-13.
doi:10.1186/1869-0238-4-5
Jagadish, H. V.,
Gehrke, J., Labrinidis, A., Papakonstantinou, Y., Patel, J. M., Ramakrishnan,
R., & Shahabi, C. (2014). Big Data and Its Technical Challenges. Communications of the Association for
Computing Machinery, 57(7), 86-94. doi:10.1145/2611567
Kaisler, S.,
Armour, F., Espinosa, J. A., & Money, W. (2013). Big Data: Issues and Challenges Moving Forward. Paper presented at
the Hawaii International Conference on System Sciences
Katal, A., Wazid,
M., & Goudar, R. H. (2013). Big Data:
Issues, Challenges, Tools and Good Practices. Paper presented at the
International Conference on Contemporary Computing.
Kazim, M., &
Zhu, S. Y. (2015). A Survey on Top Security Threats in Cloud Computing. International Journal Advanced Computer
Science and Application, 6(3), 109-113.
Meeker, W., &
Hong, Y. (2014). Reliability Meets Big Data: Opportunities and Challenges. Quality Engineering, 26(1), 102-116.
doi:10.1080/08982112.2014.846119
Mell, P., &
Grance, T. (2011). The NIST Definition of Cloud Computing. National Institute of Standards and Technology (NIST), 800-145,
1-7.
Misra, A., Sharma,
A., Gulia, P., & Bana, A. (2014). Big Data: Challenges and Opportunities. International Journal of Innovative
Technology and Exploring Engineering, 4(2).
Nasser, T., &
Tariq, R. S. (2015). Big Data Challenges. Journal
of Computer Engineering & Information Technology, 9307, 1-10.
doi:10.4172/2324
Purcell, B. M.
(2014). Big Data Using Cloud Computing. Journal
of Technology Research, 5, 1-9.
Puthal, D.,
Sahoo, B., Mishra, S., & Swain, S. (2015). Cloud Computing Features, Issues, and Challenges: a Big Picture.
Paper presented at the Computational Intelligence and Networks (CINE), 2015
International Conference on Computational Intelligence & Networks.
Rebollo, O.,
Mellado, D., & Fernández-Medina, E. (2013). Introducing a security governance framework for cloud computing.
Paper presented at the Proceedings of the 10th International Workshop on
Security in Information Systems (WOSIS), Angers, France.
Saidah, A. S.,
& Abdelbaki, N. (2014). A New Cloud
Computing Governance Framework.
Shahzad, F.
(2014). State-of-the-art Survey on Cloud Computing Security Challenges,
Approaches and Solutions. Procedia
Computer Science, 37, 357-362. doi:10.1016/j.procs.2014.08.053
Yang, H., &
Tate, M. (2012). A Descriptive Literature Review and Classification of Cloud
Computing Research. Communications of the
Association for Information Systems, 31(2), 35-60.
Zhou, Z., Chawla,
N., Jin, Y., & Williams, G. (2014). Big Data Opportunities and Challenges:
Discussions from Data Analytics Perspectives. Institute of Electrical and Electronic Engineers: Computational
Intelligence Magazine, 9(4), 62-74.
Zissis,
D., & Lekkas, D. (2012). Is Cloud Computing Finally Beginning to Mature? International Journal of Cloud Computing and
Services Science, 1(4), 172. doi:10.11591/closer.v1i4.1248
The purpose of this project is to discuss Zachman Enterprise Architecture which is also known as the Zachman Framework. Zachman introduced the concept of architecture in 1987 and compared the framework to the construction architecture which requires components, builders, time frame and so forth. The framework is not a methodological but a logical framework. It is a two-dimensional framework. The framework is not a security-based framework. However, it allows analysis of enterprise to be presented to different groups in the enterprise in ways that relate to the responsibilities of the groups. A few architectures expanded since the inception of Zachman’s Framework. This project discussed a few of them such as TOGAF, DoDAF, MODAF, SABSA, and CobiT. In brief, the concept of architecture did not exist until the Zachman’s initiative. The architecture concept was limited to building and construction in the Industrial Age. However, in the Information Age, Zachman was inspired to develop an information system architecture and framework for Enterprise. The application of the architecture concept to the enterprise information system was an innovative idea from Zachman that deserves recognition.
This project
discusses the enterprise framework which is developed by Zachman. As indicated in (Zachman,
1987), information system architecture was not significant thirty
years ago from the time Zachman started to develop the framework in 1987. Zachman was inspired to develop such a
framework and architecture for the enterprise
information system. This project begins
with Zachman Enterprise Architecture, followed by additional frameworks and
architectures that appeared and expanded since the inception of Zachman
Framework.
In 1987, John A. Zachman published
a unique approach to the elements of the information system. Zachman is often
mentioned in the literature as the primary
contributor to enterprise architecture. Zachman
(1987) presented a comparison between project design and the implementation
using the classical engineering and building constructions, roads, and bridges (Zachman, 1987). The construction begins with requirements and
then the structure to implement these requirements is designed. Before starting the implementation of a
project that is based on stakeholders’
requirement, the design to implement such a project must be developed (Zachman, 1987). Zachman provided a comparison using a generic
set of architectural representations produced during the process of
constructing a building, including concepts, work breakdown structure,
engineering design, manufacturing engineering, and assembly and fabrication
drawings.
The framework for enterprise architecture or as it is called Zachman Framework is a logical structure for classifying and organizing the descriptive representations of the enterprise which are significant to the management and the development of the systems of the enterprise including manual and automated systems (Zachman, 1997). The generic classification structure of the design artifacts involves questions of what, how, where, who, when and why with various players planner, owner, design, builder, implementer, and operator. The artifacts involve scope, concepts, logic, physics, technology, and product. It also includes material, process, geometry, instructions, timing, and objectives. Figure 1 shows the generic classification structure of Zachman’s Design Artifacts. Figure 2 shows the populated framework.
Figure 1. Generic Classification Structure of Design Artifacts (Zachman, 1997).
Figure 2. The Populated Zachman’s
Framework for Enterprise Architecture (Zachman, 1997).
Zachman’s
Framework is a generic classification scheme for design artifacts, which is detailed
representations of a complex object. The utility of such a scheme is to enable
focused concentration on selected aspects of an object without losing a sense
of the contextual or holistic perspective (Zachman, 1997). The
framework is logical with five
perspectives Owner, Designer, Builder,
bounded by Scope or Strategist and Detail
or Implementer in addition to the instantiation. Six abstractions of What for things, How for the
process, Where for location, Who for
responsibility, When for timing, and Why for motivation. The framework is comprehensive as it
addresses the enterprise as a whole. The framework does not require technical
professionals. The framework serves as a
planning tool to make better choices by positioning issues in the context of
the enterprise and view various alternatives.
It also serves as a problem-solving tool to enable enterprise work with
abstractions to simplify, isolate simple and single variables without losing the
sense of the complexity of the enterprise
as a whole. Zachman’s framework is
described as a neutral as it is defined independently of tools or methodologies
and therefore any tool or any methodology can be mapped against it. It is also
described as a raw material for enterprise engineering (Zachman, 1997).
Zachman’s
Framework is the basis for architecture (Zachman, 2008). During
the industrial age, the industrial products were increasing in complexity and
products that are changing. However, in
the age of information system, the enterprise
is increasing in complexity and is changing continuously. Zachman suggested that enterprise
architecture is the determinant factor of survival in the Information Age (Zachman, 2008). Thus,
the Framework for Enterprise Architecture which is also called the Zachman Framework has profound significance in
placing definitions around Enterprise Architecture, the survival issue of the
century. It is not a methodology but
rather an ontology and a theory of the existence of a structured set of
essential components of an object for which explicit expressions is required
and probably mandatory for creating, operating and changing the object (Zachman, 2008).
Zachman’s
Framework is also described as a
two-dimensional classification system
based on six communication questions of What, Where, When, Why, Who and How as
discussed above, which intersect with different views of Planner, Owner, Designer, Builder, Subcontractor, and
Actual System (Abernathy & McMillan, 2016). The system allows the analysis of an
organization to be presented to different
groups in the organization in ways that relate to the groups’ responsibilities. The enterprise architecture
framework is not security oriented. However, it helps organizations relay
information for personnel in a language and format that is most useful to
them. Since the inception of Zachman’s
enterprise architecture, a few architectures were
developed. The next section will
address some of these architectures.
Architectures Expansion
Since the
inception of Zachman’s Enterprise Architecture, a few architectures have been expanded along with the technology
growth. Organizations should choose the
enterprise architecture framework that represents
the organization in the most useful manner, based on the needs of the
stakeholders. This section discusses
some of these architectures that expanded since Zachman’s Framework.
The Open Group Architecture Framework (TOGAF) is another
enterprise architecture framework that aids organization design, plan,
implement and govern enterprise
information architecture (Abernathy & McMillan, 2016). TOGAF is based on four inter-related domains:
technology, applications, data, and
business.
The
Department of Defense Architecture Framework (DoDAF) is another architecture
framework that organizes a set of products under eight views starting with “All
viewpoint” (AV) for required, capability viewpoint (CV), data and information
viewpoint (DIV), operation viewpoint (OV), project viewpoint (PV), services
viewpoint (SvcV), standards viewpoint (STDV), and system viewpoint (SV). This framework is used to ensure that new
Department of Defense (DoD) techn9ologies integrate correctly with the current infrastructures (Abernathy & McMillan, 2016).
The
British Ministry of Defence Architecture Framework (MODAF) is another
architecture framework that divides information into seven viewpoints starting
with strategic viewpoint (StV), operational viewpoint (OV), service-oriented
viewpoint (SOV), systems viewpoints (SV), acquisition viewpoint (AcV), technical viewpoint (TV), and all
viewpoint (AV) (Abernathy & McMillan, 2016).
Sherwood Applied Business Security Architecture (SABSA) is an enterprise security architecture framework which is similar to Zachman’s Framework (Abernathy & McMillan, 2016). It uses six communication questions of What, Where, When, Why, Who and How which intersect with six players of Operational, Component, Physical, Logical, Conceptual and Contextual. It is described to be a risk-driven architecture (Abernathy & McMillan, 2016). Table 1 shows the SABSA Framework Matrix.
Control Objectives
for Information and Related Technology (CobiT) is a security control development
framework that documents five principles.
The first principle is about meeting stakeholder needs while covering the enterprise end-to-end is the second
principle. The application of a single integrated framework is the third principle,
following by enabling a holistic approach and separating governance from
management principle. These five principles drive control objectives
categorized into seven enablers starting with principles, policies, and
framework, followed by processes, organizational structures. Culture, ethics,
and behavior is the fourth enabler, followed by the information. Services,
infrastructure, and application is another enabler, followed by the last
enabler of people, skills and competencies.
Conclusion
This project
discussed Zachman Enterprise Architecture which is also known as the Zachman Framework. Zachman introduced the concept of
architecture in 1987 and compared the framework to the construction
architecture which requires components, builders, time frame and so forth. The framework is not a methodological but a
logical framework. It is a two-dimensional framework. The framework is not a security-based framework. However, it allows analysis of enterprise to be presented to different groups in the
enterprise in ways that relate to the
responsibilities of the groups. A few
architectures expanded since the inception of Zachman’s Framework. This project
discussed a few of them such as TOGAF,
DoDAF, MODAF, SABSA, and CobiT. In brief, the concept of architecture did not
exist until the Zachman’s initiative. The
architecture concept was limited to the construction in the Industrial Age.
However, in the Information Age, Zachman was inspired to develop an information system architecture and framework for
Enterprise. The application of architecture
concept to the enterprise information system was an innovative idea from Zachman that deserves recognition.
References
Abernathy, R., & McMillan, T.
(2016). CISSP Cert Guide: Pearson IT
Certification.
Zachman,
J. A. (1987). A framework for information systems architecture. IBM Systems Journal
The purpose of this discussion is to
write a research position on some of the most significant challenges facing
information technology (IT) today. The
focus is on the top 5 issues that are considered the most important from the
researcher’s point of view. These
challenges can be a strategy, budget,
pace, scope, architectures, mergers or acquisitions, technologies, devices,
skills, and chief information officer
(CIO) role.
Challenges Facing Information Technology Department
Various reports and studies discussed various
challenges that the information technology (IT) department is facing (Brooks,
2014; Global Knowledge, 2018; Heibutzki, 2018). The top five
challenges that are chosen for this
discussion include budget, pace, security, strategy and skills.
Budget: Business requires an allotment of the budget not only to keep up with the technology
but also to keep up with the regulations (Heltzel, 2018). Small and medium-size businesses are confronted with more budget challenges than large
organizations. Understanding the business capabilities and the use of the
information technology can help understand the budget requirements. The budget requirements involve every
department of the business, as it is all-encompassing. If the budget is limited, the business will
be limited and can be dragged behind while the wheel of technology is still
moving on an unprecedented pace, and
other competitors are gaining more advantages in the market. Thus, careful examination of the financial
resources must be performed by an organization
to act as fast as other competitors.
Technology Pace: The next challenge that
is facing the IT department is the pace
of the technology. In the age of the digital
world, the data generation is increasing at
a fast pace. McKinsey Global Institute
indicates that Big data is the next frontier for innovation, competition, and productivity (Manyika et al., 2011). The
application of Big Data (BD) and Big Data Analytics (BDA) will become a fundamental basis for competition and growth
from businesses. Organizations can gain competitive advantages when using BD
and BDA. The emerging technology of
cloud computing, internet of things, the blockchain,
quantum computing and so forth place pressure on business to consider the
latest technology to stay in business.
Security: Security is the third
major challenge that is facing the IT
department. Security comes with various
regulations and rules. Some security
regulations and rules are broadly applicable, while other are industry specific
(CSO, 2012). Sarbanes-Oxley Act (SOX) is an example of the
broadly applicable security law and regulations, while the Health Insurance Portability and Accountability
Act (HIPAA) is an example of the industry-specific guidelines and requirements.
IT department should not only keep up
with these regulations but also fully
comply with them to protect users private information and avoid penalties.
Strategy: One of the challenges that face IT is the strategy that encompasses all the requirement of the business
in a governance framework. IT strategy
is not a nice to have, but it is required for sound organizational
performance (Arefin, Hoque, & Bao, 2015). It should be aligned
with the business strategy. The strategy should involve various aspects of the
business from storing the data to
customer relationship management systems, to analyzing data. Strategic IT is a comprehensive plan which
outlines how technology should be used to meet IT and business goals. It is driven
by the mission statement and mission objectives of the business. The IT strategy affects the budget of the business as it will require some
investments in technology, devices, tools, and workforces.
