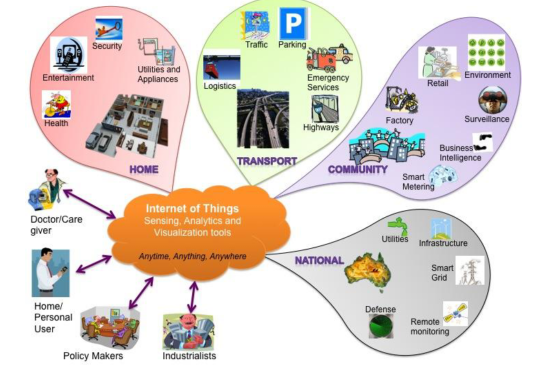
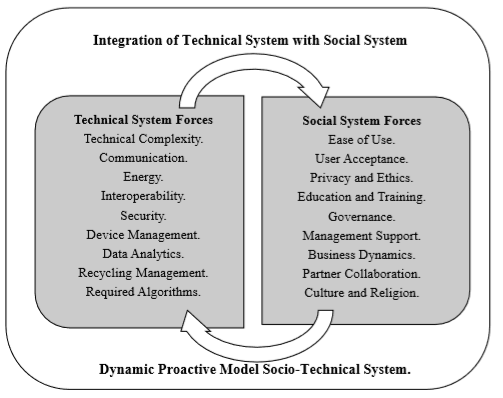
"Artificial Intelligence without Big Data Analytics is lame, and Big Data Analytics without Artificial Intelligence is blind." Dr. O. Aly, Computer Science.
The traditional distributed models involve the Shared Memory and the Message Passing programming models. The SM and the MP techniques are two major parallel computing architecture models (Coulouris, Dollimore, & Kindberg, 2005; Manoj, Manjunath, & Govindarajan, 2004). They provide the basic interaction model for distributed tasks and lack any facility to automatically parallelize and distribute tasks or tolerate faults (Hammoud, Rehman, & Sakr, 2012; Sakr & Gaber, 2014). Advanced models such as MapReduce, Pregel, and GraphLab are introduced to overcome the inefficiencies and challenges of these traditional distributed models especially when porting them to the Cloud environment (Fernández et al., 2014; Low et al., 2012; Sakr & Gaber, 2014). These new models are built upon these two traditional models of the SM and MP and offer various key properties for the Cloud environment (Sakr & Gaber, 2014). These models are also referred to as “distributed analytics engines” (Sakr & Gaber, 2014).
Shared Memory Distributed Programming
The SM system has a global memory that is accessible to all the processors in the system (Manoj et al., 2004). The SM techniques include two models based on the nature of sharing of this global memory across processors. The first model is the Uniform-Memory-Access (UMA) (Manoj et al., 2004; Pulipaka, 2016). The second model is the Non-Uniform-Memory-Access (NUMA) (Coulouris et al., 2005; Dean & Ghemawat, 2004; Hennessy & Patterson, 2011; Manoj et al., 2004; Mishra, Dehuri, & Kim, 2016). The access time to the memory in UMA model from two processors is equal. The access time to the memory in NUMA varies for different processors (Manoj et al., 2004). Hardware Distributed Shared Memory (DSM) is an example of the NUMA including Stanford DASH, SCI, DDM, and KSRI (Manoj et al., 2004). When using a uniprocessor environment, the programming in SM systems involves updating shared data, which is regarded to be a simple programming process (Manoj et al., 2004). However, with the increasing number of processors, the environment experiences increased contention and long latencies in accessing the shared memory (Manoj et al., 2004). The contention and latencies diminish the performance and limit scalability (Manoj et al., 2004). Additional issues with the SM systems involve data access synchronization, cache coherency, and memory consistency (Manoj et al., 2004). The developers must ensure appropriate memory access order through synchronization primitives (Manoj et al., 2004). Moreover, when using hardware in the implementation of the SM abstraction, the cost of the system gets increased (Manoj et al., 2004).
In SM programming model, the
data is not explicitly communicated but implicitly exchanged via sharing which
entails the use of synchronization
techniques within the distributed programs (Sakr & Gaber, 2014). The tasks can
communicate by reading and writing to the shared memory or disks
locations. The tasks can access any
location in the distributed memories/disk which is similar to the threads of a
single process in operating systems, where all threads share the process
address space and communicate by reading and writing to that space (Sakr & Gaber, 2014). The distributed tasks are prevented from simultaneously writing to a
shared data to avoid inconsistent or corrupted data
when using synchronization which is
required to control the order in which read/write operations are performed by various tasks (Sakr & Gaber, 2014). The communication
between two tasks is implicit through reads and writes to shared arrays and
variables and synchronization is explicit through locks and barriers (Sakr & Gaber, 2014).
The SM programming model must meet two main
requirements: developers do not need to
explicitly encode functions to send/receive messages, and the underlying
storage layer provides a shared view of
all tasks. MapReduce satisfies these two
requirements using a map and reduce, and the communications occur only between the
map and reduce phases under the full control of the MapReduce engine. Moreover,
the synchronization is also handled by
the MapReduce engine (Sakr & Gaber, 2014). For the storage layer,
MapReduce utilizes the Hadoop Distributed File System (HDFS) which provides a
shared abstraction for all tasks, where any task transparently access any location in HDFS (Sakr & Gaber, 2014). Thus, MapReduce
provides the shared-memory abstraction which is provided internally by Hadoop
that entails MapReduce engine and HDSF (Sakr & Gaber, 2014). GraphLab also offers a
shared-memory abstraction by eliminating the need for users to send/receive messages in update functions
explicitly and provides a shared view among vertices in a graph (Fernández et al., 2014; Low et
al., 2012; Sakr & Gaber, 2014). GraphLab allows scopes of vertices to overlap
and vertices to read and write from and to their scopes which can cause a conflict of read-write and write-write between
vertices sharing scope (Fernández et al., 2014; Low et
al., 2012; Sakr & Gaber, 2014).
Message Passing Distributed Programming
In MP programming model the distributed tasks communicate by sending and receiving messages where the distributed tasks do not share an address space at which they can access each other’s memories (Sakr & Gaber, 2014). The MP programming model provides the abstraction which is similar to that of the process and not the threads in the operating system (Sakr & Gaber, 2014). This model incurs communications overheads for explicitly sending and receiving messages that contain data such as variable network latency, potentially excessive data transfer (Hammoud et al., 2012; Sakr & Gaber, 2014). When using MP programming model, no explicit synchronization is needed because for every send operation; there is a corresponding receive operation (Sakr & Gaber, 2014). Moreover, no illusion for single shared address space is required for the distributed system for tasks to interact (Sakr & Gaber, 2014).
Message Passing Interface (MPI)
is a popular example of the MP programming model, which is an industry-standard library for writing
message-passing programs (Hammoud et al., 2012; Sakr &
Gaber, 2014). Pregel is regarded the common analytics
engine which utilizes the message-passing programming model (Malewicz et al., 2010; Sakr
& Gaber, 2014). In
Pregel, vertices can communicate only by sending and receiving messages, which
should be explicitly encoded (Malewicz et al., 2010; Sakr
& Gaber, 2014). The SM
programs are easier to develop than the MP programs (Manoj et al., 2004; Sakr &
Gaber, 2014). The code structure of SM programs is often
not much different than its respective sequential one, with only additional
directives to be added to specify parallel/distributed tasks, the scope of variables, and synchronization points (Manoj et al., 2004; Sakr &
Gaber, 2014). Large-scale distributed systems such as the
Cloud imply non-uniform access latencies such as accessing remote data takes
more time than accessing local data, thus enforcing programmers to lay out data
close to relevant tasks (Sakr & Gaber, 2014).
References
Coulouris, G. F., Dollimore, J.,
& Kindberg, T. (2005). Distributed
systems: concepts and design: pearson education.
Dean, J., &
Ghemawat, S. (2004). MapReduce: simplified data processing on large clusters.
OSDI’04 Proceedings of the 6th conference on Symposium on Opearting Systems
Design and Implementation” dalam: International Journal of Engineering Science
Invention. 10-100.
Fernández, A.,
del Río, S., López, V., Bawakid, A., del Jesus, M. J., Benítez, J. M., &
Herrera, F. (2014). Big Data with Cloud Computing: an insight on the computing
environment, MapReduce, and programming frameworks. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 4(5),
380-409.
Hammoud, M., Rehman,
M. S., & Sakr, M. F. (2012). Center-of-gravity
reduce task scheduling to lower mapreduce network traffic. Paper presented
at the Cloud Computing (CLOUD), 2012 IEEE 5th International Conference on.
Hennessy, J. L.,
& Patterson, D. A. (2011). Computer
architecture: a quantitative approach: Elsevier.
Low, Y., Bickson,
D., Gonzalez, J., Guestrin, C., Kyrola, A., & Hellerstein, J. M. (2012).
Distributed GraphLab: a framework for machine learning and data mining in the
cloud. Proceedings of the VLDB Endowment,
5(8), 716-727.
Malewicz, G.,
Austern, M. H., Bik, A. J., Dehnert, J. C., Horn, I., Leiser, N., &
Czajkowski, G. (2010). Pregel: a system
for large-scale graph processing. Paper presented at the Proceedings of the
2010 ACM SIGMOD International Conference on Management of data.
Manoj, N.,
Manjunath, K., & Govindarajan, R. (2004). CAS-DSM: A compiler assisted
software distributed shared memory. International
Journal of Parallel Programming, 32(2), 77-122.