Skills: In the age of the digital world and the era of BD and BDA, the IT department is
challenged with hiring the professionals who have the skills to work
with the latest technology. Skills for
traditional systems such as data warehouse, or relational database are not the
challenge, but the skills for the new technologies such as machine learning
algorithms, analytical skills, cloud computing, the blockchain, and quantum
computing, all of which require skills that are lacking in the professional
market. While organizations are under
pressure to apply BD and BDA, statistics show
that 37% shortage of skilled professionals
(McCafferly, 2015), which is an example of the shortage of the skills
that add additional burden on the IT.
Conclusion
This discussion addressed five significant challenges that are facing the
information technology. The budget constraint in the presence of fast
technology pace is the first challenge
while keeping up with the emerging technologies in the age of the digital world is another challenge. IT
department is required to comply with all of the security regulations and rules. Otherwise, heavy
penalties can add more constraints on the budget. The strategic IT is mandatory and should be aligned
with the business goals and objectives. The skilled workforce is another
challenge as technology is evolving and developing the required skills require
time which organizations cannot afford in the age of fast pace evolving
technologies.
References
Arefin, M. S., Hoque, M. R., &
Bao, Y. (2015). The impact of business intelligence on organization’s
effectiveness: an empirical study. Journal
of Systems and Information Technology, 17(3), 263-285.
Brooks, C.
(2014). The 5 Big Challenges Facing IT Departments.
CSO. (2012). The
security laws, regulations and guidelines directory.
Manyika, J.,
Chui, M., Brown, B., Bughin, J., Dobbs, R., Roxburgh, C., & Byers, A. H.
(2011). Big Data: The Next Frontier for Innovation, Competition, and Productivity.
McKinsey Global Institute.
Customers are the source of all
revenue. Understanding, delighting, and retaining customers over time requires
carefully managing a relationship with them. Research articles on customer
relationship management (CRM). Regarding
technology, there has been an explosion in CRM platforms with a few established
players and many niche players.
The purpose of this discussion is to address significant topics regarding CRM. It begins with CRM systems and rationale for using them, followed by challenges and costs. The discussion also covers the building blocks of CRM systems and Their Integration, followed by the best practices in implementing the CRM systems.
CRM Systems and Rationale for Using Them
CRM systems assist organizations to manage customer
interaction and customer data, automate marketing, sales, and customer support, assess business
information and managing partner, vendor,
and employee relationships. A quality
CRM system can be scalable to serve the needs of small, medium or large
business (Financesonline, 2018). CRM systems
can be customized to allow business is
taking actionable customer insights using back-end analytics, identify
opportunities with predictive analytics, personalize customer support, and
streamline operations based on the history of the customers’ interaction with
the business. Organizations must be
aware of the CRM system software available to select the most appropriate CRM
system that can better serve their needs.
Various reports identified various CRM systems. The best CRM systems include Salesforce CRM,
Hubspot CRM, Fresh sales, Pipedrive,
Insightly, Zoho CRM, Nimble, PipelineDeals, Nutshell CRM, Microsoft Dynamics
CRM, SalesforceIQ, Spiro, and ExxpertApps. Table 1 shows the best CRM systems available
in the market.
Table 1. CRM Systems (Financesonline, 2018).
Customer satisfaction is the critical element to the success of the business (Bygstad, 2003; Pearlson & Saunders, 2001). Businesses
need to continuously satisfy customers, understand their needs and
expectations, provide high-quality products or service at a competitive price
to maintain success. These interactions needed to be tracked by the business and
analyzed in an organized way to foster long-lasting customer relationships
which get transformed into long-term
success.
CRM can aid business increase sales efficiency, drive
the satisfaction of customers, streamline the process of the business and make it
more efficient, and identify and resolve
bottlenecks at any of the operational processes
from marketing, sales to the product development (Ahearne, Rapp, Mariadoss, & Ganesan, 2012; Bygstad, 2003). The
development of customer relationship is not a trivial
or straightforward task. When it is done
right, it places the business in a competitive edge. However, the
implementation of CRM is challenging.
Challenges and Costs
The implementation of CRM demonstrates the value of
customers to the business and placing
customer service on top priority (Pearlson & Saunders, 2001). CRM plays a
significant role in collaborating the effort between customer service,
marketing, and sales in an
organization. However, the
implementation of CRM is challenging especially for small business and
startups.
Various reports addressed various challenges when
implementing CRM. The cost is the most significant challenges organizations are confronted with when implementing the CRM solution (Sage Software, 2015). The
development of a clear objective to achieve with the CRM system is another
challenge when implementing CRM.
Organizations are confronted with the type of deployment whether it
should be on-premise or cloud-based CRM.
Other challenges involve the employees’ training, the right CRM solution
provider and the integration plan in advance (Sage Software, 2015).
The cost of CRM systems varies from one vendor to
another based on the features and deployment key such as data importing,
analytics, email integrations, mobile accessibility, email marketing,
multi-channel support, SaaS platform, on-premise platform, and SaaS and
on-premise. Some vendors offer CRM for
small and medium, or small only, while others offer CRM systems for small,
medium and large businesses. In a report
by (Business-Software, 2019), the cost is
categorized for more expensive to least expensive using the dollar sign
as $$$$ for most expensive, $$$ for expensive, $$ for less expensive and $ for
least expensive. Each vendor CRM system
has certain features which must be examined by organizations before making the decision to adopt such a
system. Table 2 provides an idea about
the cost from the most expensive,
expensive, less expensive, to least expensive.
Table 2. CRM System Costs based on the Report by (Business-Software, 2019).
The Building Blocks of CRM Systems and Their Integration
Understanding the buildings blocks of the CRM system
can assist in the implementation and integration of CRM systems. CRM involves four core building blocks (Meyer & Kolbe, 2005). The acquirement and continuous update of the
knowledge base on the needs of customers, motivations, and behavior over the lifetime of the relationship with
customers. The application of the
customers’ knowledge to continuously improve performance through a process of
learning from success and failures is the second building block of CRM
system. The integration of marketing,
sales, and service activities to achieve a common goal is another building
block of the CRM system. The last
building block of the CRM system involves
the implementation of appropriate systems to support customer knowledge
acquisition, sharing, and the measurement of CRM effectiveness.
CRM integration is a critical building block for CRM
success (Meyer, 2005). The process of integrating CRM involves various organizational and operational
functions of the business such as marketing, sales and service activities. CRM requires detailed business processes
which can be categorized into three core
elements; CRM delivery process, CRM support process, and CRM analysis
process. The delivery process involves
direct contact with customers to cover part of the customer process such as
campaign management, sales management, service management, and complaint
management. The support process involves direct contact with the customer that are not designed to fulfill
supporting functions within the CRM context such as market research and loyalty
management. The analysis process
consolidates and analyzes the knowledge
of customers collected in other CRM processes.
The result of this analysis process is passed to the delivery process,
support process and to the service innovation and service production processes
to enhance their effectiveness such as customer scoring and lead management,
customer profiling and segmentation, feedback and knowledge management.
Best Practices in Implementing These CRM Systems
Various studies and reports addressed best practices
in the implementation and integration of CRM systems into the business (Salesforce, 2018; Schiff, 2018).
Organizations must choose a CRM that fits their needs. Not every CRM is
created equally, and if organizations choose a CRM system without
properly researching its features, capabilities, and weaknesses, organizations could
end up committed to a system that is not appropriate for the business, and as a
result, could lose money. Organizations should decide whether CRM
should be cloud-based or on-premise base
CRM (Salesforce, 2018; Schiff, 2018; Wailgum, 2008). Organizations should decide whether CRM should
be a service contract or one that costs
more upfront to install. Business should
also decide whether it needs in-depth, highly customizable features, or basic
functionality will be sufficient to serve the needs of the business. Organizations should analyze the options and
decide on the CRM system that is most appropriate for the business which can
serve the needs to build strong customer relationship and gain a competitive edge in the market.
Well-trained personnel and workforce will help
organizations achieve its strategic CRM goal. If organizations do not invest in the training of the workforce on how to
utilize the CRM system, CRM tools will become
useless. The CRM systems become
effective as organizations allow them to be. When the workforce is not using
the CRM system to its full potentials, or if the workforce is misusing the CRM systems, CRM will not
perform its functions properly and will not serve the needs of the business as
expected (Salesforce, 2018; Schiff, 2018).
Automation is another critical
factor for best practice when implementing CRM systems. Tasks that are
associated with data entry can be automated so that CRM systems will be
up to date. The automation will increase
the efficiency of the CRM systems as well as the business overall (Salesforce, 2018; Schiff, 2018).
One of the significant
benefits of CRM is its potential in improving and enhancing the cooperative
efforts across departments of the business.
When the same information is accessible across various departments, CRM
systems eliminate confusions that can be caused
by using different terms and different
information. Data without analysis is
not meaningless. Organizations should
consider mining the data to get the value
that can aid in making sound business decisions. CRM systems are designed to capture and
organize massive amounts of data. If
organizations do not take advantages of this massive amount of data to turn it
into actionable data, the implementation of CRM will be so limited. The
best CRM systems are those that come with built-in analytics features which use
advanced programming to mine all captured data and use that information to
produce valuable conclusions which can be used
for future business decisions. When
organizations take advantages of the CRM built-in analytical feature and analyze the data that CRM system procures,
the valuable information can provide insight for business decisions (Salesforce, 2018).
The last element for best practice of the
implementation of CRM is for organizations to keep it simple. The best CRM
system is the one that will best fit the needs and requirements of the
business. The simplicity is a crucial
element when implementing CRM.
Organizations should implement CRM that is not complex while it is useful and provides everything the business
needs. Organizations should also
consider making changes to the CRM policies where necessary. The effectiveness of day-to-day operations will
be the best indicator of whether the CRM performs as expected, and if it is
not, some changes must be made until it
performs as expected (Salesforce, 2018; Wailgum, 2008).
Conclusion
This discussion addressed major topics about CRM
systems. It began with the identification of the best CRM system in the market
and the justification for businesses to implement CRM systems. It also discusses the benefits and advantages
of CRM systems which place businesses into a competitive edge by building a strong relationship with customers to meet
customers’ need consistently. The
implementation of a CRM system is not
trivial and requires primary
considerations from organizations. Business
is confronted with various challenges
when implementing CRM systems, among which is the cost. Thus, organizations should consider analyzing
every CRM system vendor to ensure the CRM system will be the best fit for the
business needs with a return on investment. The discussion also addressed
various best practices among which the workforce
is training as a critical factor
for successful CRM program, and the simplicity of CRM systems so that
organizations can fully utilize the potential of the systems for the benefit of
the business to make a sound business
decision.
References
Ahearne, M., Rapp, A., Mariadoss, B.
J., & Ganesan, S. (2012). Challenges of CRM implementation in
business-to-business markets: A contingency perspective. Journal of Personal Selling & Sales Management, 32(1), 117-129.
Business-Software.
(2019). Top 40 CRM Software Report.
Bygstad, B.
(2003). The implementation puzzle of CRM systems in knowledge-based
organizations. Information Resources
Management Journal (IRMJ), 16(4), 33-45.
Meyer, M. (2005).
Multidisciplinarity of CRM Integration
and its Implications. Paper presented at the System Sciences, 2005.
HICSS’05. Proceedings of the 38th Annual Hawaii International Conference on.
Meyer, M., &
Kolbe, L. M. (2005). Integration of customer relationship management: status
quo and implications for research and practice. Journal of strategic marketing, 13(3), 175-198.
Pearlson, K.,
& Saunders, C. (2001). Managing and Using Information Systems: A Strategic
Approach. 2001: USA: John Wiley & Sons.
Sage Software.
(2015). Top Challenges in CRM Implementation.
The purpose of this project is to discuss customer relationship management (CRM) based on the identified article by (Payne & Frow, 2005). The lack of the precise definition and lack of clear framework directed the authors to develop a generic technology-based definition for CRM that has been acceptable by some practitioners. The authors proposed a strategic CRM conceptual framework that is based on five essential processes. It begins with the strategy development process, followed by the value creation process, multi-channel integration process, information management process, and performance assessment process. Each process plays a significant role in the proposed strategic process-based CRM framework. This article can aid organizations which are confused about CRM definition and framework. It can help them implement the building blocks of the CRM strategy based on this proposed framework.
This project
discusses customer relationship management (CRM) using the identified article
by (Payne & Frow, 2005). The project begins with the inception and
various definitions of CRM, followed by the CRM adoption problems. The discussion covered the proposed technology-based definition for CRM based on
various literature reviews and proposed strategic process-based CRM conceptual
framework by the authors.
The term CRM emerged in the mid-1990s in information technology IT vendor community and practitioner community. The term CRM is often used to describe technology-based customer solutions such as sales force automation (SFA). The term CRM and relationship marketing (RM) are used interchangeably in the academic community.
(Payne &
Frow, 2005) identified twelve
definitions for customer relationship management (CRM). These definitions
describe the meaning and interpretation
of CRM from the various aspects. This project will address only few that are
worth mentioning. CRM is defined as an enterprise initiative that
belongs in all area of an organization.
It is also defined as a
comprehensive strategy and process of acquiring, retaining, and partnering with
selective customers to create superior value for the company and the
customer. CRM is an attempt to provide a
strategic bridge between information technology and marketing strategies aimed
at developing long-term relationships and profitability, which require
information-intensive strategies. CRM is
data-driven marketing. CRM is making
business more customer-centric, using web-based tools and internet
presence. In brief, CRM is all about
customers and how organizations can deal with its customers to ensure providing
a good product, excellent customer service, with more savings. Amazon is an
excellent example of being customer-centric. “We see our customers as invited guests to a party, and we are the
hosts. It’s our job every day to make
every important aspect of the customer experience a little bit better” Jeff
Bezos (Expert
Market, n.d.).
Many organizations are confronted with the adoption of CRM due to the ambiguous view
of CRM in business. CRM meant to some
business as direct mail, a loyal card scheme, or a database, while others
envisioned CRM as a help desk or a call center, or a data warehouse for data
mining. Other businesses considered CRM
as an e-commerce solution such as personalization engine on the internet. The lack of the standard definition of CRM
can contribute to the failure of a CRM project when organizations view CRM from
a limited technology perspective or implementing CRM on a fragmented basis. The lack of a strategic
framework for CRM from which to define success is another reason for the
disappointing results of many CRM initiatives.
As a result of the lack of official definition for CRM, the authors developed the following definition for CRM that is based on technology for the purpose of their study. This technology-based definition provides directions for the strategic and cross-functional emphasis of their proposed conceptual framework.
“CRM is a strategic approach that is concerned with creating improved shareholder value through the development of appropriate relationships with key customers and customer segments. CRM unites the potential of relationship marketing strategies and IT to create profitable, long-term relationships with customers and other key stakeholders. CRM provides enhanced opportunities to use data and information to both understand customers and cocreate [sic] value with them. This requires a cross-functional integration of processes, people, operations, and marketing capabilities that are enabled through information, technology, and applications.”
The authors proposed a conceptual framework
that is based on five CRM processes; the strategy development process, the value creation
process, the multi-channel integration process, the information management
process, and the performance assessment process. The proposed conceptual framework provides an
illustration of the interactive set of strategic processes that begins with the
strategy development process reflecting a detailed review of the strategy of
the business and concludes with the performance assessment process reflecting
the improvement in the results and increased share value. Figure 1 shows the CRM proposed conceptual
framework.
The first layer of the proposed framework
requires a dual focus on the business strategy and its customer strategy. The business strategy should first be
considered to determine the strategy of the customer. It begins with a review or articulation of
the vision of the business, especially as it related to CRM. The customer strategy is the responsibility
of the chief executive officer (CEO), the board, and the strategy director. It is also the responsibility of the marketing department. It involves examining the
existing and potential customer base and identifying the most appropriate
customer segmentation. To summarize, the
strategy development process involves a detailed evaluation of the business
strategy and the development of the appropriate customer strategy, providing a
concise non-ambiguous platform based on which CRM activities will be developed.
The second process of the proposed conceptual framework is about the
value creation. The value creation
process shifts the outputs of the strategy development process into programs
which extract and deliver value. It involves three key elements; determining the value which the company can
provide to its customer, determining the value which the company can receive from its customers, and managing this
value exchange. The first key element of the value the company can provide to
customers draws on the concept of the benefits that enhance the customer
offer. Businesses should implement a
value assessment to quantify the relative importance that customers place on
the various characteristics of a product.
Analytical tools can also discover significant market segments with
service needs which are not entirely
offered to the customer by the
characteristics of existing products. The second key element of this process involves the value to organizations and the lifetime
value. The retention of the customer is a crucial
value to the organization. It reflects a significant part of the
research on value creation.
The third process involves multi-channel
integration. This process is one of the
most critical processes in CRM because it
takes the output of the first two processes of the business strategy and the
value creation process and translates them into value-adding activities with
customers. This process of multi-channel
integration involves channel options and
integrated channel management. The channel options involve sales force,
outlets, telephony, direct marketing, e-commerce, m-commerce. The integrated channel management depends on
the ability to uphold the same high standards across multiple, different
channels. The multi-channel integration
process is a critical process in CRM
because it represents the point of co-creation of customer value. However, the success of this process depends
on the ability of the business to collect and deploy customer information from
all channels and to integrate it with other relevant information.
The fourth process involves information management. This process involves
the collection, collation and the use of the customers’ data to generate
insight and appropriate marketing responses. This process involves data
repository, IT systems, analytical tools, front office and back office
applications, and CRM technology market participants. The data repository is the critical component of this process as it
provides a corporate memory of the customers.
The IT systems are required before the database
is integrated into a data warehouse and
user access can be provided across the
organization. The analytical tools
enable effective use of the data warehouse which can be found in data mining. The
front office applications are used to support all those activities that involve
direct interface with customers such as SFA and call center management. The
back-office application support internal administration activities and supplier
relationship, including human resources, procurement, warehouse
management. The critical concern of the front office and back office is the
cooperation to improve the customer relationship and workflow. The CRM
technology market participants are the
last component of the information management process. CRM applications and CRM
service providers are categorized into
specific categories. The critical segments for CRM applications are
Integrated CRM and Enterprise Resource Planning Suite, CRM Suite, CRM
Framework, CRM Best of Breed, and Built it Yourself.
These CRM service providers and consultants offer implementation support and
specialize in areas such as corporate strategy, CRM strategy, change
management, organization design, training, human resources, business
transformation, infrastructure building, and
systems integration, infrastructure outsourcing, business insight, research,
and business process outsourcing.
To summarize, this
information management process provides a means of sharing relevant information
of customers throughout the enterprise and replicating the mind of the
customer. IT planning should be
implemented to support the CRM strategy.
Data analysis tools can be used to measure the business activities, providing
the basis for the performance assessment
process.
The last process of the proposed strategic CRM conceptual framework is the performance assessment covering the critical task of ensuring that the strategic approach of the organization about CRM is being delivered to an appropriate and acceptable standard and that a basis for future enhancement is established. This process involves two significant steps; the shareholder results, and performance monitoring. Organizations should consider building employees value, customer value, and shareholder value and cost reduction to achieve the ultimate goal of the strategic CRM. The performance monitoring is another aspect of this process. Metrics used by organizations to measure and monitor the CRM performance should be well developed and well communicated.
The
project discussed CRM based on the identified article by (Payne & Frow, 2005). The lack of the precise definition and lack of clear framework directed the authors
to develop a generic technology-based definition for CRM that have been
acceptable by some practitioners. The authors proposed a strategic CRM
conceptual framework that is based on
five important processes. It begins with
the strategy development process, followed by the value creation process,
multi-channel integration process, information management process, and
performance assessment process. Each
process plays a significant role in the strategic CRM framework. This article can aid organizations which are confused about CRM definition and
framework. It can help them implement
the building blocks of the CRM strategy base on this proposed framework.
The purpose of this
discussion is to answer the following
questions and the importance of enterprise resource planning (ERP) systems in the
context of enterprise planning:
Today, ERP systems sit at the center of any organization’s information technology infrastructure. Why?
What advantages do ERPs give to an organization? How can standardized ERPs help provide a competitive advantage?
What is the underlying structure and architecture of an ERP system?
The Justification for ERP
Systems Importance in Information Technology Infrastructure
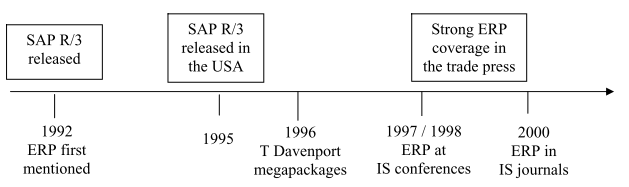
The term ERP began probably for the first time in 1992 (Klaus, Rosemann, & Gable, 2000). Klaus, Helmut, and Gable (2000) indicated that Lopes in his article of 1992 showed how that ERP was conceived of at the time the term was coined and praised ERP systems as “better, faster and more economical business solutions” (p. 27). ERP is described as the new information systems paradigm. Thomas Davenport introduced IS community to ERP systems in 1996. ERP papers were presented at three international information systems conferences in 1997 which marked the beginning of the period of literature. Thomas Davenport avoided the term ERP and called it mega-packages. Figure 1 shows the evolution of ERP.
Figure
1. The Evolution of ERP and The
Introduction of Information System to ERP (Klaus et al., 2000).
The importance of ERP
has increase in the information system
literature over the past few years (Klaus et al., 2000). ERP attracted the
attention of the IS field once it became apparent that large, and mainly US-based
corporations had begun to install these systems. (Nah, Zuckweiler, &
Lee-Shang Lau, 2003) indicated that Holland, Light, and Gison (1999) found that
business and IT legacy systems determine the degree of IT and organizational
change required for ERP implementation success.
Enterprise resource
planning (ERP) system is a packaged
software system that enables organizations to manage the efficiency and effectiveness of resources use such as
materials, human resources, finance and so forth (Klaus et al., 2000; Nah et
al., 2003; Wailgum & Perkins, 2018).
The ERP system supports a
process-oriented view of an enterprise and standardizes business process across
the organization (Nah et al., 2003). These ERP systems
are comprehensive, packaged software solutions to
integrate the complete range of a business’s processes and functions to present
a holistic view of the business from single
information and IT architecture (Klaus et al., 2000). Organizations which implemented ERP systems found it cost
effective and a competitive necessity (Klaus et al., 2000).
ERP Advantages and ERP Standardization
ERP systems provide various benefits to organizations including operational
benefits, managerial benefits, strategic benefits, IT infrastructure benefits,
and organizational benefits (Shang & Seddon, 2000). The operational benefits include cost reduction, cycle
time reduction, productivity improvement, quality improvement, and customer
services improvement. The managerial benefits include better resource
management, better decision making, and better performance control. The
strategic benefits include support current and future business growth plan,
support business alliance, building business innovation, building cost
leadership, generating or enhancing product differentiation, building external
linkages, worldwide expansion, and enabling e-business. The IT infrastructure benefits include
increased business flexibility, IT costs reduction, increased IT infrastructure
capability. The organizational benefits
include supporting business organizational change, facilitating business
learning and broaden employment skills;
empowerment changed the culture
with common visions, changing employees’
behavior with shifted focus, and better employees’ morale and satisfaction (Shang & Seddon, 2000).
The significant
advantages of the enterprise system are
that all modules of the IS can easily communicate with each other, offering
various efficiencies over the stand-alone
system (Pearlson & Saunders,
2001).
Information from one functional area is often
needed by another area in business.
For instance, the inventory system stores information about vendors who
supply specific parts. The same information is
also required by the accounts payable system, which pays the vendors for
their products. It makes sense to integrate these two systems to have a single accurate
record of vendors. ERP systems
are useful tools for organizations seeking to centralize operations and
decision making because this centralization will provide effective use of the
organizational databases (Pearlson & Saunders,
2001). Redundancy of the data entries and duplicate
data will be eliminated; standards for numbering,
naming and coding may be forced; and data and records can be cleaned up through
standardization. The ERP system can
reinforce the use of standard procedures across different locations.
Standardization plays a significant
role in the efficiency of the enterprise (Pearlson & Saunders,
2001). The inconsistency
of the data can cause significant issues
and must be addressed in ERP
systems. For instance, when integrating
two systems such as inventory and payable, the vendor name can be different in
inventory than in payable. Example of
this scenario can be IBM can be listed in the inventory as IBM corp., while in
payable International Business Machines.
This inconsistency of the data makes it challenging
to integrate databases and must be addressed for ERP systems to provide the
optimal advantages. The implementation
of ERP system requires organizations to make changes in the structure of the
organization and often in the individual tasks implemented by workers. Managers
are required to change the business process and more likely to redesign them
completely to accommodate the information system.
ERP System Architecture
Various studies discussed ERP system framework and architecture. (Al-Mudimigh, Ullah, & Saleem, 2009) discussed ERP framework of an automated data mining system. The proposed framework has three primary layers; CRM layer, the ERP layer, and Knowledge Discovery Layer. The CRM layer contains sales management, marketing management, customer service management, and prediction and forecasting. The ERP layer contains purchasing, sales, technology maintenance, production, accounting, audit, and warehouse. The knowledge discovery layer contains selected data, transformed data, rule-based DB, data warehouse, data mining, and results. Figure 2 illustrates the proposed ERP framework.
Figure
2. ERP Proposed Framework (Al-Mudimigh et al., 2009).
(Bahssas, AlBar, & Hoque, 2015) discussed various types of ERP architectures from the client-server framework, web-based ERP, Cloud ERP, N-tier ERP, and mobile ERP architecture. The mobile ERP architecture is selected for this discussion as it is a practical example in the age of the digital world. The mobile ERP architecture is divided into four tiers; the ERP system tier, content access engine and cache storage tier, content extraction engine tier, and user interface tier. The tier of the content access engine and cache storage contains cache structures, CML and remote function call (RFC) server. This tier is responsible for building queries based on mobile users request, and data retrieve in XML format. The RFC server is used to enable the business functions of an ERP system remotely. Tier three is the content extraction engine which takes charge of presentation logic and determines the type of browsers used by user’s mobile devices. Tier four is the user interface tier where mobile devices such as WAP-enabled phones, and PDAs with their particular browser and GUI are integrated (Bahssas et al., 2015). Figure 3 illustrates the selected Mobile ERP framework.
Figure 3. Mobile ERP Architecture (Bahssas et al., 2015).
Conclusion
In the age of Big Data and Big Data Analytics, the
role of information system in ERP has increased than ever before. ERP at the beginning was isolated from IS
until Thomas Davenport introduced IS community to ERP systems in 1996. The integration of ERP with IS is a complex process
and requires commitment from management and long-term vision. Enterprises
should plan for such a shift at the budget level, IT professionals’ levels and
operational level. This process is not
an overnight process, but it requires a holistic view of the business operation
at present as well as for the
future. It requires a comprehension of
the role of the current technology such as BD and BDA in ERP. Organizations are under pressure to be
competitive and stay competitive in the current digital world. ERP provides various benefits to the organization from operational benefits to IT
benefits. Various studies proposed
various ERP frameworks. In summary, ERP systems sit at the center of any
organization’s information technology infrastructure because of the various
benefits of ERP systems empowering businesses.
References
Al-Mudimigh, A. S., Ullah, Z.,
& Saleem, F. (2009). A framework of an automated data mining systems using
ERP model. International journal of
computer and Electrical Engineering, 1(5), 651.
Bahssas, D. M.,
AlBar, A. M., & Hoque, M. R. (2015). Enterprise resource planning (ERP)
systems: design, trends and deployment. The
International Technology Management Review, 5(2), 72-81.
Klaus, H.,
Rosemann, M., & Gable, G. G. (2000). What is ERP? Information Systems Frontiers, 2(2), 141-162.
Nah, F. F.-H.,
Zuckweiler, K. M., & Lee-Shang Lau, J. (2003). ERP implementation: chief
information officers’ perceptions of critical success factors. International journal of Human-computer
Interaction, 16(1), 5-22.
Pearlson, K.,
& Saunders, C. (2001). Managing and Using Information Systems: A Strategic
Approach. 2001: USA: John Wiley & Sons.
Shang, S., &
Seddon, P. B. (2000). A comprehensive framework for classifying the benefits of
ERP systems. AMCIS 2000 proceedings,
39.
The purpose of this proposal is to
design a state-of-the-art healthcare system in four States of Colorado, Utah,
Arizona, and New Mexico. Big Data and Big Data Analytics have played
significant roles in various industries including the healthcare industry. The
value that is driven by BDA can save lives and minimize costs for
patients. The project proposes a design
to apply BD and BDA in the healthcare system across these identified four
States. Cloud
computing is the most appropriate technology to deal with the large volume of
healthcare data at the storage level as well as at the data processing level. Due to
the security issue of the cloud computing, the Virtual Private Cloud (VPC) will
be used.
VPC provides a secure cloud environment using network traffic security
setup using security groups and network access control lists. The project requires other components to be
fully implemented using the latest technology such as Hadoop and MapReduce for
data streaming processing, machine learning for artificial intelligence, which
will be used for Internet of Things
(IoT). The NoSQL database HBase and
MongoDB will be used to handle the semi-structured data such as XML and
unstructured data such as logs and images.