Mishra, B. S. P.,
Dehuri, S., & Kim, E. (2016). Techniques
and Environments for Big Data Analysis: Parallel, Cloud, and Grid Computing
(Vol. 17): Springer.
MapReduce and RDF Data
Query Processing Optimized Performance
This project
provides a survey on the state-of-the-art techniques for applying MapReduce to
improve the Resource Description Framework (RDF) data query processing
performance. There has been a tremendous
effort from the industry and researchers to develop efficient and scalable RDF
processing systems. Most of the complex
data-processing tasks require multiple cycles of the MapReduce which are
chained together into sequential. The decomposition
of a task into cycles or subtasks are often implemented. Thus, the low overall workflow cost is a key
element in the decomposition. Each cycle
of the MapReduce results in significant overhead. When using RDF, the decomposition problem
reflects the distribution of operations such as SELECT, and JOIN into subtasks which
is supported by MapReduce cycle. The issue of the decomposition is related to
the operations order because the neighboring operation in a query plan can be
effectively grouped into the same subtasks.
When using MapReduce, the operation order is based on the requirement of
key partitioning so that the neighboring operations do not cause any conflict. Various techniques are proposed to enhance
the performance of the semantic web queries using RDF and MapReduce.
This
project begins with the overview of RDF, followed by RDF Store Architecture,
MapReduce Parallel Processing Framework, and Hadoop. RDF and SPARQL using semantic query is
discussed covering the syntax of SPARQL and the missing features that are
required to enhance the performance of RDF using MapReduce. Various techniques are discussed and analyzed
on the application of MapReduce to improve RDF query processing
performance. Some of these techniques
include HadoopRDF, RDFPath, and PigSPARQL.
Resource Description
Framework (RDF)
Resource
Description Framework (RDF) is described as an emerging standard for processing
metadata (Punnoose,
Crainiceanu, & Rapp, 2012; Tiwana & Balasubramaniam, 2001) (Punnoose
et al., 2012; Tiwana & Balasubramaniam, 2001). RDF provides interoperability between
applications that exchange machine-understandable information on the Web (Sakr
& Gaber, 2014; Tiwana & Balasubramaniam, 2001). The primary goal of RDF is to define a
mechanism and provide standards for the metadata and for describing resources on
the Web (Boussaid,
Tanasescu, Bentayeb, & Darmont, 2007; Firat & Kuzu, 2011; Tiwana &
Balasubramaniam, 2001) which makes no a priori assumptions
about a particular application domain or the associated semantics (Tiwana
& Balasubramaniam, 2001). These standards or mechanisms provided by the
RDF can prevent users from accessing irrelevant subjects because RDF provided
metadata that is relevant to the desired information (Firat
& Kuzu, 2011).
RDF
is also described as a Data Model (Choi,
Son, Cho, Sung, & Chung, 2009; Myung, Yeon, & Lee, 2010) for representing
labeled directed graphs (Choi
et al., 2009; Nicolaidis & Iniewski, 2017), and useful for a
Data Warehousing solution as the MapReduce framework (Myung
et al., 2010).
RDF is used as an important building block of Semantic Web of Web 3.0
(see Figure 1) (Choi
et al., 2009; Firat & Kuzu, 2011). The technologies of the Semantic Web are
useful for maintaining data in the Cloud (M.
F. Husain, Khan, Kantarcioglu, & Thuraisingham, 2010). These technologies of the Semantic Web
provide the ability to specify and query heterogeneous data in a standard
manner (M.
F. Husain et al., 2010).
RDF
Data Model can be extended to ontologies to include RDF Schema (RDFS) and Ontology
Web Language (OWL) to provide techniques to define and identify vocabularies
specified to a certain domain, schema and relations between the elements of the
vocabulary (Choi
et al., 2009).
RDS can be exported in various
file formats (Sun
& Jara, 2014).
The most common of these formats is RDF + XML and XSD (Sun
& Jara, 2014).
The OWL is used to add semantics to the schema (Sun
& Jara, 2014).
For instance, if “A isAssociatedWith B,” which implies that “B is AssociatedWith
A” (Sun
& Jara, 2014).
The OWL allows the ability to express these two things the same way (Sun
& Jara, 2014).
This similarity feature allowed by OWL is very useful for “joining” data
expressed in different schemas (Sun
& Jara, 2014).
This feature allows building relationship and joining up data from
multiple sites, described as “Linked Data” facilitating the heterogeneous data
stream integration (Sun
& Jara, 2014).
OWL enables new facts to be derived from known facts using the inference
rules (Nicolaidis
& Iniewski, 2017).
Another example which can be used to enforce the inference technique
using OWL is when a triple states that a car is a subtype of a vehicle and
another triple state that a Cabrio is a subtype of a car, the new fact will be
that Cabrio is a vehicle which can be inferred from the previous facts (Nicolaidis
& Iniewski, 2017).
RDF Data Model is described to be a simple and flexible framework (Myung et al., 2010). The underlying form and expression in RDF is a collection of “triples,” each consisting of a subject (s), a predicate (p), and an object (o) (Brickley, 2014; Connolly & Begg, 2015; Nicolaidis & Iniewski, 2017; Przyjaciel-Zablocki, Schätzle, Skaley, Hornung, & Lausen, 2013; Punnoose et al., 2012). The subjects and predicates are Resources; each encoded as a Uniform Resource Identifier (URI) to ensure the uniqueness, while the object can be a Resource or a Literal such as string, date or number (Nicolaidis & Iniewski, 2017). In (Firat & Kuzu, 2011), the basic structure of the RDF Data Model is based on a triplet of the object (O), quality (A) and value (V) (Firat & Kuzu, 2011). The basic role of RDF is to provide Data Model of the object, quality and value (OAV) (Firat & Kuzu, 2011). RDF Data Model is similar to the XML Data Model, where both do not include form-related information or names (Firat & Kuzu, 2011).
Figure 1: The Major Building Blocks of the Semantic Web Architectures. Adapted from (Firat & Kuzu, 2011).
RDF has been commonly used in
applications such as Semantic Web, Bioinformatics, and Social Networks because
of its great flexibility and applicability (Choi
et al., 2009).
These applications require a huge computation over a large set of data (Choi
et al., 2009).
Thus, the large-scale graph datasets are very common among these
applications of Semantic Web, Bioinformatics, and Social Networks (Choi
et al., 2009).
However, the traditional techniques for processing such large-scale of
the dataset are found to be inadequate (Choi
et al., 2009).
Moreover, RDF Data Model enables
existing heterogeneous database systems to be integrated into a Data Warehouse
because of its flexibility (Myung
et al., 2010).
The flexibility of the RDF Data Model also provides users the inference
capability to discover unknown knowledge which is useful for large-scale data
analysis (Myung
et al., 2010). RDF triples require terabytes of disk space
for storage and analysis (M.
Husain, McGlothlin, Masud, Khan, & Thuraisingham, 2011; M. F. Husain et
al., 2010).
Researchers are encouraged to develop efficient repositories, because
there are only a few existing frameworks such as RDF-3X, Jena, Sesame, BigOWLIM
for Semantic Web technologies (M.
Husain et al., 2011; M. F. Husain et al., 2010).
These frameworks are single-machine RDF systems and are widely used
because they are user-friendly and perform well for small and medium-sized RDF datasets
(M.
Husain et al., 2011; M. F. Husain et al., 2010; Sakr & Gaber, 2014).
The RDF-3X is regarded to be the fastest single machine RDF systems regarding
query performance that vastly outperforms previous single machine systems (M.
Husain et al., 2011; M. F. Husain et al., 2010; Sakr & Gaber, 2014).
However, the performance of RDF-3X diminishes for queries with unbound
objects and low selectivity factor (M.
Husain et al., 2011; M. F. Husain et al., 2010; Sakr & Gaber, 2014).
These frameworks are confronted by the large RDF graphs (M.
Husain et al., 2011; M. F. Husain et al., 2010). Therefore, the storage of a large volume of
RDF triples and the efficient query of the RDF triples are challenging and are regarded
to be critical problems in Semantic Web (M.
Husain et al., 2011; M. F. Husain et al., 2010; Sakr & Gaber, 2014).
These challenges also limit the scaling capabilities (M.
Husain et al., 2011; M. F. Husain et al., 2010; Sakr & Gaber, 2014).
RDF Store Architecture
The main purpose of the RDF store is to build a database for storing and retrieving data of any data expressed in RDF (Modoni, Sacco, & Terkaj, 2014). The term RDF store is used as an abstract for any system that can handle RDF data, allowing the ingestion of serialized RDF data and the retrieval of these data, and providing a set of APIs to facilitate the integration with other third-party application as the client application (Modoni et al., 2014). The term triple store often refers to these types of systems (Modoni et al., 2014). RDF store includes two major components; the Repository and the Middleware. The Repository represents a set of files or database (Modoni et al., 2014). The Middleware is on top of the repository and in constant communication with it (Modoni et al., 2014). Figure 2 illustrates the RDF store architecture. The Middleware has its components; Storage Provider, Query Engine, Parser/Serializer, and Client Connector (Modoni et al., 2014). The current RDF stores are categorized into three groups; database based stores, native stores, and hybrid stores (Modoni et al., 2014). Examples of the database based stores include MySQL, Oracle 12c, which are built on top of existing commercial database engines (Modoni et al., 2014). Examples of native stores are AllegroGraph, OWLIM which are built as database engines from scratch (Modoni et al., 2014). Examples of the hybrid stores are Virtuoso, and Sesame which supports architectural styles; native and DBMS-backed (Modoni et al., 2014).