Spark will be used for real-time
data processing which can be vital for urgent care and emergency services. This project addresses the assumptions and
limitations plus the justification for selecting these specific
components. All stakeholders in the healthcare sector including providers,
insurers, pharmaceuticals, practitioners should cooperate and coordinate to
facilitate the implementation process.
The rigid culture and silo pattern need to change for better healthcare
which can save millions of dollars to the healthcare industry and provide
excellent care to the patients at the same time.
Keywords: Big
Data Analytics; Hadoop; Healthcare Big Data System; Spark.
In
the age of Big Data (BD), information technology plays a significant role in the
healthcare industry (HIMSS, 2018). The role of information
technology in healthcare The healthcare sector generates a massive amount of data every day to conform to
standards and regulations (Alexandru, Alexandru, Coardos, & Tudora, 2016). The generated Big Data has the potential to
support many medical and healthcare operations including clinical decision support, disease surveillance
and population health management (Alexandru et al., 2016). This project proposes a state-of-the-art integrated system for hospitals located in Arizona, Colorado, New
Mexico, and Utah. The system is based on
the Hadoop ecosystem to help the
hospitals maintain and improve human
health via diagnosis, treatment and disease prevention.
It begins with Big
Data Analytics in Healthcare Overview, which covers the benefits and challenges
of BD and BDA in the healthcare
industry. The overview also covers the
various healthcare data sources for data analytics, in different formats such
as semi-structured, e.g., XML and JSON, and unstructured, e.g., images and XRays. The second section addresses the healthcare
BDA Design Proposal Using Hadoop. This section covers various components. The first component discusses the requirements
for this design. These requirements
include state-of-the-art technology such
as Hadoop/MapReduce, Spark, NoSQL database,
Artificial Intelligence (AI), Internet of Things (IoT). The project also covers various diagrams
including the data flow diagram, a communication
flow chart, and the overall system diagram.
The healthcare design system is bounded
by regulation, policies, and governance
such as HIPAA, that is also covered in
this project. The justification,
limitation, and assumptions are also discussed.
BD and BDA are
terms that have been used interchangeably
and described as the next frontier for innovation, competitions, and productivity (Maltby, 2011; Manyika et al., 2011). BD has a multi-V model with unique
characteristics, such as volume referring to the large dataset, velocity refers to the speed of the computation as well
as data generation, and variety referring to the various data types such as
semi-structured and unstructured (Assunção, Calheiros, Bianchi, Netto, & Buyya, 2015; Hu, Wen, Chua,
& Li, 2014). BD is
described as the next frontier for competition, innovation, and productivity. Various industries including healthcare have
taken this opportunity and applied BD and BDA in their business models (Manyika et al., 2011). McKinsey Institute predicted $300 billion as
a potential annual value to US healthcare (Manyika et al., 2011).
The healthcare
industry generated extensive data driven
by keeping patients’ records, complying with regulations and policies, and
patients care (Raghupathi & Raghupathi, 2014). The current trend is digitalizing this
explosive growth of the data in the age of Big Data (BD) and Big Data Analytics
(BDA) (Raghupathi & Raghupathi, 2014). BDA has made a revolution in healthcare by
transforming the valuable information, knowledge to predict epidemics, cure
diseases, improve quality of life, and avoid preventable deaths (Van-Dai, Chuan-Ming, & Nkabinde, 2016). Various applications of BDA in healthcare
include pervasive health, fraud detection, pharmaceutical discoveries, clinical
decision support system, computer-aided diagnosis, and biomedical applications.
Healthcare
sector employs BDA in various aspect of healthcare such as detecting diseases
at early stages, providing evidence-based medicine, minimizing doses of
medication to avoid any side effects, and delivering useful medicine base on genetic analysis. The use of BD and BDA can reduce the
re-admission rate, and thereby the healthcare related costs for patients are reduced.
Healthcare BDA can be used to detect spreading diseases earlier before
the disease gets spread using real-time analytics (Archenaa & Anita, 2015; Raghupathi &
Raghupathi, 2014; Wang, Kung, & Byrd, 2018). Example of the application of BDA in the healthcare system is Kaiser Permanente
implementing a HealthConnect technique to ensure data exchange across all
medical facilities and promote the use of electronic health records (Fox & Vaidyanathan, 2016).
Despite the various
benefits of BD and BDA in the healthcare
sector, various challenges and issues are emerging from the application of BDA
in healthcare. The nature of the healthcare
industry poses challenging to BDA (Groves, Kayyali, Knott, & Kuiken, 2016). The episodic culture, the data puddles, and
the IT leadership are the three significant
challenges of the healthcare industry to apply BDA. The episodic culture addresses the
conservative culture of the healthcare and the lack of IT technologies mindset
creating rigid culture. Few providers
have overcome this rigid culture and started to use the BDA technology. The
data puddles reflect the silo nature of healthcare. Silo is
described as one of the most significant
flaws in the healthcare sector (Wicklund, 2014). The use of the technology properly is lacking
in healthcare sector resulting in making the industry fall behind other
industries. All silos use their methods to collect data from labs, diagnosis,
radiology, emergency, case management and so forth. The IT leadership is another challenge is caused by the rigid culture of the
healthcare industry. The lack of the
latest technologies among the IT leadership in the healthcare industry is a severe problem.
The
current healthcare data is collected from clinical and non-clinical sources (InformationBuilders, 2018; Van-Dai et al., 2016; Zia & Khan, 2017). The electronic healthcare records are digital
copies of the medical history of the patients.
It contains a variety of data relevant to the care of the patients such
as demographics, medical problems, medications, body mass index, medical
history, laboratory test data, radiology reports, clinical notes, and payment
information. These electronic healthcare records are the most important data in healthcare data analytics,
because it provides effective and efficient methods for the providers and
organizations to share data (Botta, de Donato, Persico, & Pescapé, 2016; Palanisamy &
Thirunavukarasu, 2017; Van-Dai et al., 2016; Wang et al., 2018).
The biomedical
imaging data plays a crucial role in
healthcare data to aid disease monitoring, treatment planning and
prognosis. This data can be used to
generate quantitative information and make inferences from the images that can
provide insights into a medical condition.
The images analytics is more complicated
due to the noises of the data associated with the images and is one of the significant limitations with biomedical
analysis (Ji, Ganchev, O’Droma, Zhang, & Zhang, 2014; Malik & Sangwan,
2015; Van-Dai et al., 2016).
The sensing data is ubiquitous in the medical domain both for real-time and for historical data analysis. The sensing data involve several forms of medical data collection instruments such as the electrocardiogram (ECG) and electroencephalogram (EEG) which are vital sensors to collect signals from various parts of the human body. The sensing data plays a significant role for intensive care units (ICU) and real-time remote monitoring of patients with specific conditions such as diabetes or high blood pressure. The real-time and long-term analysis of various trends and treatment in remote monitoring programs can help providers monitor the state of those patients with certain conditions(Van-Dai et al., 2016).
The biomedical signals are collected from many sources such as hearts,
blood pressure, oxygen saturation levels, blood glucose, nerve conduction, and brain activity. Examples of biomedical signals include electroneurogram
(ENG), electromyogram (EMG), electrocardiogram (ECG), electroencephalogram
(EEG), electrogastrogram (EGG), and phonocardiogram (PCG). The biomedical signals real-time analytics
will provide better management of chronic diseases, earlier detection of
adverse events such as heart attacks, and strokes and earlier diagnosis of
disease. These biomedical signals can be discrete or
continuous based on the kind of care or severity of a particular pathological
condition (Malik &
Sangwan, 2015; Van-Dai et al., 2016).
The genomic data
analysis helps better understand the
relationship between various genetic, mutations, and disease conditions. It has
great potentials in the development of various gene therapies to cure certain
conditions. Furthermore, the genomic
data analytics can assist in translating genetic discoveries into personalized
medicine practice (Liang & Kelemen, 2016; Luo, Wu, Gopukumar, & Zhao, 2016;
Palanisamy & Thirunavukarasu, 2017; Van-Dai et al., 2016).
The clinical text
data analytics using the data mining are the transformation process of the
information from clinical notes stored in unstructured data format to useful patterns. The manual coding of clinical notes is costly
and time-consuming, because of their
unstructured nature, heterogeneity, different
format, and context across different patients and practitioners. Various methods such as natural language
processing (NLP) and information retrieval can be used to extract useful
knowledge from large volume of clinical text and automatically encoding
clinical information in a timely manner (Ghani, Zheng, Wei, & Friedman, 2014; Sun & Reddy, 2013; Van-Dai
et al., 2016).
The social network healthcare data analytics is based on various kinds of collected social media sources such as social networking sites, e.g., Facebook, Twitter, Web Logs, to discover new patterns and knowledge that can be leveraged to model and predict global health trends such as outbreaks of infections epidemics (InformationBuilders, 2018; Luo et al., 2016; Van-Dai et al., 2016; Zia & Khan, 2017). Figure 1 shows a summary of these healthcare data sources.
The implementation
of BDA in the hospitals within the four States aims
to improve the safety of the patient, the clinical outcomes, promoting wellness
and disease management (Alexandru et al., 2016; HIMSS, 2018). The BDA system will take advantages of the large healthcare-generated data to provide
various applied analytical disciplines such as statistical, contextual,
quantitative, predictive and cognitive spectrums (Alexandru et al., 2016; HIMSS, 2018). These applied analytical disciplines will
drive the fact-based decision making for planning management and learning in hospitals (Alexandru et al., 2016; HIMSS, 2018).
The proposal begins with the
requirements, followed by the data flow diagram, the communication flowcharts, and the overall system
diagram. The proposal addresses the
regulations, policies, and governance for the medical system. The limitation and assumptions are also addressed in this proposal, followed
by the justification for the overall design.
The basic
requirement for the implementation of this proposal included not only the tools and required software, but also the
training at all levels from staff, to nurses, to clinicians, to patients. The list of the requirements is divided into system requirement,
implementation requirement, and training
requirements.
The volume is one
of the significant characteristics of BD,
especially in the healthcare industry (Manyika et al., 2011). Based on the challenges addressed earlier
when dealing with BD and BDA in healthcare, the system requirements cannot be
met using the traditional on-premise technology center, as it cannot handle the
intensive computation requirements of BD, and the storage requirement for all
the medical information from various hospitals from the four States (Hu et al., 2014). Thus, the cloud computing environment is found
to be more appropriate and a solution for the implantation of this proposal. Cloud computing plays a significant role in
BDA (Assunção et al., 2015). The massive computation and storage
requirement of BDA brings the critical need for cloud computing emerging
technology (Mehmood, Natgunanathan, Xiang, Hua, & Guo, 2016). Cloud computing offers various benefits such
as cost reduction, elasticity, pay per use, availability, reliability, and maintainability (Gupta, Gupta, & Mohania, 2012; Kritikos, Kirkham, Kryza, &
Massonet, 2017).
However, although cloud computing offers
various benefits, it has security and privacy issues using the standard deployment
models of public cloud, private cloud, hybrid cloud, and community cloud. Thus, one of the major requirements is to
adopt the Virtual Private Cloud as it has been
regarded as the most prominent approach to trusted computing technology (Abdul, Jena, Prasad, & Balraju, 2014).
Cloud computing
has been facing various threats (Cloud Security Alliance, 2013, 2016, 2017).
Records showed that over the last three years
from 2015 until 2017, the number of breaches, lost medical records, and settlements of fines are staggering (Thompson, 2017). The
Office of Civil Rights (OCR) issued 22 resolution agreements, requiring
monetary settlements approaching $36 million (Thompson, 2017). Table 1
shows the data categories and the total for each year.
Table 1. Approximation of Records Lost by Category Disclosed on HHS.gov (Thompson, 2017)
Furthermore, a
recent report published by HIPAA showed the first three months of 2018
experienced 77 healthcare data breaches reported to the OCR (HIPAA, 2018d). In the second quarter of 2018, at least 3.14
million healthcare records were exposed (HIPAA, 2018a). In the third quarter of 2018, 4.39 million
records exposed in 117 breaches (HIPAA, 2018c).
Thus, the
protection of the patients’ private information requires the technology to
extract, analyze, and correlated potentially sensitive dataset (HIPAA, 2018b). The implementation of BDA requires security
measures and safeguards to protect the privacy of the patients in the
healthcare industry (HIPAA, 2018b). Sensitive data should be encrypted to prevent
the exposure of data in the event of theft (Abernathy & McMillan, 2016). The security requirements involve security at
the VPC cloud deployment model as well as at the local hospitals in each State (Regola & Chawla, 2013). The security at the VPC cloud deployment model
should involve the implementation of security groups and network access control
lists to allow access to the right individuals to the right applications and
patients’ records. Security group in VPC
acts as the first line of defense
firewall for the associated instances of the VPC (McKelvey, Curran, Gordon, Devlin, & Johnston, 2015). The network access control lists act as the
second layer of defense firewall for the associated subnets, controlling the
inbound and the outbound traffic at the subnet level (McKelvey et al., 2015).
The security at
the local hospitals level in each State is mandatory to protect patients’
records and comply with HIPAA regulations (Regola & Chawla, 2013). The medical equipment must be secured with
authentication and authorization techniques so that only the medical staff,
nurses and clinicians have access to the medical devices based on their
role. The general access should be prohibited as every member of the hospital has a different role with
different responses. The encryption should be used to hide the
meaning or intent of communication from unintended users (Stewart, Chapple, & Gibson, 2015). The
encryption is an essential element in security control especially for the data
in transit (Stewart et al., 2015). The hospital in all four State should
implement the encryption security control
using the same type of the encryption across the hospitals such as PKI, cryptographic application, and cryptography and
symmetric key algorithm (Stewart et al., 2015).
The system
requirements should also include the identity management systems that can
correspond with the hospitals in each state. The identity management system
provides authentication and authorization
techniques allowing only those who should have access to the patients’ medical
records. The proposal requires the
implementation of various encryption techniques such as secure socket layer
(SSL), Transport Layer Security (TLS), and Internet Protocol Security (IPSec)
to protect information transferred in public network (Zhang, R. & Liu, 2010).
While the
velocity of BD leads to the speed of generating large volume of data and
requires speed in data processing (Hu et al., 2014), the variety of the data requires specific technology capabilities to handle
various types of dataset such as structured, semi-structured, and unstructured
data (Bansal, Deshpande, Ghare, Dhikale, & Bodkhe, 2014; Hu et al., 2014). Hadoop ecosystem is found to be the most
appropriate system that is required to implement BDA (Bansal et al., 2014; Dhotre, Shimpi, Suryawanshi, & Sanghati, 2015). The implementation requirements include
various technologies and various tools.
This section covers various components that are required when implementing
Hadoop technology in the four States for healthcare BDA system.