Figure 2: RDF
Store Architecture (Modoni et al., 2014)
MapReduce Parallel
Processing Framework and Hadoop
In 2004, Google introduced MapReduce framework as a Parallel Processing
framework which deals with a large set of
data (Bakshi, 2012; Fadzil, Khalid, &
Manaf, 2012; White, 2012-important-buildingblocks). The MapReduce framework has gained much
popularity because it has features for hiding sophisticated operations of the
parallel processing (Fadzil et al., 2012). Various MapReduce frameworks
such as Hadoop were introduced because of the enthusiasm towards MapReduce (Fadzil et al., 2012). The capability of the MapReduce
framework was realized by different research areas such as data warehousing,
data mining, and the bioinformatics (Fadzil et al., 2012). MapReduce framework consists of
two main layers; the Distributed File System (DFS) layer to store data and the
MapReduce layer for data processing (Lee, Lee, Choi, Chung, & Moon, 2012;
Mishra, Dehuri, & Kim, 2016; Sakr & Gaber, 2014). DFS is a major feature of the MapReduce
framework (Fadzil et al., 2012).
MapReduce framework is using large clusters of low-cost
commodity hardware to lower the cost (Bakshi, 2012; H. Hu, Wen, Chua, & Li, 2014;
Inukollu, Arsi, & Ravuri, 2014; Khan et al., 2014; Krishnan, 2013; Mishra
et al., 2016; Sakr & Gaber, 2014; White, 2012-important-buildingblocks). MapReduce framework is using
“Redundant Arrays of Independent (and inexpensive) Nodes (RAIN),” whose
components are loosely coupled and when
any node goes down, there is no negative
impact on the MapReduce job (Sakr & Gaber, 2014; Yang, Dasdan,
Hsiao, & Parker, 2007). MapReduce framework involves the
“Fault-Tolerance” by applying the replication technique and allows replacing
any crashed nodes with another node without affecting the currently running job (P. Hu & Dai, 2014; Sakr & Gaber,
2014). MapReduce framework involves the automatic
support for the parallelization of execution which makes the MapReduce highly
parallel and yet abstracted (P. Hu & Dai, 2014; Sakr & Gaber,
2014).
MapReduce was introduced to solve the
problem of parallel processing of a large set
of data in a distributed environment which required manual management of the
hardware resources (Fadzil et al., 2012; Sakr & Gaber,
2014). The complexity of the parallelization is solved by using two techniques: Map/Reduce technique, and Distributed File
System (DFS) technique (Fadzil et al., 2012; Sakr & Gaber,
2014). The parallel framework must be reliable to
ensure good resource management in the distributed environment using
off-the-shelf hardware to solve the scalability issue to support any future
requirement for processing (Fadzil et al., 2012). The earlier frameworks such as
the Message Passing Interface (MPI) framework was having a reliability issue
and had a fault-tolerance issue when
processing a large set of data (Fadzil et al., 2012). MapReduce framework covers the
two categories of the scalability; the structural scalability, and the load
scalability (Fadzil et al., 2012). It addresses the structural
scalability by using the DFS which allows forming large virtual storage for the
framework by adding off-the-shelf hardware.
MapReduce framework addresses the load scalability by increasing the
number of the nodes to improve the performance (Fadzil et al., 2012).
However,
the earlier version of MapReduce framework faced challenges. Among these
challenges are the join operation and the
lack of support for aggregate functions to join multiple datasets in one task (Sakr
& Gaber, 2014).
Another limitation of the standard MapReduce framework is found in the iterative processing which is required for analysis techniques such as
PageRank algorithm, recursive relational queries, and social network analysis (Sakr
& Gaber, 2014).
The standard MapReduce does not share the execution of work to reduce
the overall amount of work (Sakr
& Gaber, 2014).
Another limitation was found in the lack of support of data index and
column storage but support only for a sequential
method when scanning the input data. Such a lack of data index affected
the query performance (Sakr
& Gaber, 2014).
Moreover, many argued that MapReduce is not regarded to be the optimal
solution for structured data. It is
known as shared-nothing architecture, which supports scalability (Bakshi,
2012; Jinquan, Jie, Shengsheng, Yan, & Yuanhao, 2012; Sakr & Gaber,
2014; White, 2012-important-buildingblocks), and the processing of large
unstructured data sets (Bakshi,
2012).
MapReduce has the limitation of performance and efficiency (Lee
et al., 2012).
Hadoop is a software framework which is derived from Big
Table and MapReduce and managed by Apache.
It was created by Doug Cutting and was named after his son’s toy
elephant (Mishra et al.,
2016). Hadoop allows applications to run on huge
clusters of commodity hardware based on MapReduce (Mishra et al.,
2016). The underlying concept of Hadoop is to allow
the parallel processing of the data across different computing nodes to speed
up computations and hide the latency (Mishra et al.,
2016). The Hadoop Distributed File System (HDFS) is
one of the major components of the Hadoop framework for storing large files (Bao, Ren, Zhang,
Zhang, & Luo, 2012; Cloud Security Alliance, 2013; De Mauro, Greco, &
Grimaldi, 2015) and allowing
access to data scattered over multiple nodes in without any exposure to the
complexity of the environment (Bao et al., 2012;
De Mauro et al., 2015). The MapReduce programming model is another major component
of the Hadoop framework (Bao
et al., 2012; Cloud Security Alliance, 2013; De Mauro et al., 2015) which is designed to implement the
distributed and parallel algorithms efficiently (De
Mauro et al., 2015).
HBase is the third component of Hadoop framework (Bao
et al., 2012).
HBase is developed on the HDFS and is a NoSQL (Not only SQL) type
database (Bao
et al., 2012).
The
key features of Hadoop include the scalability and flexibility, cost efficiency
and fault tolerance (H.
Hu et al., 2014; Khan et al., 2014; Mishra et al., 2016; Polato, Ré, Goldman,
& Kon, 2014; Sakr & Gaber, 2014).
Hadoop allows the nodes in the cluster to scale up and down based on the
computation requirements and with no change in the data formats (H.
Hu et al., 2014; Polato et al., 2014).
Hadoop also provides massively parallel computation to commodity
hardware decreasing the cost per terabyte of storage which makes the massively
parallel computation affordable when the volume of the data gets increased (H.
Hu et al., 2014).
The Hadoop technology offers the flexibility feature as it is not tight
with a schema which allows the utilization of any data either structured,
non-structures, and semi-structured, and
the aggregation of the data from multiple sources (H.
Hu et al., 2014; Polato et al., 2014).
Hadoop also allows nodes to crash without affecting the data
processing. It provides fault tolerance
environment where data and computation can be recovered without any negative
impact on the processing of the data (H.
Hu et al., 2014; Polato et al., 2014; White, 2012-important-buildingblocks).
RDF and SPARQL Using
Semantic Query
Researchers
have exerted effort in developing Semantic Web technologies which have been standardized
to address the inadequacy of the current traditional analytical techniques (M.
Husain et al., 2011; M. F. Husain et al., 2010). RDF, SPARQL
(Simple Protocol And RDF Query Language) are the most prominent standardized semantic
web technologies (M.
Husain et al., 2011; M. F. Husain et al., 2010). The Data Access Working Group (DAWG) of the
World Wide Web Consortium (W3C) in 2007 recommended SPARQL and provided
standards to be the query language for RDF, a protocol definition for sending
SPARQL queries from a client to a query processor and an XML-based serialization
format for results returned by the SPARQL query (Konstantinou,
Spanos, Stavrou, & Mitrou, 2010; Sakr & Gaber, 2014). RDF is regarded to be the standard for
storing and representing data (M.
Husain et al., 2011; M. F. Husain et al., 2010). SPARQL is the query language to retrieve data
from RDF triplestore (M.
Husain et al., 2011; M. F. Husain et al., 2010; Nicolaidis & Iniewski,
2017; Sakr & Gaber, 2014; Zeng, Yang, Wang, Shao, & Wang, 2013).
Like RDF, SPARQL is built on the “triple pattern,” which also contains
the “subject,” “predicate,” and “object” and is terminated with a full stop (Connolly
& Begg, 2015).
RDF triple is regarded to be a SPARQL triple pattern (Connolly
& Begg, 2015).
URIs are written inside angle brackets for identifying resources;
literal strings are denoted with either double or single quote; properties,
like Name, can be identified by their URI or more normally using a QName-style
syntax to improve readability (Connolly
& Begg, 2015). The triple pattern can include
variables which are not like the triple (Connolly
& Begg, 2015). Any or all of the values of
subject, predicate, and object in a triple pattern may be replaced by a
variable, which indicates data items of interest that will be returned by a
query (Connolly
& Begg, 2015).
The semantic query plays a significant role in the Semantic Web, and the standardization of SPARQL plays a significant role to achieve such semantic queries (Konstantinou et al., 2010). Unlike the traditional query languages, SPARQL does not consider the graph level, but rather it models the graph as a set of triples (Konstantinou et al., 2010). Thus, when using the SPARQL query, the graph pattern is identified, and the nodes which match this pattern are returned (Konstantinou et al., 2010; Zeng et al., 2013). SPARQL syntax is similar to SQL such as SELECT FROM WHERE syntax which is the most striking syntax (Konstantinou et al., 2010). The core syntax of SPARQL is a conjunctive set of triple patterns called as “basic graph pattern” (Zeng et al., 2013). Table 1 shows the syntax of SPARQL to retrieve data from RDF using SELECT statement.
Table 1: Example
of SPARQL syntax (Sakr & Gaber, 2014)
Although SPARQL syntax is similar to SQL
in the context of SELECT to retrieve data, SPARQL is not as mature as SQL (Konstantinou
et al., 2010).
The current form of SPARQL allows the access to the raw data using URIs
from RDF or OWL graph and letting the user perform the result processing (Konstantinou
et al., 2010).
However, SPARQL is expected to be the gateway to query information and
knowledge supporting as many features as SQL does (Konstantinou
et al., 2010).
SPARQL does not support any aggregated functions such as MAX, MIN, SUM,
AVG, COUNT, and the GROUP BY operations (Konstantinou
et al., 2010).
Moreover, SPARQL supports ORDER BY only on a global level and not solely
on the OPTIONAL part of the query (Konstantinou
et al., 2010).
For mathematical operations, SPARQL does not extend its support beyond
the basic mathematical operations (Konstantinou
et al., 2010).
SPARQL does not support the nested queries, meaning it does not allow
CONSTRUCT query in the FROM part of the query.
Moreover, SPARQL is missing the functionality offered by SELECT WHERE
LIKE statement in SQL, allowing for keyword-based queries (Konstantinou
et al., 2010).
While SPARQL offers regex() function for string pattern matching, it
cannot emulate the functionality of the LIKE operator (Konstantinou
et al., 2010).
SPARQL enables only the unbound variables in the SELECT part and
rejecting the use of functions or other operators (Konstantinou
et al., 2010). This limitation places SPARQL as
elementary query language where URIs or literals only are returned, while users
look for some result processing in the practical use cases (Konstantinou
et al., 2010).
SPARQL can be enhanced to include these missing features and
functionality to include stored procedures, triggers, and operations for data
manipulations such as update, insert, and delete (Konstantinou
et al., 2010).
There
is a group called SPARQL Working Group who are working on integrating these missing
features in SPARQL. SPARQL/Update is an
extension to SPARQL included in the leading Semantic Web development framework
“Jena” allowing the update operation, the creation and the removal of the RDF
graphs (Konstantinou
et al., 2010). ARQ is a query engine for Jena
which supports the SPARQL RDF Query language (Apache,
2017a). Some of the key features of the ARQ include
the update, the GROUP BY, access and extension of the SPARQL algebra, and
support for the federated query (Apache,
2017a). LARQ integrates SPARQL with Apache’s
full-text search framework Lucene (Konstantinou
et al., 2010) adding free text searches to SPARQL (Apache,
2017b). SPARQL+ extension of the ARC RDF sore offers
most of the common aggregates and extends the SPARUL’s INSERT with CONSTRUCT
clause (Konstantinou
et al., 2010).
The OpenLink’s Virtuoso extends SPARQL with aggregate functions, nesting,
and subqueries, allowing the user to insert SPARQL queries inside SQL (Konstantinou
et al., 2010).
SPASQL offers a similar functionality embedding SPARQL into SQL (Konstantinou
et al., 2010).
Although
SPARQL is missing a lot of SQL features, it offers other features which are not
part of SQL (Konstantinou
et al., 2010).
Some of these features include the OPTIONAL operator which does not
modify the results in case of non-existence and it can be met in almost all of
the query languages for RDF (Konstantinou
et al., 2010).
This feature is equivalent to the LEFT OUTER JOIN in SQL (Konstantinou
et al., 2010).
However, SPARQL syntax is much more user-friendly and intuitive than SQL
(Konstantinou
et al., 2010).
Techniques Applied on MapReduce
To Improve RDF Query Processing
Performance
With
the explosive growth of the data size, the traditional approach of analyzing
the data in a centralized server is not adequate to scale up (Punnoose
et al., 2012; Sakr & Gaber, 2014), and cannot scale
concerning the increasing RDF datasets (Sakr
& Gaber, 2014).
Although SPARQL is used to query RDF data, the query of RDF dataset at
the web scale is challenging because the computation of SPARQL queries requires
several joins between subsets of the dataset (Sakr
& Gaber, 2014).
New methods are introduced to improve the parallel computing and allow
storage and retrieval of RDF across large compute clusters which enables
processing data of unprecedented magnitude (Punnoose
et al., 2012).
Various solutions are introduced to solve these challenges and achieve
scalable RDF processing using the MapReduce framework such as PigSPARQL, and
RDFPath.
RDFPath
In (Przyjaciel-Zablocki, Schätzle, Hornung, & Lausen, 2011), the RDFPath is proposed as a declarative path query language for RDF which provides a natural mapping to the MapReduce programming model by design, while remaining extensible (Przyjaciel-Zablocki et al., 2011). It supports the exploration of graph properties such as shortest connections between two nodes in an RDF graph (Przyjaciel-Zablocki et al., 2011). RDFPath is regarded to be a valuable tool for the analysis of social graphs (Przyjaciel-Zablocki et al., 2011). RDFPath combines an intuitive syntax for path queries with an effective execution strategy using MapReduce (Przyjaciel-Zablocki et al., 2011). RDFPath does benefit from the horizontal scaling properties of MapReduce when adding more nodes to improve the overall executions time significantly (Przyjaciel-Zablocki et al., 2011). Using RDFPath, large RDF graphs can be handled while scaling linearly with the size of the graph that RDFPathh can be used to investigate graph properties such as a variant of the famous six degrees of separation paradigm typically encountered in social graphs (Przyjaciel-Zablocki et al., 2011). It focuses on the path queries and studies their implementation based on MapReduce. There are various RDF query languages such as RQL, SeRQL, RDQL, Triple, N3, Versa, RxPath, RPL, and SPARQL (Przyjaciel-Zablocki et al., 2011). RDFPath has a competitive expressiveness to these other RDF query languages (Przyjaciel-Zablocki et al., 2011). A comparison of RDFPath capabilities with these other RDF query language shows that RDFPath has the same capabilities of SPARQL 1.1for the adjacent nodes, adjacent edges, the degree of a node, and fixed-length path. However, RDFPath shows more capabilities than SPARQL 1.1 in areas like the distance between two nodes and shortest paths as it has partial support for these two properties. However, SPARQL 1.1 shows full support to the aggregate functions while RDFPath shows only partial support (Przyjaciel-Zablocki et al., 2011). Table 2 shows the comparison of RDFPath with other RDF query languages including SPARQL.
Table 2: Comparison of RDF Query Language, adapted from (Przyjaciel-Zablocki et al., 2011).
2. PigSPARQL
PigSPARQL
is regarded as a competitive yet easy to
use SPARQL query processing system on MapReduce that allows ad-hoc SPARQL query processing n large RDF
graphs out of the box (Schätzle, Przyjaciel-Zablocki, Hornung, & Lausen,
2013). PigSPARQL is described as a system for
processing SPARQL queries using the MapReduce framework by translating them
into Pig Latin programs where each Pig Latin program is executed by a series of
MapReduce jobs on a Hadoop cluster (Sakr & Gaber, 2014; Schätzle et al., 2013). PigSPARQL
utilizes the query language of Pig, which is a data analysis platform on top of
Hadoop MapReduce, as an intermediate layer between SPARQL and MapReduce (Schätzle et al., 2013). That intermediate layer provides an
abstraction level which makes PigSPARQL independent of Hadoop version and
accordingly ensures the compatibility to future changes of the Hadoop framework
as they will be covered by the underlying Pig layer (Schätzle et al., 2013). This intermediate layer of Pig Latin approach
provides the sustainability of PigSPARQL and is an attractive long-term
baseline for comparing various MapReduce based SPARQL implementations which are also underpinned by the competitiveness
with the existing systems such as HadoopRDF (Schätzle et al., 2013). As illustrated in Figure 3, the PigSPARQL
workflow begins with the SPARQL that is mapped to Pig Latin by parsing the
SPARQL query to generate an abstract syntax tree which is translated into a SPARQL Algebra tree (Schätzle et al., 2013). Several optimizations are applied on the
Algebra level like the early execution of filters and a re-arrangement of
triple patterns by selectivity (Schätzle et al., 2013). The optimized Algebra tree is traversed bottom-up,
and an equivalent sequence of Pig Latin
expressions are generated for every SPARQL Algebra operator (Schätzle et al., 2013). Pig automatically maps the resulting Pig
Latin script into a sequence of MapReduce iterations at the runtime (Schätzle et al., 2013).
PigSPARQL is described as easy to use and competitive baseline for the comparison of MapReduce based SPARQL processing. PigSPARQL exceeds the functionalities of most existing research prototypes with the support of SPARQL 1.0 (Schätzle et al., 2013).
Figure 3: PigSPARQL Workflow From SPARQL to MapReduce, adapted from (Schätzle et al., 2013).