Hadoop has three significant limitations, which must be addressed in this design. The first limitation is the lack of technical
support and document for open source Hadoop (Guo,
2013). Thus, this design requires the Enterprise
Edition of Hadoop to get around this limitation using Cloudera, Hortonworks, and MapR (Guo,
2013). The final decision for which product will be determined by the cost analysis team. The second limitation is that Hadoop is not
optimal for real-time data processing (Guo,
2013). The solution for this
limitation will require the integration of real-time streaming program as Spark
or Storm or Kafka (Guo,
2013; Palanisamy & Thirunavukarasu, 2017). This requirement of integrating
Spark is discussed below in a separate requirement for this design (Guo,
2013). The third limitation is that
Hadoop is not a good fit for large graph
dataset (Guo,
2013). The solution for this
limitation requires the integration of GraphLab which is also discussed below
in a separate requirement for this design.
1.3.1 Hadoop Ecosystem for Data Processing
Hadoop technologies have been in the front-runner for Big Data application (Bansal et al., 2014; Chrimes, Zamani, Moa, & Kuo, 2018). Hadoop ecosystem will be part of the implementation requirement as it is proven to serve well with intensive computation using large datasets (Raghupathi & Raghupathi, 2014; Wang et al., 2018). The implementation of Hadoop technology will be performed in the VPC deployment model. The Hadoop version that is required is version 2.x to include YARN for resource management (Karanth, 2014). Hadoop 2.x also include HDFS snapshots to provide a read-only image of the entire or a particular subset of a filesystem to protect against user errors, backup, and disaster recovery (Karanth, 2014). The Hadoop platform can be implemented to gain more insight into various areas (Raghupathi & Raghupathi, 2014; Wang et al., 2018). Hadoop ecosystem involves Hadoop Distributed File System, MapReduce, and NoSQL database such as HBase, and Hive to handle a large volume of dataset using various algorithms and machine learning to extract values from the medical records that are structured, semi-structured, and unstructured (Raghupathi & Raghupathi, 2014; Wang et al., 2018). Other components to support Hadoop ecosystem include Oozie for workflow, Pig for scripting, and Mahout for machine learning which is part of the artificial intelligence (AI) (Ankam, 2016; Karanth, 2014). Hadoop ecosystem will also include Flume for log collector, Sqoop for data exchange, and Zookeeper for coordination (Ankam, 2016; Karanth, 2014). HCatalog is a required component to manage the metadata in Hadoop (Ankam, 2016; Karanth, 2014). Figure 2 shows the Hadoop ecosystem before integrating Spark for real-time analytics.
1.3.2 Hadoop-specific
File Format for Splittable and Agnostic Compression
The ability of splittable files plays a significant role during the data processing (Grover, Malaska, Seidman, & Shapira, 2015). Therefore, Hadoop-specific file formats of SequenceFile, and Serialization formats like Avro, and columnar formats such as RCFile and Parquet should be used because these files share two essential characteristics that are essential for Hadoop applications: splittable compression and agnostic compression (Grover et al., 2015). Hadoop allows large files to be split for input to MapReduce and other types of jobs, which is required for parallel processing and an essential key to leveraging data locality feature of Hadoop (Grover et al., 2015). The agnostic compression is required to compress data using any compression codec without readers having to know the codec because the codec is stored in the header metadata of the file format (Grover et al., 2015). Figure 3 summarizes the three Hadoop file types with the two common characteristics.
Figure 3. Three Hadoop File Types
with the Two Common Characteristics.
1.3.3 XML and
JSON Use in Hadoop
The clinical data include semi-structured
formats such as XML and JSON. The split process of XML and JSON is not straightforward and can present unique challenges
using Hadoop (Grover et al., 2015). Since and Hadoop does not provide a
built-in InputFormat for either format of XML and JSON (Grover et al., 2015). Furthermore,
JSON presents more challenges to Hadoop than XML because no token is available
to mark the beginning or end of a record (Grover et al., 2015). When using these file format, two primary considerations must be taken.
The container format such as Avro should be used because Avro provides a compact and efficient method to store
and process the data when transforming the data into Avro (Grover et al., 2015).
A library for processing XML or JSON should be designed (Grover et al., 2015).
XMLLoader in PiggyBank library for Pig is an example when using XML data
type. The Elephant Bird project is an
example of a JSON data type file (Grover et al., 2015).
In the age of BD
and BDA, the traditional data store is found inadequate to handle not only the
large volume of the dataset but also the various types of the data format such
as unstructured and semi-structured (Hu et al., 2014). Thus,
Not Only SQL (NoSQL) database is emerged to meet the requirement of the
BDA. These NoSQL data stores are used for modern, and scalable databases (Sahafizadeh & Nematbakhsh, 2015). The scalability feature of the NoSQL data
stores enables the systems to increase the throughput when the demand increases
during the processing of the data (Sahafizadeh & Nematbakhsh, 2015). The platform can incorporate two scalability
types to support the large volume of the datasets; the horizontal and vertical scalability. The horizontal scaling allows the
distribution of the workload across many servers and nodes to increase the
throughput, while the vertical scaling requires more processors, more memories
and faster hardware to be installed on a
single server (Sahafizadeh & Nematbakhsh, 2015).
NoSQL data stores have various types such as MongoDB, CouchDB, Redis, Voldemort, Cassandra, Big Table, Riak, HBase, Hypertable, ZooKeeper, Vertica, Neo4j, db4o, and DynamoDB. These data stores are categorized into four types: document-oriented, column-oriented or column-family stores, graph database, and key-value (EMC, 2015; Hashem et al., 2015). The document-oriented data store can store and retrieve collections of data and documents using complex data forms in various formats such as XML and JSON as well as PDF and MS word (EMC, 2015; Hashem et al., 2015). MongoDB and CouchDB are examples of document-oriented data stores (EMC, 2015; Hashem et al., 2015). The column-oriented data store can store the content in columns aside from rows with the attributes of the columns stored contiguously (Hashem et al., 2015). This type of datastore can store and render blog entries, tags, and feedback (Hashem et al., 2015). Cassandra, DynamoDB, and HBase are examples of column-oriented data stores (EMC, 2015; Hashem et al., 2015). The key-value can store and scale large volumes of data and contains value and a key to access the value (EMC, 2015; Hashem et al., 2015). The value can be complicated, but this type of data stores can be useful in storing the user’s login ID as the key referencing the value of patients. Redis and Riak are examples of the key-value NoSQL data store (Alexandru et al., 2016). Each of these NoSQL data stores has its limitations and advantages. The graph NoSQL database can store and represent data using graph models with nodes, edges, and properties related to one another through relations which will be useful for unstructured medical data such as images, and lab results. Neo4j is an example of this type of graph NoSQL database (Hashem et al., 2015). Figure 4 summarizes these NoSQL data stores, data types for storage, and examples.
Figure 4. Big Data Analytics NoSQL
Data Store Types.
The proposed
design requires one or more NoSQL data stores to meet the requirement of BDA
using Hadoop environment for this healthcare BDA system. Healthcare big data has unique
characteristics which must be addressed
when selecting the data store and consideration must be taken for the various types of data. HBase
and HDFS are the commonly used storage manager in the Hadoop environment (Grover et al., 2015). HBase is a column-oriented data store which will be used to store multi-structured
data (Archenaa & Anita, 2015). HBase sets on top of HDFS in the Hadoop ecosystem framework (Raghupathi
& Raghupathi, 2014).
MongoDB will also be used to store the
semi-structured data set such as XML and JSON. Metadata
for HBase data schema, to improve the accessibility and readability of HBase
data schema (Luo et
al., 2016).
Riak will be used for a key-value dataset which can be used for the dictionary,
hash tables and associative arrays that can be used for login and user ID
information for patients as well as for providers and clinicians (Klein
et al., 2015).
Neo4j NoSQL will be used to store the images with nodes and edges such
as Lab images, XRays (Alexandru
et al., 2016).
The proposed healthcare system has a
logical data model and query patterns that need to be supported by NoSQL
databases (Klein
et al., 2015). The data model will include reading the
medical test results for patients is a core function used to populate the user
interface. It will also include a strong replica
consistency when a new medical result is written for a patient. Providers can make patient care decisions using
these records. All providers will be
able to see the same information within the hospital systems in the four
States, whether they are at the same site as the patients, or providing
telemedicine support from another location.
The logical data model includes mapping the application-specific model
into the particular data model, indexing, and query language capabilities of
each database. The HL7 Fast Healthcare
Interoperability Resources (FHIR) is used
as the logical data model for records analysis.
The patient’s data such as
demographic information such as names, addresses, and telephone will be modeled
using the FHIR Patient Resources such as result quantity, and result units (Klein
et al., 2015).
While the architecture of Hadoop ecosystem has been designed in various scenarios for data storage, data management statistical analysis, and statistical association between various data sources distributed computing and batch processing, this proposal requires real-time data processing which cannot be met by Hadoop alone (Basu, 2014). Real-time analytics will tremendous value to the healthcare proposed system. Thus, Apache Spark is another component which is required to implement this proposal (Basu, 2014). Spark allows in-memory processing for fast response time, bypassing MapReduce operations (Basu, 2014). With Spark integration with Hadoop, stream processing, machine learning, interactive analytics, and data integration will be possible (Scott, 2015). Spark will run on top of Hadoop to benefit from YARN and the underlying storage of HDFS, HBase and other Hadoop ecosystem building blocks (Scott, 2015). Figure 5 shows the core engines of the Spark.
Visualization is
one of the most powerful presentations of
the data (Jayasingh, Patra, & Mahesh, 2016). It helps in viewing the data in a more
meaningful way in the form of graphs, images, pie charts that can be understood
easily. It helps in synthesizing a large
volume of data set such as healthcare data to get at the core of such raw big data and convey the key points
from the data for insight (Meyer, 2018). Some of the commercial visualization tools
include Tableau, Spotfire, QlikView, and Adobe Illustrator. However, the most commonly used visualization
tools in healthcare include Tableau, PowerBI, and QlikView. This healthcare
design proposal will utilize Tableau.
Healthcare providers are successfully transforming data from information to insight using Tableau software. Healthcare organizations can utilize three approaches to get more from the healthcare datasets. The first approach is to break the data access by empowering the departments in healthcare to explore their data. The second approach is to uncover answers with data from multiple systems to reveal trends and outliers. The third approach is to share insights with executives, providers, and others to drive collaboration (Tableau, 2011). It has several advantages including the interactive visualization using drag-n-drop techniques, handling large amounts of data and millions of rows of data with ease, and other scripts such as Python can be integrated with Tableau (absentdata.com, 2018). It also provides mobile support and responsive dashboard. The limitation of Tableau is that it requires substantial training to fully master the platform, among other limitations including lack of automatic refreshing, conditional formatting and 16-column table limit (absentdata.com, 2018). Figure 6 shows the Patient Cycle Time data visualization using Tableau software.
Figure 6. Patient Cycle Time Data
Visualization Example (Tableau,
2011).
Artificial
Intelligence is a computational technique allowing machines to perform
cognitive functions such as acting or reacting to input, similar to the way humans do (Patrizio,
2018).
The traditional computing applications react to data, and the reactions
and responses must be hand-coded with
human intervention (Patrizio,
2018).
The AI systems are continuously in a flux mode changing their behavior
to accommodate any changes in the results and modifying their reactions
accordingly (Patrizio,
2018). The AI techniques can include video
recognition, natural language processing, speech recognition, machine learning
engines, and automation (Mills, 2018)
Healthcare system can benefit from
BDA integration with Artificial Intelligence (AI) (Bresnick, 2018). Since AI
can play a significant role in BDA in the healthcare
system, this proposal suggests the implementation of machine learning which is
part of the AI to deploy more precise and impactful interventions at the right
time in the care of patients (Bresnick, 2018). The
application of AI in the proposed design requires machine learning (Patrizio,
2018).
Since the data used in the AI and machine learning is already cleaned after removing the
duplicates and unnecessary data, AI can take advantages of these filtered data
leading to many healthcare breakthroughs
such as genomic and proteomic experiments to enable personalized medicine (Kersting
& Meyer, 2018).
The healthcare
industry has been utilizing AI, machine learning (ML) and data mining (DM) to
extract value from BD by transforming the large medical datasets into
actionable knowledge performing predictive and prescriptive analytics (Palanisamy & Thirunavukarasu, 2017). The ML will be used to utilize the AI to
develop sophisticated algorithm processing massive medical datasets including
the structured, unstructured, and semi-structured data performing advanced
analytics (Palanisamy & Thirunavukarasu, 2017). Apache Mahout, which is an open source for
ML, will be integrated with Hadoop to facilitate the execution of scalable
machine learning algorithms, offering various techniques such as
recommendation, classification, and
clustering (Palanisamy & Thirunavukarasu, 2017).
Internet of
Things (IoT) refers to the increased connected devices with IP addresses which
were not common years ago (Anand &
Clarice, 2015; Thompson, 2017).
These connected devices collect and use the IP addresses to transmit information (Thompson,
2017).
Providers in healthcare take advantages of the collected information to find new treatment methods and increase
efficiency (Thompson,
2017).
The
implementation of IoT will involve various technologies including frequency
identification (RFID), near field communication (NFC), machine to machine
(M2M), wireless sensor network (WSM), and addressing schemes (AS) (IPv6
addresses) (Anand
& Clarice, 2015; Kumari, 2017).
The implementation of IoT requires machine learning and algorithm to
find patterns, correlations, and anomalies that have the potential of enabling
healthcare improvements (O’Brien,
2016).
Machine learning is a critical component of artificial intelligence. Thus, the success of IoT depends on AI
implementation.
This design
proposal requires various training to IT professionals, providers and clinician
and those who will be using this healthcare ecosystem depending on their role (Alexandru et al., 2016; Archenaa & Anita, 2015). Each component of this
ecosystem should have training such as training for Hadoop/MapReduce, Spark,
Security, and so forth. The training
will play a significant role in the success of this design implementation to
apply BD and BDA in the healthcare system in the four States of Colorado, Utah,
Arizona, and New Mexico. Patients should be considered in training for
remote monitoring programs such as blood sugar monitoring, and blood pressure
monitoring applications. The senior generation might face some
challenges. However, with the technical
support, this challenge can be alleviated.
HBase stores data into table schema and specify the column family (Yang, Liu, Hsu, Lu, & Chu, 2013). The table schema must be predefined, and the column families must be specified. New columns can be added to families as required making the schema-flexible and can adapt to changing application requirements (Yang et al., 2013). HBase is developed in a similar way like HDFS with a NameNode and slave nodes, and MapReduce with JobTracker and TaskTracker slaves (Yang et al., 2013). HBase will play a vital role in the cluster environment of Hadoop system. In HBase master node called HMaster will manage the cluster, and region servers store portions of the tables and perform the work on the data. The HMaster reflects the Master Server and is responsible for monitoring all RegionServer instances in the cluster and is the interface for all metadata changes. This Master executes on the NameNode in the distributed cluster Hadoop environment. The HRegionServer represents the RegionServer and is responsible for serving and managing regions. The RegionServer runs on a DataNode in the distributed cluster Hadoop environment. The ZooKeeper will assist other machines are selected within the cluster as HMaster in case of a failure, unlike HDFS framework where NameNode has a single point of availability issue. Thus, the data flow between the DataNodes and the NameNodes when integrating HBase on top of HDFS is shown in Figure 7.
Figure 7. HBase Cluster Data Flow (Yang et al., 2013).
The healthcare system integrates four significant components such as HBase, MongoDB, MapReduce, and Visualization. HBase is used for data storage, MongoDB is used for metadata, MapReduce using Hadoop for computation, and data visualization tool. The signal data will be stored in HBase while the metadata and other clinical data will be stored in MongoDB. The data stored in both HBase and MongoDB will be accessible from the Hadoop/MapReduce environment for processing and the data visualization layer as well. One master node and eight slave nodes, and several supporting servers. The data will be imported to Hadoop and processed via MapReduce. The result of the computational process will be viewed through a data visualization tool such as Tableau. Figure 8 shows the data flow between these four components of the proposed healthcare ecosystem.
Figure 8. The Proposed Data Flow Between Hadoop/MapReduce and Other Databases.
Healthcare records have various types of data from structured, semi-structured to unstructured (Luo et al., 2016). Some of these healthcare records are XML-based records in the semi-structured format using tags. XML stands for eXtensible Markup Language (Fawcett, Ayers, & Quin, 2012). Healthcare sector can drive value from these XML documents which reflect semi-structured data (Aravind & Agrawal, 2014). Example of this XML-based patients records shows in Figure 9.
Figure 9. Example of the Patient’s Electronic Health
Record (HL7, 2011)
XML-based records
need to get ingested into Hadoop system for the analytical
purpose to derive value from this semi-structured XML-based data. However, Hadoop does not offer a standard
XML “RecordReader” (Lublinsky, Smith, & Yakubovich, 2013). XML is one of the standard file formats for
MapReduce. Various approaches can be
used to process XML semi-structured data.
The process of ETL (Extract, Transform and Load) can be used to process
XML data in Hadoop. MongoDB is a NoSQL database which is required in this design proposal. It handles XML document-oriented type.
The ETL process in
MongoDB starts with the extract and transform.
The MongoDB application provides
the ability to map the XML elements within the document to the downstream data structure. The application supports the ability to
unwind simple arrays or present embedded documents using appropriate data relationships
such as one-to-one (1:1), one-to-many (1: M), or many-to-many (M: M) (MongoDB, 2018). The
application infers the schema information by examining a subset of documents
within target collections. Organizations
can add fields to the discovered data
model that may not have been present within the subset of documents used for
schema inference. The application infers
information about the existing indexes for collections to be queried.
It prompts or warns of queries
that do not contain any indexes fields.
The application can return a subset of fields from documents using query
projections. For queries against MongoDB
Replica Sets, the application supports
the ability to specify custom MongoDB Read Preferences for individual query
operations. The application then infers information
about sharded cluster deployment and note the shard key fields for each sharded
collection. For queries against MongoDB
Sharded Clusters, the application warns against queries that do not use proper
query isolation. Broadcast queries in a sharded cluster can have a
negative impact on database performance (MongoDB, 2018).
The load process in MongoDB is performed after the extract and transform process. The application supports the ability to write data to any MongoDB deployment whether a single node, replica set or sharded cluster. For writes to a MongoDB Sharded Cluster, the application informs or display an error message to the user if XML documents do not contain a shard key. A custom WriteConcern can be used for any write operations to a running MongoDB deployment. For the bulk loading operations, writing documents in batches using the insert() method can be used using the MongoDB 2.6 version or above, which supports the bulk update database command. For the bulk loading into a MongoDB sharded deployment, the bulk insert into a sharded collection is supported, including the pre-splitting of the collections’ shard key and inserting via multiple mongos processes. Figure 10 shows this ETL process for XML-based patients records using MongoDB.
Figure 10. The Proposed XML ETL Process in MongoDB.
Real-Time streaming can be implemented using any real-time streaming program such as Spark, Kafka, or Storm. This healthcare design proposal will integrate Spark open-source program for the real-time streaming data such as sensing data, from various sources such as intensive care units, remote monitoring programs, biomedical signals. The data from various sources will be flow into Spark for analytics and then imported to the data storage systems. Figure 11 illustrates the data flow for real-time streaming analytics.
The communication flow involves the stakeholders involves in the healthcare system. These stakeholders include providers, insurer, pharmaceutical, and IT professionals and practitioners. The communication flow is centered with the patient-centric healthcare system using the cloud computing technology for the four States of Colorado, Utah, Arizona, and New Mexico. These stakeholders are from these states. The patient-centric healthcare system is the central point for communication. The patients communicate with the central system using the web-based platform, and clinical forums as needed. The providers communicate with the patient-centric healthcare system using resource usages, patient feedback, and hospital visits, and services details. The insurers communicate with the central system using claims database, and census and societal data. The pharmaceutical vendors will communicate with the central system using prescription and drug reports which can be retrieved by the providers from anywhere in these four states. The IT professionals and practitioners will communicate with the central system for data streaming, medical records, genomics, and all omics data analysis and reporting. Figure 12 shows the communication flow between these stakeholders and the central system in the cloud that can be accessed from any of these identified four States.
Figure 12. The Proposed Patient-Centric Healthcare System Communication Flow.
The overall system represents the state-of-the-art healthcare ecosystem system that utilizes the latest technology for healthcare Big Data Analytics. The system is bounded by the regulations and policy such as HIPAA to ensure the protection of the patients’ privacy across the various layers of the overall system. The system integrated components include the Hadoop latest technology with MapReduce and HDFS. The data government layer is the bottom layer which contains three major building blocks: master data management (MDM), data life-cycle management (DLM) components, and data security and privacy management. The MDM component is responsible for data completeness, accuracy, and availability, while the DLM is responsible for archiving the data, maintaining the data warehousing, data deletion, and disposal. The data security and privacy management building block is responsible for sensitive data discovery, vulnerability and configuration assessment, security policies application, auditing and compliance reporting, activity monitoring, identify and access management, and protecting data. The top layers include data layer, data aggregation layer, data analytics layer, and information exploration layer. The data layer is responsible for data sources and content format, while the data aggregation layer involves various components from data acquisition process, transformation engines, and data storage area using Hadoop, HDFS, NoSQL databases such as MongoDB and HBase. The data analytics layer involves the Hadoop/MapReduce mapping process, stream computing, real-time streaming, and database analytics. AI and IoT are part of the data analytics layer. The information exploration layer involves the data visualization layer, visualization reporting, real-time monitoring using healthcare dashboard, and clinical decision support. Figure 13 illustrates the overall system diagram with these layers.
Figure 13. The Proposed Healthcare Overall System Diagram.
Healthcare data
must be stored in a secure storage area to protect the information and the
privacy of patients (Liveri, Sarri, & Skouloudi, 2015). When the healthcare
industry fails to comply with the regulation and policies, the fines and the
cost can cause financial stress on the industry (Thompson, 2017). Records
showed that the healthcare industry paid millions of dollars in fines. The Advocate
Health Care in suburban Chicago agreed to the most
significant figure as of August 2016 with a total amount of $5.55
million (Thompson, 2017). Memorial
Health System in southern Florida became the second entity to top of paying $5
million (Thompson, 2017). Table 2 shows the five most substantial fines posted to the Office of Civil Rights (OCR)
site.
Table 2. Five Largest Fines Posted to OCR Web Site (Thompson, 2017)
The hospitals must adhere to the data privacy regulations and legislative rules carefully to protect the patients’ medical records from data breaches (HIPAA). The proper security policy and risk management must be implemented to ensure the protection of private information as well to minimize the impact of confidential data in case of loss or theft (HIPAA, 2018a, 2018c; Salido, 2010). The healthcare system design proposal requires the implementation of a system for those hospitals or providers who are not compliant with the regulation and policies and the escalation path (Salido, 2010). This design proposal implements four major principles as the best practice to comply with required policies and regulation and protect the confidential data assets of the patients and users (Salido, 2010). The first principle is to honor policies throughout private data life (Salido, 2010). The second principle for best practice in healthcare design system is to minimize the risk of unauthorized access or misuse of confidential data (Salido, 2010). The third principle is to minimize the impact of confidential data loss, while the fourth principle is to document appropriate controls and demonstrate their effectiveness (Salido, 2010). Figure 14 shows these four principles which this healthcare design proposal adheres to ensure protection healthcare data from unauthorized users and comply with the required regulation and policies.
Figure 14. Healthcare Design Proposal Four Principles.
This design
proposal assumes that the healthcare sector in the four States will support the
application of BD and BDA across these fours States. The support includes investment in the proper
technology, proper tools and proper training based on the requirements of this
design proposal. The proposal also
assumes that the stakeholders including the providers, patients, insurer,
pharmaceutical vendors, and practitioners will welcome the application of BDA
to take advantages of it to provide efficient healthcare services, increase
productivity, decrease costs for healthcare sector as well as for patients, and
provide better care to patients.
The
limitation of this proposal is the timeframe that is required to implement
it. With the support of the healthcare
sector from these four States, the implementation can be expedited. However, the
silo and the rigid culture of the healthcare may interfere with the
implementation which can take longer than
expected. The initial implementation
might face unexpected challenges. However, these unexpected challenges will
come from the lack of experienced IT professionals and managers in the field of
BD and BDA domain. This design proposal
will be enhanced based on the observations from the first few months of the
implementation.
The
traditional database and analytical systems are
found inadequate when dealing with healthcare data in the age of BDA. The characteristics of the healthcare datasets
including the large volume medical records, the variety of the dataset from
structured, to semi-structured, to the unstructured
dataset, and the velocity of the dataset generation and the data processing
requires technology such as cloud computing (Fernández
et al., 2014). Cloud computing is found the
best solution when dealing with BD and BDA to address the challenges of BD
storage, and the intensive-computing processing demands (Alexandru
et al., 2016; Hashem et al., 2015). The healthcare system in the four States will
shift the communication technology and services for applications across the
hospitals and providers (Hashem
et al., 2015). Some of the advantages of cloud computing adoption include virtualized resources, parallel processing,
security and data service integration with scalable data storage (Hashem
et al., 2015). With the cloud computing technology, the
healthcare sector in the four States will reduce the cost, and increase the
efficiency (Hashem
et al., 2015). When quick access to critical data for
patients care is required quickly, the mobility of accessing the data from
anywhere is one of the most significant advantages of the cloud computing
adoption as recommended by this proposed design
(Carutasu,
Botezatu, Botezatu, & Pirnau, 2016). The benefits of cloud
computing include technological benefits such as visualization, multi-tenancy,
data and storage, security and privacy compliance (Chang, 2015). The cloud computing
also offers economic benefits such as pay per use, cost reduction, return on
investment (Chang, 2015).
The non-functional benefits of the cloud computing cover the elasticity,
quality of service, reliability, and availability (Chang, 2015).
Thus, the proposed design justifies the use of cloud computing for
several benefits as cloud computing is proven the best technology for BDA
especially for healthcare data analytics.
Although
cloud computing offers several benefits to the proposed healthcare system,
cloud computing has been suffering from security and privacy concerns (Balasubramanian & Mala, 2015; Kazim & Zhu,
2015). The security concerns
involve risk areas such as external data storage, dependency on the public
internet, lack of control, multi-tenancy
and integration with internal security (Hashizume, Rosado, Fernández-medina, & Fernandez,
2013). The traditional
security techniques such as identity,
authentication, and authorization are not sufficient for cloud computing
environments in their current forms using the standard deployment models of the
public cloud, and private cloud (Hashizume et al., 2013). The increasing trend in the security threats
data breaches, and the current deployment models of private and public clouds,
which are not meeting the security challenges, have triggered the need for
another deployment to ensure security and privacy protection. Thus, the VPC deployment model which is a new
deployment model of cloud computing technology (Botta et al., 2016; Sultan, 2010; Venkatesan, 2012; Zhang,
Q., Cheng, & Boutaba, 2010). The VPC is taking advantages of technologies
such as a virtual private network (VPN) which will allow hospitals and
providers to set up their required network settings such as security (Botta et al., 2016; Sultan, 2010; Venkatesan, 2012; Zhang,
Q. et al., 2010). The VPC deployment model will have dedicated
resources with the VPN to provide the required isolation for security to
protect the patients’ information (Botta et al., 2016; Sultan, 2010; Venkatesan, 2012; Zhang,
Q. et al., 2010).
Thus, this proposed design will be using VPC cloud computing deployment mode to
store and use healthcare data in a secure and isolated environment to protect
the patients’ medical records (Regola & Chawla, 2013).
Hadoop ecosystem
is a required component in this proposed design for several reasons. Hadoop technology is a commonly used
computing paradigm for massive volume
data processing in the cloud computing (Bansal et al., 2014; Chrimes et al., 2018; Dhotre et al., 2015). Hadoop is the only technology that enables large healthcare volumes of data to be stored in its native forms (Dezyre, 2016). Hadoop is proven to develop better treatments
for diseases such as cancer by accelerating the design and testing of effective
treatments tailored to patients, expanding genetically based clinical cancer
trials, and establishing a national cancer knowledge network to guide treatment
decision (Dezyre, 2016). With Hadoop system, hospitals in the four
States will be able to monitor the patient vitals (Dezyre, 2016). The Children’s Healthcare of Atlanta is an example of using the Hadoop ecosystem to treat over six thousand
children in their ICU units (Dezyre, 2016).
The proposed
design requires the integration of NoSQL database because it offers benefits
such as mass storage support, reading and writing operations which are fast,
and the expansion is easy with a low cost
(Sahafizadeh & Nematbakhsh, 2015). HBase is proposed as a
required NoSQL database as it is faster when reading more than six million
variants which are required when
analyzing large healthcare datasets (Luo et al., 2016). Besides, query engine such as SeqWare can be integrated with HBase as
needed to help bioinformatics researchers
access large-scale whole-genome datasets (Luo et al., 2016). HBase can store clinical sensors where the
row key serves as the time stamp of a single value, and the column stores
patients’ physiological values that correspond with the row key time stamp (Luo et al., 2016). HBase is scalable, high-performance
and low-cost NoSQL data store that can be integrated with Hadoop sitting on top
of HDFS (Yang et al., 2013). As a column-oriented
NoSQL data store that runs on top of HDFS of Hadoop ecosystem, HBase is well suited to parse the healthcare large data
sets (Yang et al., 2013). HBase supports
applications written in Avro, REST and Thrift (Yang et al., 2013). MongoDB is another NoSQL data store, which
will be used to store metadata to improve the accessibility and readability of
the HBase data schema (Luo et al., 2016).