3. Interactive SPARQL Query Processing on Hadoop: Sempala
In (Schätzle, Przyjaciel-Zablocki, Neu, & Lausen, 2014), an interactive SPARQL query processing techniques “Sempala” on Hadoop is proposed. Sempala is a SPARQL-over-SQL-on-Hadoop approach designed with selective queries (Schätzle et al., 2014). It shows significant performance improvements compared to existing approaches (Schätzle et al., 2014). The approach of Sempala is inspired by the trend of applying SQL-on-Hadoop field where several new systems are developed for interactive SQL query processing such as Hive, Sharl, Presto, Phoenix, Impala and so forth (Schätzle et al., 2014). Thus, Sempala as the SPARQL-over-SQL approach is introduced to follow the trend and provide interactive-time SPARQL query processing on Hadoop (Schätzle et al., 2014). With Sempala, the data is stored in RFD in a columnar layout on HDFS and use Impala, which is an open source massive parallel processing (MPP) SQL query engine for Hadoop, to serve as the execution layer on top (Schätzle et al., 2014). The architecture of Sempala is illustrated in Figure 4.
Figure 4: Sempala Architecture
adapted from (Schätzle et al., 2014).
Two main components of the architecture of the proposed Sempala; RDF Loader and Query Compiler (Schätzle et al., 2014). The RDF Loader converts an RDF dataset into the data layout used by Sempala. The Query Compiler rewrites a given SPARQL query into the SQL dialect of Impala based on the layout of the data (Schätzle et al., 2014). The Query Compiler of Sempala is based on the algebraic representation of SPARQL expressions defined by W3C recommendation (Schätzle et al., 2014). Jena ARQ is used to parse a SPARQL query into the corresponding algebra tree (Schätzle et al., 2014). Some basic algebraic optimization such as filter pushing is applied (Schätzle et al., 2014). The final step is to traverse the tree bottom up to generate the equivalent Impala SQL expressions based on the unified property table layout (Schätzle et al., 2014). In a comparison of Sempala with other Hadoop based systems such as Hive, PigSPARQL, MapMerge, and MAPSIN. Hive is the standard SQL warehouse for Hadoop based on MapReduce (Schätzle et al., 2014). The same query with minor syntactical modification can run on the same data because Impala is developed to be highly compatible with Hive (Schätzle et al., 2014). Sempala seems to follow a similar approach as PigSPARQL. However, in PigSPARQL, the Pig is used as the underlying system and intermediate level between MapReduce and SPARQL (Schätzle et al., 2014). MapMerge is an efficient map-side merge join implementation for scalable SPARQL BGP (“BasicGraphPatterns” (W3C, 2016)) which reduces the shuffling of the data between map and reduce phases in MapReduce (Schätzle et al., 2014). MAPSIN is an approach that uses HBase, which is standard NoSQL database for Hadoop to store RDF data and applies a map-side index nested loop join which avoids the reduce phase of the MapReduce (Schätzle et al., 2014). The findings of (Schätzle et al., 2014) shows that Sempala outperforms Hive and PigSPARQL, while MapMerge and MAPSIN could not be used because they only support SPARQL BGP (Schätzle et al., 2014).
4. Map-Side Index Nested Loop Join (MAPSIN JOIN)
MapReduce is
facing the challenge of processing joins because the datasets are very large (Sakr & Gaber, 2014). Two datasets can be joined using MapReduce, but they have to be located on the same
machine, which is not practical (Sakr & Gaber, 2014). Thus, solutions such as reduce-side approach are used and regarded to be the most prominent
and flexible join technique in MapReduce (Sakr & Gaber, 2014). The reduce-side
approach is also known as “Repartition Join” because datasets at the map phase are read and repartition according to the join
key at the shuffle phase, while the actual computation for join is done in the reduce phase (Sakr & Gaber, 2014). The problem with this approach is that the
datasets are transferred through the
network with no regard to the join output which can consume a lot of the
bandwidth of the network and cause bottleneck (Sakr & Gaber, 2014; Schätzle et al., 2013). Another solution called map-side join
solution is introduced, where the actual
join processing is done in the map phase to avoid the shuffle and reduce phase
and avoid transferring both datasets over the network (Sakr & Gaber, 2014). The
most common approach is the map-side merge join, although it is hard to
cascade, in addition to the advantage of avoiding the shuffle and reduce phase
is lost (Sakr & Gaber, 2014). Thus, the MAPSIN approach is proposed which is a map-side index nested
loop join based on HBase (Sakr & Gaber, 2014; Schätzle et al., 2013). The MAPSIN join has the indexing capabilities
of HBase which improves the query performance of the selective queries (Sakr & Gaber, 2014; Schätzle et al., 2013). The capabilities retain the flexibility of
reduce-side joins while utilizing the effectiveness of a map-side join without
any modification to the underlying framework (Sakr & Gaber, 2014; Schätzle et al., 2013).
Comparing MAPSIN with PigSPARQL, MAPSIN performs faster than PigSPARQL when using a sophisticated storage schema based on HBase which works well for selective queries but diminishes significantly in performance for less selective queries (Schätzle et al., 2013). However, MAPSIN does not support the queries of LUBM (Lehigh University Benchmark (W3C, 2016). The query runtime of MAPSIN is close to the runtime of the merge join approach (Schätzle et al., 2013).
5. HadoopRDF
HadoopRDF is proposed by (Tian, Du, Wang, Ni, & Yu, 2012) to combine the advantages of high fault tolerance and high throughput of the MapReduce distributed framework and the sophisticated indexing and query answering mechanism (Tian et al., 2012). HadoopRDF is developed on Hadoop cluster with many computers and echo node in the cluster has a sesame server to supply the service for storing and retrieving the RDF data (Tian et al., 2012). HadoopRDF is a MapReduce-based RDF system which stores data directly in HDFS and does not require any modification to the Hadoop framework (Przyjaciel-Zablocki et al., 2013; Sakr & Gaber, 2014; Tian et al., 2012). The basic idea is to substitute the rudimentary HDFS without indexes and a query execution engine, with more elaborated RDF stores (Tian et al., 2012). The architecture of HadoopRDF is illustrated in Figure 5.
Figure 5: HadoopRDF Architecture,
adapted from (Tian et al., 2012).
The architecture of HadoopRDF is similar to the architecture of Hadoop which scales up to thousands of nodes (Tian et al., 2012). Hadoop framework is the core of the HadoopRDF (Tian et al., 2012). Hadoop is built on top of HDFS, which is a replicated key-value store under the control of a central NameNode (Tian et al., 2012). Files in HDFS are broken into chunks fixed size, and the replica of these chunks are distributed across a group of DataNodes (Tian et al., 2012). The NameNode tracks the size and location of each replica (Tian et al., 2012). Hadoop which is a MapReduce framework is used for the computational purpose in the data-intensive application (Tian et al., 2012). In the architecture of HadoopRDF, the RDF stores are incorporated into the MapReduce framework. HadoopRDF is an advanced SPARQL engine which splits the original RDF graph according to predicates and objects and utilizes a cost-based query execution plan for reduce-side join (Przyjaciel-Zablocki et al., 2013; Sakr & Gaber, 2014; Schätzle et al., 2013). HadoopRDF can re-balance automatically when the cluster size changes but join processing is also done in the reduce phase (Przyjaciel-Zablocki et al., 2013; Sakr & Gaber, 2014). The findings of (M. Husain et al., 2011) indicated that HadoopRDF is more scalable and handles low selectivity queries more efficiently than RDF-3X. Moreover, the result showed that HadoopRDF is much more scalable than BigOWLIM and provides more efficient queries for the large data set (M. Husain et al., 2011). HadoopRDF requires a pre-processing phase like most systems (Przyjaciel-Zablocki et al., 2013; Sakr & Gaber, 2014).
6. RDF-3X: RDF Triple eXpress
RDF-3X is proposed
by (Neumann & Weikum, 2008). The RDF-3X engine is an implementation of
SPARQL which achieves excellent performance by pursuing a RISC-style
architecture with a streamlined architecture (Neumann & Weikum, 2008). RISC
is Reduced Instruction Set Computer which is a type of microprocessor
architecture that utilizes a small, highly-optimized
set of instructions, rather than a more specialized
set of instruction often found in other types of architectures (Neumann & Weikum, 2008). Thus, RDF-3X follows the concept of
RISC-style with “reduced instruction set” designed to support RDF. RDF-3X is described to be a generic solution
for storing and indexing RDF triples that eliminates
the need for physical-design turning (Neumann & Weikum, 2008). RDF-3X provides a query optimizer for
choosing optimal join orders using a cost model based on statistical synopses
for entire join paths (Neumann & Weikum, 2008). It also provides a powerful and simple query
processor which leverage fast merge joins to the large-scale data (Neumann & Weikum, 2008). Three major components in RDF-3X; physical
design, query processor, and the query
optimizer. The physical design component
is workload-independent by creating appropriate indexes over a single “giant triples
table” (Neumann & Weikum, 2008). The query processor is RISC-style by relying
mostly on merge joins over sorted index lists.
The query optimizer focuses on join order in its generation of the execution plan (Neumann & Weikum, 2008).
The findings of (Neumann & Weikum, 2008) showed that RDF-3X addressed the challenge of schema-free data and copes very well with data that exhibit a large diversity of property names (Neumann & Weikum, 2008). The optimizer of RDF-3X is known to produce efficient query execution plan (Galarraga, Hose, & Schenkel, 2014). The RDF-3X maintains local indexes for all possible orders and combinations of the triple components and for aggregations which enable efficient local data access (Galarraga et al., 2014). RDF-3X does not support LUMB. RDF-3X is a single-node RDF-store which builds indexes over all possible permutations of subject, predicate and object (Huang, Abadi, & Ren, 2011; M. Husain et al., 2011; Schätzle et al., 2014; Zeng et al., 2013). RDF-X3 is regarded to be the fastest existing semantic web repository and state-of-the-art “benchmark” engine for single place machines (M. Husain et al., 2011; Przyjaciel-Zablocki et al., 2013). Thus, it outperforms any other solution for queries with bound objects and aggregate queries (M. Husain et al., 2011). However, the performance of RDF-3X diminishes exponentially for unbound queries and queries with even simple joins if the selectivity factor is low (M. Husain et al., 2011; Przyjaciel-Zablocki et al., 2013). The experiment of (M. Husain et al., 2011) showed that RDF-3X is not only slower for such queries, it often aborts and cannot complete the query (M. Husain et al., 2011).
7. Rya: A Scalable RDF Triple Store for the Clouds
In (Punnoose et al., 2012), the Rya is proposed as a new scalable system for storing
and retrieving RDF data in cluster nodes.
In Rya, OWL model is used as a set of triples and store them in the
triple store (Punnoose et al., 2012). Storing all the data
in the triple store provides the benefits of using Hadoop MapReduce to run
large batch processing jobs against the data set (Punnoose et al., 2012). The first phase of
the process is performed only once at the time when the OWL model is loaded
into Rya (Punnoose et al., 2012). In phase 1,
MapReduce job runs to iterate through the entire graph of relationships and
output the implicit relationships found as explicit RDF triples stores into the
RDF store (Punnoose et al., 2012). The second phase of
the process is performed every time a query is run, and once all explicit and
implicit relationships are stored in Rya, the Rya query planner can expand the
query at the runtime to utilize all these relationships (Punnoose et al., 2012). Three table index
for indexing RDF triples is used to enhance the performance (Punnoose et al., 2012). The results of (Punnoose, Crainiceanu, & Rapp, 2015) showed that Rya outperformed SHARD. Moreover, in comparison
with the graph-partitioning algorithm introduced by (Huang et al., 2011), as indicated in (Punnoose et al., 2015), the performance of Rya showed superiority in many cases
over Graph Partitioning (Punnoose et al., 2015).
Conclusion
This
project provided a survey on the state-of-the-art techniques for applying MapReduce to improve the RDF data query
processing performance. Tremendous
effort from the industry and researchers have been exerted to develop efficient
and scalable RDF processing system. The
project discussed the RDF framework and
the major building blocks of the semantic web architecture. The RDF store architecture and the MapReduce
Parallel Processing Framework and Hadoop are
discussed in this project.
Researchers have exerted effort in developing Semantic Web technologies
which have been standardized to address
the inadequacy of the current traditional
analytical techniques. This paper also
discussed the most prominent standardized
semantic web technologies RDF and
SPARQL. The project also discussed and
analyzed in details various techniques applied on MapReduce to improve the RDF
query processing performance. These techniques include RDFPath, PigSPARQL,
Interactive SPARQL Query Processing on Hadoop (Sempala), Map-Side Index Nested
Loop Join (MAPSIN JOIN), HadoopRDF, RDF-3X (RDF Triple eXpress), and Rya (a
Scalable RDF Triple Store for the Clouds).
References
Apache, J. (2017a). ARQ – A SPARQL Processor for Jena
Apache, J.
(2017b). LARQ – Adding Free Text Searches
to SPARQL
Bakshi, K.
(2012). Considerations for big data:
Architecture and approach. Paper presented at the Aerospace Conference,
2012 IEEE.
Bao, Y., Ren, L.,
Zhang, L., Zhang, X., & Luo, Y. (2012). Massive
sensor data management framework in cloud manufacturing based on Hadoop.
Paper presented at the Industrial Informatics (INDIN), 2012 10th IEEE
International Conference on.
Boussaid, O.,
Tanasescu, A., Bentayeb, F., & Darmont, J. (2007). Integration and
dimensional modeling approaches for complex data warehousing. Journal of Global Optimization, 37(4),
571. doi:10.1007/s10898-006-9064-6
Choi, H., Son,
J., Cho, Y., Sung, M. K., & Chung, Y. D. (2009). SPIDER: a system for scalable, parallel/distributed evaluation of
large-scale RDF data. Paper presented at the Proceedings of the 18th ACM
conference on Information and knowledge management.
Cloud Security
Alliance. (2013). Big Data Analytics for Security Intelligence. Big Data Working Group.
Connolly, T.,
& Begg, C. (2015). Database Systems:
A Practical Approach to Design, Implementation, and Management (6th Edition
ed.): Pearson.
De Mauro, A.,
Greco, M., & Grimaldi, M. (2015). What
is big data? A consensual definition and a review of key research topics.
Paper presented at the AIP Conference Proceedings.
Fadzil, A. F. A.,
Khalid, N. E. A., & Manaf, M. (2012). Performance
of scalable off-the-shelf hardware for data-intensive parallel processing using
MapReduce. Paper presented at the Computing and Convergence Technology
(ICCCT), 2012 7th International Conference on.
Firat, M., &
Kuzu, A. (2011). Semantic web for e-learning bottlenecks: disorientation and
cognitive overload. International Journal
of Web & Semantic Technology, 2(4), 55.
Galarraga, L.,
Hose, K., & Schenkel, R. (2014). Partout:
a distributed engine for efficient RDF processing. Paper presented at the
Proceedings of the 23rd International Conference on World Wide Web.
Hu, H., Wen, Y.,
Chua, T., & Li, X. (2014). Toward Scalable Systems for Big Data Analytics:
A Technology Tutorial. Practical
Innovation, Open Solution, 2, 652-687. doi:10.1109/ACCESS.2014.2332453
Hu, P., &
Dai, W. (2014). Enhancing fault tolerance based on Hadoop cluster. International Journal of Database Theory and
Application, 7(1), 37-48.
Huang, J., Abadi,
D. J., & Ren, K. (2011). Scalable SPARQL querying of large RDF graphs. Proceedings of the VLDB Endowment, 4(11),
1123-1134.
Husain, M.,
McGlothlin, J., Masud, M. M., Khan, L., & Thuraisingham, B. M. (2011).
Heuristics-based query processing for large RDF graphs using cloud computing. IEEE transactions on knowledge and data
engineering, 23(9), 1312-1327.
Husain, M. F.,
Khan, L., Kantarcioglu, M., & Thuraisingham, B. (2010). Data intensive query processing for large
RDF graphs using cloud computing tools. Paper presented at the Cloud
Computing (CLOUD), 2010 IEEE 3rd International Conference on.
Inukollu, V. N.,
Arsi, S., & Ravuri, S. R. (2014). Security Issues Associated with Big Data
in Cloud Computing. International Journal
of Network Security & Its Applications, 6(3), 45.
doi:10.5121/ijnsa.2014.6304
Jinquan, D., Jie,
H., Shengsheng, H., Yan, L., & Yuanhao, S. (2012). The Hadoop Stack: New
Paradigm for Big Data Storage and Processing. Intel Technology Journal, 16(4), 92-110.
Khan, N., Yaqoob,
I., Hashem, I. A. T., Inayat, Z., Ali, M. W. K., Alam, M., . . . Gani, A.
(2014). Big Data: Survey, Technologies, Opportunities, and Challenges. The Scientific World Journal, 1-18.
doi:10.1155/2014/712826
Konstantinou, N.,
Spanos, D.-E., Stavrou, P., & Mitrou, N. (2010). Technically approaching
the semantic web bottleneck. International
Journal of Web Engineering and Technology, 6(1), 83-111.
Krishnan, K.
(2013). Data warehousing in the age of
big data: Newnes.
Lee, K.-H., Lee,
Y.-J., Choi, H., Chung, Y. D., & Moon, B. (2012). Parallel data processing
with MapReduce: a survey. ACM SIGMOD
Record, 40(4), 11-20.
Mishra, B. S. P.,
Dehuri, S., & Kim, E. (2016). Techniques
and Environments for Big Data Analysis: Parallel, Cloud, and Grid Computing
(Vol. 17): Springer.
Modoni, G. E.,
Sacco, M., & Terkaj, W. (2014). A
survey of RDF store solutions. Paper presented at the Engineering,
Technology and Innovation (ICE), 2014 International ICE Conference on.
Myung, J., Yeon,
J., & Lee, S.-g. (2010). SPARQL basic
graph pattern processing with iterative MapReduce. Paper presented at the Proceedings
of the 2010 Workshop on Massive Data Analytics on the Cloud.
Neumann, T.,
& Weikum, G. (2008). RDF-3X: a RISC-style engine for RDF. Proceedings of the VLDB Endowment, 1(1),
647-659.
Nicolaidis, I.,
& Iniewski, K. (2017). Building
Sensor Networks: CRC Press.
Polato, I., Ré,
R., Goldman, A., & Kon, F. (2014). A comprehensive view of Hadoop
research—A systematic literature review. Journal
of Network and Computer Applications, 46, 1-25.
Przyjaciel-Zablocki,
M., Schätzle, A., Hornung, T., & Lausen, G. (2011). Rdfpath: Path query processing on large rdf graphs with mapreduce.
Paper presented at the Extended Semantic Web Conference.