The integration of
Spark is required in order to overcome
the Hadoop limitation of real-time data processing
because Hadoop is not optimal for real-time data processing (Guo,
2013). Thus, Apache Spark is a required component to
implement this proposal so that the healthcare BDA system can take advantages
of data processing at rest using the batching technique as well as a motion using the real-time processing
technique (Liang
& Kelemen, 2016).
Spark allows in-memory
processing for fast response time, bypassing MapReduce operations (Liang
& Kelemen, 2016).
Spark is a high integration to the recent Hadoop cluster deployment (Scott,
2015).
While Spark is a powerful tool on its own for processing a large volume of medical and healthcare
datasets, Spark is not well-suited for production workload. Thus, the integration of Spark with Hadoop
ecosystem provides many capabilities
which Spark cannot offer on its own, and Hadoop cannot offer on its own.
The integration of
AI as part of this proposal is justified by the examination of Harvard Business
Review (HBR) that shows ten promising AI application in healthcare (Kalis, Collier, & Fu, 2018). The findings of HBR’s
examination showed that the application of AI could create up to $150 billion
in annual savings for U.S. healthcare by 2026 (Kalis et al., 2018). The
result also showed that AI currently creates the most value in assisting the
frontline clinicians to be more productive and in making back-end processes more
efficient (Kalis et al., 2018).
Furthermore, IBM invested $1 billion in AI through the IBM Watson Group, and healthcare industry is
the most significant application of Watson (Power, 2015).
Big Data and Big
Data Analytics have played significant roles in various industries including
the healthcare industry. The value that is driven by BDA can save
lives and minimize costs for patients.
This project proposes a design to apply BDA in the healthcare system
across four States of Colorado, Utah, Arizona, and New Mexico. Cloud
computing is the most appropriate technology to deal with the large volume of
healthcare data. Due to the security issue of the cloud computing, the Virtual
Private Cloud (VPC) will be used. VPC provides a secure cloud environment using
network traffic security setup using security groups and network access control
lists.
The project
requires other components to be fully implemented using the latest technology
such as Hadoop and MapReduce for data streaming processing, machine learning
for artificial intelligence, which will be used
for Internet of Things (IoT). The NoSQL
database HBase and MongoDB will be used to handle the semi-structured data such
as XML and unstructured data such as logs and images. Spark will be
used for real-time data processing which can be vital for urgent care
and emergency services. This project
addressed the assumptions and limitations plus the justification for selecting
these specific components.
In summary, all
stakeholders in the healthcare sector
including providers, insurers, pharmaceuticals, practitioners should cooperate
and coordinate to facilitate the implementation process. All stakeholders are responsible to
facilitate the integration of BD and BDA into the healthcare system. The rigid culture and silo pattern need to
change for better healthcare system which can save millions of dollars to the
healthcare industry and provide excellent care to the patients at the same
time.
Abdul, A. M., Jena, S.,
Prasad, S. D., & Balraju, M. (2014). Trusted Environment In Virtual Cloud. International Journal of Advanced Research
in Computer Science, 5(4).
Abernathy,
R., & McMillan, T. (2016). CISSP Cert
Guide: Pearson IT Certification.
Alexandru,
A., Alexandru, C., Coardos, D., & Tudora, E. (2016). Healthcare, Big Data
and Cloud Computing. management, 1,
2.
Alguliyev,
R., & Imamverdiyev, Y. (2014). Big
data: big promises for information security. Paper presented at the
Application of Information and Communication Technologies (AICT), 2014 IEEE 8th
International Conference on.
Archenaa,
J., & Anita, E. M. (2015). A survey of big data analytics in healthcare and
government. Procedia Computer Science, 50,
408-413.
Assunção,
M. D., Calheiros, R. N., Bianchi, S., Netto, M. A. S., & Buyya, R. (2015).
Big Data Computing and Clouds: Trends and Future Directions. Journal of Parallel and Distributed
Computing, 79, 3-15. doi:10.1016/j.jpdc.2014.08.003
Balasubramanian,
V., & Mala, T. (2015). A Review On Various Data Security Issues In Cloud
Computing Environment And Its Solutions. Journal
of Engineering and Applied Sciences, 10(2).
Bansal,
A., Deshpande, A., Ghare, P., Dhikale, S., & Bodkhe, B. (2014). Healthcare
data analysis using dynamic slot allocation in Hadoop. International Journal of Recent Technology and Engineering, 3(5),
15-18.
Botta,
A., de Donato, W., Persico, V., & Pescapé, A. (2016). Integration of Cloud
Computing and Internet Of Things: a Survey. Future
Generation computer systems, 56, 684-700.
Carutasu,
G., Botezatu, M., Botezatu, C., & Pirnau, M. (2016). Cloud Computing and
Windows Azure. Electronics, Computers and
Artificial Intelligence.
Chang,
V. (2015). A Proposed Framework for Cloud Computing Adoption. International Journal of Organizational and
Collective Intelligence, 6(3).
Chrimes,
D., Zamani, H., Moa, B., & Kuo, A. (2018). Simulations of
Hadoop/MapReduce-Based Platform to Support its Usability of Big Data Analytics
in Healthcare.
Cloud
Security Alliance. (2013). The Notorious Nine: Cloud Computing Top Threats in
2013. Cloud Security Alliance: Top
Threats Working Group.
Cloud
Security Alliance. (2016). The Treacherous 12: Cloud Computing Top Threats in
2016. Cloud Security Alliance: Top
Threats Working Group.
Cloud
Security Alliance. (2017). The Treacherous 12 Top Threats to Cloud Computing. Cloud Security Alliance: Top Threats Working
Group.
Dhotre,
P., Shimpi, S., Suryawanshi, P., & Sanghati, M. (2015). Health Care Analysis
Using Hadoop. Internationaljournalofscientific&tech
nologyresearch, 4(12), 279r281.
EMC.
(2015). Data Science and Big Data
Analytics: Discovering, Analyzing, Visualizing and Presenting Data. (1st
ed.): Wiley.
Fawcett,
J., Ayers, D., & Quin, L. R. (2012). Beginning
XML: John Wiley & Sons.
Fernández,
A., del Río, S., López, V., Bawakid, A., del Jesus, M. J., Benítez, J. M.,
& Herrera, F. (2014). Big Data with Cloud Computing: An Insight on the
Computing Environment, MapReduce, and Programming Frameworks. Wiley Interdisciplinary Reviews: Data Mining
and Knowledge Discovery, 4(5), 380-409. doi:10.1002/widm.1134
Fox,
M., & Vaidyanathan, G. (2016). Impacts of Healthcare Big Data: A Framwork With Legal and Ethical Insights. Issues in Information Systems, 17(3).
Ghani,
K. R., Zheng, K., Wei, J. T., & Friedman, C. P. (2014). Harnessing big data
for health care and research: are urologists ready? European urology, 66(6), 975-977.
Grover,
M., Malaska, T., Seidman, J., & Shapira, G. (2015). Hadoop Application Architectures: Designing Real-World Big Data
Applications: ” O’Reilly Media, Inc.”.
Groves,
P., Kayyali, B., Knott, D., & Kuiken, S. V. (2016). The ‘Big Data’
Revolution in Healthcare: Accelerating Value and Innovation.
Guo,
S. (2013). Hadoop operations and cluster
management cookbook: Packt Publishing Ltd.
Gupta,
R., Gupta, H., & Mohania, M. (2012). Cloud
Computing and Big Data Analytics: What is New From Databases Perspective?
Paper presented at the International Conference on Big Data Analytics,
Springer-Verlag Berlin Heidelberg.
Hashem,
I. A. T., Yaqoob, I., Anuar, N. B., Mokhtar, S., Gani, A., & Khan, S. U.
(2015). The Rise of “Big Data” on Cloud Computing: Review and Open Research
Issues. Information Systems, 47,
98-115. doi:10.1016/j.is.2014.07.006
Hashizume,
K., Rosado, D. G., Fernández-medina, E., & Fernandez, E. B. (2013). An
analysis of security issues for cloud computing. Journal of internet services and applications, 4(1), 1-13.
doi:10.1186/1869-0238-4-5
Hu,
H., Wen, Y., Chua, T., & Li, X. (2014). Toward Scalable Systems for Big
Data Analytics: A Technology Tutorial. Practical
Innovation, Open Solution, 2, 652-687. doi:10.1109/ACCESS.2014.2332453
Jayasingh,
B. B., Patra, M. R., & Mahesh, D. B. (2016, 14-17 Dec. 2016). Security issues and challenges of big data
analytics and visualization. Paper presented at the 2016 2nd International
Conference on Contemporary Computing and Informatics (IC3I).
Ji,
Z., Ganchev, I., O’Droma, M., Zhang, X., & Zhang, X. (2014). A cloud-based
X73 ubiquitous mobile healthcare system: design and implementation. The Scientific World Journal, 2014.
Karanth,
S. (2014). Mastering Hadoop: Packt
Publishing Ltd.
Kazim,
M., & Zhu, S. Y. (2015). A Survey on Top Security Threats in Cloud
Computing. International Journal Advanced
Computer Science and Application, 6(3), 109-113.
Kersting,
K., & Meyer, U. (2018). From Big Data to Big Artificial Intelligence? :
Springer.
Klein,
J., Gorton, I., Ernst, N., Donohoe, P., Pham, K., & Matser, C. (2015, June
27 2015-July 2 2015). Application-Specific
Evaluation of No SQL Databases. Paper presented at the 2015 IEEE
International Congress on Big Data.
Kritikos,
K., Kirkham, T., Kryza, B., & Massonet, P. (2017). Towards a
Security-Enhanced PaaS Platform for Multi-Cloud Applications. Future Generation computer systems, 67,
206-226. doi:10.1016/j.future.2016.10.008
Kumari,
W. M. P. (2017). Artificial INtelligence Meets Internet of Things.
Liang,
Y., & Kelemen, A. (2016). Big Data Science and its Applications in Health
and Medical Research: Challenges and Opportunities. Austin Journal of Biometrics & Biostatistics, 7(3).
Liveri,
D., Sarri, A., & Skouloudi, C. (2015). Security and Resilience in eHealth:
Security Challenges and Risks. European
Union Agency For Network And Information Security.
Lublinsky,
B., Smith, K. T., & Yakubovich, A. (2013). Professional hadoop solutions: John Wiley & Sons.
Luo,
J., Wu, M., Gopukumar, D., & Zhao, Y. (2016). Big data application in
biomedical research and health care: a literature review. Biomedical informatics insights, 8, BII. S31559.
Malik,
L., & Sangwan, S. (2015). MapReduce Framework Implementation on the
Prescriptive Analytics of Health Industry. International
Journal of Computer Science and Mobile Computing, ISSN, 675-688.
Maltby,
D. (2011). Big Data Analytics. Paper
presented at the Annual Meeting of the Association for Information Science and
Technology.
Manyika,
J., Chui, M., Brown, B., Bughin, J., Dobbs, R., Roxburgh, C., & Byers, A.
H. (2011). Big Data: The Next Frontier for Innovation, Competition, and
Productivity. McKinsey Global Institute.
McKelvey,
N., Curran, K., Gordon, B., Devlin, E., & Johnston, K. (2015). Cloud
Computing and Security in the Future Guide
to Security Assurance for Cloud Computing (pp. 95-108): Springer.
Mehmood,
A., Natgunanathan, I., Xiang, Y., Hua, G., & Guo, S. (2016). Protection of
Big Data Privacy. Institute of Electrical
and Electronic Engineers, 4, 1821-1834. doi:10.1109/ACCESS.2016.2558446
Meyer,
M. (2018). The Rise of Healthcare Data Visualization.
Mills,
T. (2018). Eight Ways Big Data And AI Are Changing The Business World.
MongoDB.
(2018). ETL Best Practice.
O’Brien,
B. (2016). Why The IoT Needs ARtificial Intelligence to Succeed.
Palanisamy,
V., & Thirunavukarasu, R. (2017). Implications of Big Data Analytics in
developing Healthcare Frameworks–A review. Journal
of King Saud University-Computer and Information Sciences.
Patrizio,
A. (2018). Big Data vs. Artificial Intelligence.
Power,
B. (2015). Artificial Intelligence Is Almost Ready for Business.
Raghupathi,
W., & Raghupathi, V. (2014). Big data analytics in healthcare: promise and
potential. Health Information Science and
Systems, 2(1), 1.
Regola,
N., & Chawla, N. (2013). Storing and Using Health Data in a Virtual Private
Cloud. Journal of medical Internet
research, 15(3), 1-12. doi:10.2196/jmir.2076
Sahafizadeh,
E., & Nematbakhsh, M. A. (2015). A Survey on Security Issues in Big Data
and NoSQL. Int’l J. Advances in Computer
Science, 4(4), 2322-5157.
Salido,
J. (2010). Data Governance for Privacy, Confidentiality and Compliance: A
Holistic Approach. ISACA Journal, 6,
17.
Scott,
J. A. (2015). Getting Started with Spark: MapR Technologies, Inc.
Stewart,
J., Chapple, M., & Gibson, D. (2015). ISC
Official Study Guide. CISSP Security
Professional Official Study Guide (7th ed.): Wiley.
Sultan,
N. (2010). Cloud Computing for Education: A New Dawn? International Journal of Information Management, 30(2), 109-116.
doi:10.1016/j.ijinfomgt.2009.09.004
Tableau.
(2011). Three Ways Healthcare Probiders are transforming data from information
to insight. White Paper.
Thompson,
E. C. (2017). Building a HIPAA-Compliant
Cybersecurity Program, Using NIST 800-30 and CSF to Secure Protected Health
Information.
Van-Dai,
T., Chuan-Ming, L., & Nkabinde, G. W. (2016, 5-7 July 2016). Big data stream computing in healthcare
real-time analytics. Paper presented at the 2016 IEEE International
Conference on Cloud Computing and Big Data Analysis (ICCCBDA).