Przyjaciel-Zablocki,
M., Schätzle, A., Skaley, E., Hornung, T., & Lausen, G. (2013). Map-side merge joins for scalable SPARQL BGP
processing. Paper presented at the Cloud Computing Technology and Science
(CloudCom), 2013 IEEE 5th International Conference on.
Punnoose, R.,
Crainiceanu, A., & Rapp, D. (2012). Rya:
a scalable RDF triple store for the clouds. Paper presented at the
Proceedings of the 1st International Workshop on Cloud Intelligence.
Punnoose, R.,
Crainiceanu, A., & Rapp, D. (2015). SPARQL in the cloud using Rya. Information Systems, 48, 181-195.
Sakr, S., &
Gaber, M. (2014). Large Scale and big
data: Processing and Management: CRC Press.
Schätzle, A.,
Przyjaciel-Zablocki, M., Hornung, T., & Lausen, G. (2013). PigSPARQL: a SPARQL query processing
baseline for big data. Paper presented at the Proceedings of the 12th
International Semantic Web Conference (Posters & Demonstrations
Track)-Volume 1035.
Schätzle, A.,
Przyjaciel-Zablocki, M., Neu, A., & Lausen, G. (2014). Sempala: interactive SPARQL query processing on hadoop. Paper
presented at the International Semantic Web Conference.
Sun, Y., &
Jara, A. J. (2014). An extensible and active semantic model of information
organizing for the Internet of Things. Personal
and Ubiquitous Computing, 18(8), 1821-1833. doi:10.1007/s00779-014-0786-z
Tian, Y., Du, J.,
Wang, H., Ni, Y., & Yu, Y. (2012). Hadooprdf: A scalable rdf data analysis
system. 8th ICIC, 633-641.
Tiwana, A., &
Balasubramaniam, R. (2001). Integrating knowledge on the web. IEEE Internet Computing, 5(3), 32-39.
White, T. (2012-important-buildingblocks).
Hadoop: The definitive guide: ”
O’Reilly Media, Inc.”.
Yang, H.-c.,
Dasdan, A., Hsiao, R.-L., & Parker, D. S. (2007). Map-reduce-merge: simplified relational data processing on large
clusters. Paper presented at the Proceedings of the 2007 ACM SIGMOD
international conference on Management of data.
Zeng,
K., Yang, J., Wang, H., Shao, B., & Wang, Z. (2013). A distributed graph engine for web scale RDF data. Paper presented
at the Proceedings of the VLDB Endowment.
Hadoop was developed by Yahoo and Apache to run jobs
in hundreds of terabytes of data (Yan, Yang, Yu, Li, & Li, 2012). A
various large corporation such as Facebook, Amazon have used Hadoop as
it offers high efficiency, high scalability, and high reliability (Yan et al., 2012). Hadoop has faced various
limitation such as low-level programming paradigm and schema, strictly batch
processing, time skew and incremental computation (Alam & Ahmed, 2014). The incremental computation is
regarded to be one of the major shortcomings of Hadoop technology (Alam & Ahmed, 2014). The efficiency on handling
incremented data is at the expense of losing the incompatibility with
programming models which are offered by
non-incremental systems such as MapReduce, which requires the implementation of
incremental algorithms and increasing the
complexity of the algorithm and the code (Alam & Ahmed, 2014). The caching technique is
proposed by (Alam & Ahmed, 2014) as a solution. This caching
solution will be at three levels; the Job, the Task and the Hardware (Alam & Ahmed, 2014).
Incoop is another solution proposed by (Bhatotia, Wieder, Rodrigues, Acar, &
Pasquin, 2011). The Incoop proposed solution is to extend
the open-source implementation of Hadoop of MapReduce programming paradigm to
run unmodified MapReduce program in an incremental method (Bhatotia et al., 2011; Sakr & Gaber,
2014). Incoop allows programmers to increment the
MapReduce programs automatically without any modification to the code (Bhatotia et al., 2011; Sakr & Gaber,
2014). Moreover, information about the previously
executed MapReduce tasks are recorded by Incoop to be reused in subsequent
MapReduce computation when possible (Bhatotia et al., 2011; Sakr & Gaber,
2014).
The Incoop is not a perfect solution, and it has some shortcomings which are
addressed by (Sakr & Gaber, 2014; Zhang, Chen,
Wang, & Yu, 2015). Some enhancements are implemented to Incoop
to include incremental HDFS called Inc-HDFS, Contraction Phase, and “Memoization-aware
Scheduler” (Sakr & Gaber, 2014). The Inc-HDFS provides the delta
technique in the inputs of two consecutive job runs and splits the input based
on the contents where the compatibility with HDFS is maintained. The
Contraction phase is a new phase in the MapReduce framework consisting of
breaking up the Reduce tasks into smaller sub-computation
forming an inverted tree allowing the small portion of the input changes
to the path from the corresponding leaf
to the root to be computed (Sakr & Gaber, 2014). The Memoization-aware Scheduler
is a modified version of the scheduler of
Hadoop taking advantage of the locality of memorized results (Sakr & Gaber, 2014).
Another solution called i2MapReduce proposed by (Zhang et al., 2015) which was compared to Incoop by (Zhang et al., 2015). The i2MapReduce does
not perform the task-level computation but rather
a key-value pair level incremental processing. This solution also supports more complex
iterative computation, which is used in data mining and reduces the I/O
overhead by applying various techniques (Zhang et al., 2015). IncMR is an enhanced framework
for the large-scale incremental data processing (Yan et al., 2012). It inherits the simplicity of
the standard MapReduce, it does not modify HDFS
and utilizes the same APIs of the MapReduce (Yan et al., 2012). When using IncMR, all programs
can complete incremental data processing without any modification (Yan et al., 2012).
In conclusion, various efforts are exerted by
researchers to overcome the incremental computation limitation of Hadoop, such
as Incoop, Inc-HDFS, i2MapReduce, and IncMR. Each proposed solution is an attempt to
enhance and extend the standard Hadoop to avoid overheads such as I/O, to
increase the efficiency, and without increasing the complexing of the
computation and without causing any modification to the code.
References
Alam, A., & Ahmed, J. (2014). Hadoop architecture and its issues.
Paper presented at the Computational Science and Computational Intelligence
(CSCI), 2014 International Conference on.
Bhatotia, P.,
Wieder, A., Rodrigues, R., Acar, U. A., & Pasquin, R. (2011). Incoop: MapReduce for incremental
computations. Paper presented at the Proceedings of the 2nd ACM Symposium
on Cloud Computing.
Sakr, S., &
Gaber, M. (2014). Large Scale and big
data: Processing and Management: CRC Press.
Yan, C., Yang,
X., Yu, Z., Li, M., & Li, X. (2012). Income:
Incremental data processing based on MapReduce. Paper presented at the
Cloud Computing (CLOUD), 2012 IEEE 5th International Conference on.
Zhang,
Y., Chen, S., Wang, Q., & Yu, G. (2015). i^2MapReduce: Incremental
MapReduce for Mining Evolving Big Data. IEEE
transactions on knowledge and data engineering, 27(7), 1906-1919.
The standard MapReduce framework faced the challenge
of the iterative computation which is required
in various operations such as data mining, PageRank, network traffic analysis, graph
analysis, social network analysis, and so forth (Bu, Howe, Balazinska, & Ernst, 2010;
Sakr & Gaber, 2014). These analyses techniques require the data to
be processed iteratively until the computation satisfies a convergence or
stropping condition (Bu et al., 2010; Sakr & Gaber, 2014). Due to this limitation, and to
this critical requirement, this iterative process is implemented and executed
manually using a driver program when using the standard MapReduce framework (Bu et al., 2010; Sakr & Gaber, 2014). However, the manual
implementation and execution of such iterative computation have two major
problems (Bu et al., 2010; Sakr & Gaber, 2014). The first problem is reflected
in loading unchanged data from iteration to iteration wasting input/output
(I/O), network bandwidth, and CPU resources (Bu et al., 2010; Sakr & Gaber, 2014). The second problem is reflected in the overhead of the termination
condition when the output of the application did
not change for two consecutive iterations and reached a fixed point (Bu et al., 2010; Sakr & Gaber, 2014). This termination condition may
require an extra MapReduce job on each iteration which causes overhead for
scheduling extra tasks, reading extra data from disk, and moving data across
the network (Bu et al., 2010; Sakr & Gaber, 2014).
Researchers exerted efforts to
solve the iterative computation.
HaLoop is proposed by (Bu et al., 2010), and Twister by (Ekanayake et al., 2010), Pregel by (Malewicz et al., 2010). One solution to the iterative
computation limitation, as the case in HaLoop by (Bu et al., 2010) and Twister by (Ekanayake et al., 2010) are to identify and keep invariant
data during the iterations, where reading unnecessary data repeatedly is avoided. The HaLoop by (Bu et al., 2010) implemented two caching functionalities (Bu et al., 2010; Sakr & Gaber, 2014). The first caching technique is implemented on
the invariant data in the first iteration and reusing them in a later iteration. The second caching technique
is implemented on the outputs of reducer making the check for the fixpoint more
efficient without adding any extra MapReduce job (Bu et al., 2010; Sakr & Gaber, 2014).