Venkatesan,
T. (2012). A Literature Survey on Cloud Computing. i-Manager’s Journal on Information Technology, 1(1), 44-49.
Wang,
Y., Kung, L. A., & Byrd, T. A. (2018). Big Data Analytics: Understanding
its Capabilities and Potential Benefits for Healthcare Organizations. Technological Forecasting and Social Change,
126, 3-13. doi:10.1016/j.techfore.2015.12.019
Yang,
C. T., Liu, J. C., Hsu, W. H., Lu, H. W., & Chu, W. C. C. (2013, 16-18 Dec.
2013). Implementation of Data Transform
Method into NoSQL Database for Healthcare Data. Paper presented at the 2013
International Conference on Parallel and Distributed Computing, Applications
and Technologies.
Zhang,
Q., Cheng, L., & Boutaba, R. (2010). Cloud Computing: State-of-the-Art and
Research Challenges. Journal of internet
services and applications, 1(1), 7-18. doi:10.1007/s13174-010-0007-6
Zhang,
R., & Liu, L. (2010). Security models
and requirements for healthcare application clouds. Paper presented at the
Cloud Computing (CLOUD), 2010 IEEE 3rd International Conference on.
Zia, U. A., & Khan, N. (2017). An Analysis of Big
Data Approaches in Healthcare Sector. International
Journal of Technical Research & Science, 2(4), 254-264.
The purpose of this discussion is to
address the relationship between the Internet of Things (IoT) and the
Artificial Intelligence (AI), and whether one can be used efficiently without
the help from the other. The discussion
begins with the Internet of Things (IoT)
and artificial intelligence (AI) overview, followed by the relationship between
them.
Internet of Things (IoT) and Artificial Intelligence
Overview
Internet of Things (IoT) refers to
the increased connected devices with IP addresses that years ago were not
common (Anand & Clarice, 2015;
Thompson, 2017). The connected devices collect and use these IP addresses to transmit information (Thompson, 2017). Organizations take
advantages of the collected information for innovation, enhancing customer
service, optimizing processes (Thompson, 2017). Providers in healthcare take advantages of the collected information
to find new treatment methods and
increase efficiency (Thompson, 2017).
IoT implementation involves various
technologies such as radio frequency identification
(RFID), near field communication (NFC), machine to machine (M2M), wireless
sensor network (WSM), and addressing schemes (AS) (IPv6 addresses) (Anand & Clarice, 2015;
Kumari, 2017). The RFID uses electromagnetic fields to
identify and track tags attached to objects.
The NFC is a set of thoughts and technologies where smartphones and other objects want to communicate
under IoT. The M2M is used often for
remote monitoring. WSM is a set of a large
number of sensors used to monitor environmental conditions. The AS is the primary
tool which is used in IoT and giving IP addresses to each object which wants to
communicate (Anand & Clarice, 2015;
Kumari, 2017).
Machine learning (ML) is a subset of
AI. Machine learning (ML) involves
supervise and unsupervised ML (Thompson, 2017). In the AI domain, the advances in computer science
result in creating intelligent machines that resemble humans in their functions
(NMC, 2018). The access to
categories, properties, and relationships between various datasets help develop
knowledge engineering allowing computers to simulate the perception, learning,
and decision making of human (NMC, 2018). The ML enables
computers to learn without being explicitly programmed (NMC, 2018). The unsupervised ML
and AI allow for security tools such as behavior-based-analytics and anomaly
detection (Thompson, 2017). The neural network
of AI help model the biological function of the human
brain to interpret and react to specific inputs such as words and tone of voice
(NMC, 2018). The neural networks
have been used for voice recognition, and
natural language processing (NLP), enabling a human
to interact with machines.
The Relationship Between IoT and AI
Various reports and studies have
discussed the relationship between IoT and AI.
(O’Brien, 2016) has reported the need of IoT to AI to succeed. (Jaffe, 2014) suggested the same
thing that IoT will not work without AI.
IoT future depends on ML to find patterns, correlations, and anomalies
that have the potential of enabling improvement in almost every facet of the daily lives (Jaffe, 2014).
Thus, the success of IoT depends on
AI. IoT follows
five necessary steps: sense, transmit,
store, analyze and act (O’Brien, 2016). AI plays a significant role in the analyzing step, where the ML which is the subset of AI gets
involved in this step. When ML is applied in the analysis step, it can change
the subsequent step of “act” which dictates whether the action has high value
or no value to the consumer (O’Brien, 2016).
(Schatsky, Kumar, & Bumb,
2018)
suggested the AI can unlock the potential of IoT. As cited in (Schatsky et al., 2018), Gartner predicts by 2022, more than 80% of enterprise IoT
projects will include AI components which are
up from only 10% in 2018. International
Data Corp (IDC) predicts by 2019, AI will support “all effective” IoT efforts, and without AI, data from the deployments will
have limited value (Schatsky et al., 2018).
Various companies are crafting an IoT strategy to include AI (Schatsky et al., 2018). Venture capital
funding of AI-focused IoT start-ups is growing, while vendors of IoT platforms
such as Amazon, GE, IBM, Microsoft, Oracle, and Salesforce are integrating AI capabilities (Schatsky et al., 2018). The value of AI is
the ability to extract insight from data quickly.
The ML, which is a subset of AI, enables the automatic identification of
patterns and detected anomalies in the data that smart sensors and devices
generate (Schatsky et al., 2018). IoT is expected to
combine with the power of AI, blockchain, and other emerging technologies to
create the “smart hospitals” of the future (Bresnick, 2018). Example of
AI-powered IoT devices includes automated
vacuum cleaners, like that of the iRobot Roomba, smart thermostat solutions,
like that of Nest Labs, and self-driving cars, such as that of Tesla Motors (Faggella, 2018; Kumari,
2017).
Conclusion
This discussion has addressed artificial intelligence (AI) and the internet of things (IoT) and the relationship between them. Machine learning which is a subset of AI is required for IoT at the analysis phase. Without this analysis phase, IoT will not provide the value-added insight organizations anticipate. Various studies and reports have indicated that the success and the future of IoT depend on AI.
The purpose of this discussion is to discuss the influence of artificial intelligence on big data analytics. As discussed in the previous discussion, Big Data empowers artificial intelligence. This discussion is about the impact of artificial intelligence in the Big Data Analytics domain. The discussion begins with artificial intelligence building blocks and big data building blocks, following by the impact of the artificial intelligence in the BDA.
Artificial Intelligence Building Blocks and Their Impact on
BDA
Understanding the building blocks of
AI could help understand the impact of AI on BDA. Various reports and studies have identified
various building blocks for AI. Four
building blocks have been identified
In (Chibuk, 2018), four building blocks that are expected to shape the next
stage of AI. The computation methodology
is the first building block of AI. This
component is structured in a way to improve the computers move from binary to
infinite connections. The storage of the information is the second building
block of AI improving storing and accessing data in the more efficient form. Brain-computer interface is the third building
block of AI, through which the human
minds would speak silently with a computer, and our thought would turn into
actions. The mathematics and algorithms
form the last building block of AI to include advanced mathematics called
capsule network and having networks to teach each other based on rules defined (Chibuk, 2018).
(Rao, 2017) has identified five fundamental building blocks for AI in the
banking sector, while they can be easily
applicable to other sectors. Machine
learning (ML) is the first component of AI in banking where the software can learn on its own without being programmed
and adjust its algorithms to respond to new insights. The data mining algorithms
hand over findings to a human for further work, while machine learning
can act on its own (Rao, 2017). The financial and
banking industry can benefit from machine learning for fraud detection,
security settlement and alike (Rao, 2017). The deep learning
(DL) is another building block of AI in the banking
industry (Rao, 2017). DL can leverage a
hierarchy of artificial neural networks, similar to the human brain to do its
job. DL mimics the human brain to
perform non-linear deductions, unlike the linearly traditional programs (Rao, 2017). DL can produce
better decisions by factoring learning from previous transactions or
interactions to conclude (Rao, 2017). Example of DL is
the collected information about customers and their behaviors from social
networks, from which their likes and preferences can be inferred, and financial institutions can utilize this insight to
make contextual, relevant offers to those customers in real-time (Rao, 2017). Natural language process (NLP) is the third
building block for AI in banking (Rao, 2017). NLP is a key
building block in AI to help computers learn, analyze and understand human
language (Rao, 2017). NLP can be used to
organize and structure knowledge in order to answer queries, translate content
from one language to another, recognize people by their speech, mine text, and
perform sentiment analysis (Rao, 2017). The natural language generation (NLG) is another essential
building block in AI, which can help computers analyze, understand, and make
sense of human language (Rao, 2017). It can help
converse and interact intelligently with humans (Rao, 2017). NLG can transform
raw data into a narrative, which banks such as Credit Suisse are using to
generate portfolio review (Rao, 2017). Visual recognition
is the last component of AI which help recognize images and their content (Rao, 2017). It uses DL to perform its role of finding faces, tagging
images, identifying the components of visuals, and picking out similar images
from a large dataset (Rao, 2017). Various banks such as Australia’s Westpac is using this
technology to allow customers to activate their new card from their smartphone
camera, and Bank of America, Citibank, Wells Fargo, and TD Bank are using this technology of visual recognition to
allow customers to deposit checks remotely via mobile app (Rao, 2017).
(Gerbert, Hecker,
Steinhäuser, & Ruwolt, 2017) have identified ten building blocks for AI. They have suggested that the simplest AI use
cases often consist of a single building
block. However, they often evolve to combine two or more blocks over time (Gerbert et al., 2017). The machine vision is
one of the building blocks of AI. The machine vision building block of AI is
the classification and tracking of real-world objects based on visual, x-ray,
laser or other signals. The quality of
machine vision depends on the labels of a large number
of reference images which is performed by a human
(Gerbert et al., 2017). Video-based
computer vision is anticipated to recognize actions and predict motions within
the next five years (Gerbert et al., 2017). The speech
recognition is another building block which involves the transformation of
auditory signals into text (Gerbert et al., 2017). Siri and Alexa can identify most words in a general
vocabulary, but as vocabulary becomes specific, tailored programs such as the
PowerScribe of Nuance for radiologist will be needed (Gerbert et al., 2017).
Information processing building block of
AI involves searching billions of
documents or constructing basic knowledge
graphs identifying relationships in text.
This building block is closely related to NLP, which is also identified
as another building block of AI (Gerbert et al., 2017). NLP can provide
basic summaries of text and infer intent in some instances (Gerbert et al., 2017). Learning from data is another component of AI, which is a
machine learning and able to predict values or classify information based on historical data (Gerbert et al., 2017). While ML is an
element in AI building blocks of machine vision and NLP, it is also a separate
building block of AI (Gerbert et al., 2017). Other building
blocks of AI include the planning and exploring agents that can help identify
the best sequence of actions to achieve certain goals. Self-driving cars rely on this building clock
for navigation (Gerbert et al., 2017). The image
generation is another building block of AI, which is the opposite of machine
vision block, as it creates images based on models. Speech generation is another building block
of AI which covers both data-based text generation and text-based speech
synthesis. The handling and control building block of AI refers to interactions
with real-world objects (Gerbert et al., 2017). The navigating and movement building block of AI covers
the ways where robots move through a given physical environment. The
self-driving cars and drones do well with their wheels and rotors. However, walking on legs especially a single
pair of legs is challenging (Gerbert et al., 2017).
Artificial Intelligence (AI) and machine learning (ML) have observed an increasing trend across industries, and public sector (Brook, 2018). Such increasing trend plays a significant role in the digital world (Brook, 2018). This increasing trend is driven by the customer-centric view of data involving use data as part of the product or service (Brook, 2018). The customer-centric model assumes data enrichment with data from multiple sources, and the data is divided into real-time data and historical data (Brook, 2018). Businesses build a trust relationship with customers, where data is becoming the central model for many consumer services such as Amazon, and Facebook (Brook, 2018). The data value increases over time (Brook, 2018). The impact of machine learning and artificial intelligence have driven the need for “corporate memory” to be rapidly adopted in organizations. (Brook, 2018) have suggested organizations implement loosely coupled data silos and data lake which can contribute to the corporate memory and the super-fast data usage in the age of AI-driven data usage. Various examples of AL and ML impact on BDA and the value of data over time include Coca-Cola’s global market and extensive product list, IBM’s machine learning system Watson, GE Power using BD, ML, and internet of things (IoT) to build internet of energy (Marr, 2018). Figure 1 shows the impact of AI and ML on Big Data Analytics and the value of the data over time.
Figure 1. Impact of AI and ML on BDA and
the Value of Data Overtime (Brook, 2018).
AI is anticipated to be the most dominant factor that
will have a disruptive impact on organizations and businesses (Hansen, 2017). (Mills, 2018) has suggested that organizations need to
embrace BD and AI to help their businesses.
EMC survey has shown that 69% of information technology decision-makers in New Zealand believe that BDA
is critical to their business strategy, and 41% already incorporated BD into the
everyday business decision (Henderson, 2015).
The application of AI to BDA can assist businesses and organizations to detect a correlation between factors humans cannot perceive (Henderson, 2015). It can allow organizations to deal with the speed of the information change today in the business world (Henderson, 2015). AI can help organization add a level of intelligence to their BDA to understand complex issues better quicker than humans can in the absence of AI (Henderson, 2015). AI can also serve to fill the gap left by not having enough data analysts available (Henderson, 2015). AI can also reveal insights that can lead to novel solutions to existing problems or even uncover issues that are not previously known (Henderson, 2015). A good example of AI impact on BDA is the AI-powered BDA in Canada which is used to identify patterns in the vital signs of premature babies that can be used in the early detection of life-threatening infections. Figure 2 shows AI and BD working together for better analytics and better insight.
Figure 2: Artificial Intelligence and
Big Data (Hansen, 2017).
Conclusion
This assignment has discussed the impact of artificial intelligence (AI) on Big Data Analytics (BDA). It began with the identification of the building blocks of the AI and the impact of each building block on BDA. BDA has an essential impact on AI as it empowers it, and AI has a crucial role in BDA as demonstrated and proven in various fields especially in the healthcare and financial industries. The researcher would like to summarize this relationship between AI and BDA in a single statement: “AI without BDA is lame, and BDA without AI is blind.”
References
Brook, P. (2018). Trends in Big Data
and Artificial Intelligence Data
Chibuk, J. D.
(2018). Four Building Blocks for a General AI.
Gerbert, P.,
Hecker, M., Steinhäuser, S., & Ruwolt, P. (2017). The Building Blocks of
Artificial Intelligence.
Hansen, S.
(2017). How Big Data Is Empowering AI and Machine Learning?
Henderson, J.
(2015). Insight: What role does Artificial Intelligence Play in Big Data? What are the links between artificial
intelligence and Big Data?
Marr, B. (2018).
27 Incredible Examples Of AI And Machine Learning In Practice.
Mills, T. (2018).
Eight Ways Big Data And AI Are Changing The Business World.
Rao, S.
(2017). The Five Fundamental Building Blocks for Artificial Intelligence in
Banking.