The solution of Pregel by (Malewicz et al., 2010) is more focused on the graph and was inspired by the Bulk Synchronous
Parallel model (Malewicz et al., 2010). This solution provides the
synchronous computation and communication (Malewicz et al., 2010) and uses explicit messaging approach to acquire remote information and
does not replicate remote values locally (Malewicz et al., 2010). Mahoot is another solution that
was introduced to solve the iterative computing by grouping a series of chained
jobs to obtain the results (Polato, Ré, Goldman, & Kon, 2014). In Mahoot solution, the result
of each job is pushed into the next job until the final results are obtained (Polato et al., 2014). The iHadoop proposed by (Elnikety, Elsayed, & Ramadan, 2011) schedules iterations asynchronously and connects the output of one
iteration to the next allowing both to process their data concurrently (Elnikety et al., 2011). The task scheduler of the iHadoop utilizes the inter-iteration data
locality by scheduling tasks that exhibit a producer/consumer relation on the
same physical machine allowing a fast transfer of the local data (Elnikety et al., 2011).
Apache Hadoop and Apache Spark are the most popular
technology for the iterative computation using in-memory data processing engine
(Liang, Li, Wang, & Hu, 2011). Hadoop defines the iterative
computation as a series of MapReduce jobs where each job reads the data from Hadoop Distributed File System (HDFS)
independently, processes the data, and writes the data back to HDFS (Liang et al., 2011). Dacoop was proposed by Liang as an extension
to Hadoop to handle the data-iterative applications, by using cache technique
for repeatedly data processing and introducing shared memory-based data cache
mechanism (Liang et al., 2011). The iMapReduce is another solution proposed by (Zhang, Gao, Gao, & Wang, 2012) to provide support of iterative processing implementing the persistent
tasks of the map and reduce during the
whole iterative process and how the persistent tasks are terminated (Zhang et al., 2012). The iMapReduce avoid three major overheads. The first overhead is the job startup
overhead which is avoided by building an
internal loop from reduce to map within a
job. The second overhead is the communication overhead which is avoided by separating the iterated state
data from the static structure data. The
third overhead is the synchronization overhead which is avoided by allowing
asynchronous map task execution (Zhang et al., 2012).
References
Bu, Y., Howe, B., Balazinska, M.,
& Ernst, M. D. (2010). HaLoop: Efficient iterative data processing on large
clusters. Proceedings of the VLDB
Endowment, 3(1-2), 285-296.
Ekanayake, J.,
Li, H., Zhang, B., Gunarathne, T., Bae, S.-H., Qiu, J., & Fox, G. (2010). Twister: a runtime for iterative MapReduce.
Paper presented at the Proceedings of the 19th ACM international symposium on
high performance distributed computing.
Elnikety, E.,
Elsayed, T., & Ramadan, H. E. (2011). iHadoop:
asynchronous iterations for MapReduce. Paper presented at the Cloud
Computing Technology and Science (CloudCom), 2011 IEEE Third International
Conference on.
Liang, Y., Li,
G., Wang, L., & Hu, Y. (2011). Dacoop:
Accelerating data-iterative applications on Map/Reduce cluster. Paper
presented at the Parallel and Distributed Computing, Applications, and
Technologies (PDCAT), 2011 12th International Conference on.
Malewicz, G.,
Austern, M. H., Bik, A. J., Dehnert, J. C., Horn, I., Leiser, N., &
Czajkowski, G. (2010). Pregel: a system
for large-scale graph processing. Paper presented at the Proceedings of the
2010 ACM SIGMOD International Conference on Management of data.
Polato, I., Ré,
R., Goldman, A., & Kon, F. (2014). A comprehensive view of Hadoop
research—A systematic literature review. Journal
of Network and Computer Applications, 46, 1-25.
Sakr, S., &
Gaber, M. (2014). Large Scale and big
data: Processing and Management: CRC Press.
Zhang,
Y., Gao, Q., Gao, L., & Wang, C. (2012). imapreduce: A distributed
computing framework for iterative computation. Journal of Grid Computing, 10(1), 47-68.
In 2004, Google introduced MapReduce framework as a
Parallel Processing framework which deals with large set of data (Bakshi, 2012; Fadzil, Khalid, &
Manaf, 2012; White, 2012). The MapReduce framework has gained much
popularity because it has features for hiding sophisticated operations of the
parallel processing (Fadzil et al., 2012). Various MapReduce frameworks
such as Hadoop were introduced because of the enthusiasm towards MapReduce (Fadzil et al., 2012).
The capability of the MapReduce framework was
realized by different research areas such as data warehousing, data mining, and
the bioinformatics (Fadzil et al., 2012). MapReduce framework consists of
two main layers; the Distributed File System (DFS) layer to store data and the
MapReduce layer for data processing (Lee, Lee, Choi, Chung, & Moon, 2012;
Mishra, Dehuri, & Kim, 2016; Sakr & Gaber, 2014). DFS is a major feature of the MapReduce framework
(Fadzil et al., 2012).
MapReduce framework is using large clusters of
low-cost commodity hardware to lower the cost (Bakshi, 2012; H. Hu, Wen, Chua, & Li,
2014; Inukollu, Arsi, & Ravuri, 2014; Khan et al., 2014; Krishnan, 2013;
Mishra et al., 2016; Sakr & Gaber, 2014; White, 2012). MapReduce framework is using “Redundant
Arrays of Independent (and inexpensive) Nodes (RAIN),” whose components are
loosely coupled and when any node goes down there is no negative impact on the
MapReduce job (Sakr & Gaber, 2014; Yang, Dasdan,
Hsiao, & Parker, 2007). MapReduce framework involves the
“Fault-Tolerance” by applying the replication technique and allows replacing
any crashed nodes with another node without affecting the current running job (P. Hu & Dai, 2014-7; Sakr &
Gaber, 2014). MapReduce framework involves the automatic
support for the parallelization of execution which makes the MapReduce highly
parallel and yet abstracted (P. Hu & Dai, 2014-7; Sakr &
Gaber, 2014).
The Top Three Features of
Hadoop
The Hadoop
Distributed File System (HDFS) is one of the major components of the Hadoop
framework for storing large files (Bao, Ren, Zhang, Zhang, & Luo, 2012;
CSA, 2013; De Mauro, Greco, & Grimaldi, 2015) and allowing access to data scattered over
multiple nodes in without any exposure to the complexity of the environment (Bao et al., 2012; De Mauro et al., 2015). The MapReduce programming model is another major component
of the Hadoop framework (Bao et al., 2012; CSA, 2013;
De Mauro et al., 2015)
which is designed to implement the distributed and parallel algorithms
efficiently (De Mauro et al., 2015). HBase is the third
component of Hadoop framework (Bao et al., 2012). HBase is developed
on the HDFS and is a NoSQL (Not only SQL) type database (Bao et al., 2012).
The key features of Hadoop include
the scalability and flexibility, cost efficiency and fault tolerance (H. Hu et al., 2014; Khan et
al., 2014; Mishra et al., 2016; Polato, Ré, Goldman, & Kon, 2014; Sakr
& Gaber, 2014). Hadoop allows the nodes in the cluster to
scale up and down based on the computation requirements and with no change in
the data formats (H. Hu et al., 2014; Polato
et al., 2014). Hadoop also provides massively parallel
computation to commodity hardware decreasing the cost per terabyte of storage
which makes the massively parallel computation affordable when the volume of
the data gets increased (H. Hu et al., 2014). The Hadoop technology
offers the flexibility feature as it is not tight with a schema which allows
the utilization of any data either structured, non-structures, and semi-structured, and the aggregation of the
data from multiple sources (H. Hu et al., 2014; Polato
et al., 2014). Hadoop also allows nodes to crash without
affecting the data processing. It
provides fault tolerance environment where data and computation can be
recovered without any negative impact on the processing of the data (H. Hu et al., 2014; Polato
et al., 2014; White, 2012).
Pros and Cons of MapReduce Framework
MapReduce was introduced to solve the problem of parallel processing of a
large set of data in a distributed
environment which required manual management of the hardware resources (Fadzil et al., 2012; Sakr & Gaber, 2014).
The complexity of the parallelization is
solved by using two techniques:
Map/Reduce technique, and Distributed File System (DFS) technique (Fadzil et al., 2012; Sakr & Gaber, 2014).
The parallel framework must be reliable to ensure good resource
management in the distributed environment using off-the-shelf hardware to solve
the scalability issue to support any future requirement for processing (Fadzil et al., 2012).
The earlier frameworks such as the Message Passing Interface (MPI)
framework was having a reliability issue and had a fault-tolerance issue when processing a large set of data (Fadzil et al., 2012).
MapReduce framework covers the two categories of the scalability; the
structural scalability, and the load scalability (Fadzil et al., 2012).
It addresses the structural scalability by using the DFS which allows
forming large virtual storage for the framework by adding off-the-shelf
hardware. MapReduce framework addresses
the load scalability by increasing the number of the nodes to improve the
performance (Fadzil et al., 2012).
However, the earlier version of
MapReduce framework faced challenges. Among these challenges are the join operation and the lack of support
for aggregate functions to join multiple datasets
in one task (Sakr & Gaber, 2014). Another limitation
of the standard MapReduce framework is found
in the iterative processing which is required
for analysis techniques such as PageRank algorithm, recursive relational
queries, and social network analysis (Sakr & Gaber, 2014). The standard
MapReduce does not share the execution of work to reduce the overall amount of
work (Sakr & Gaber, 2014). Another limitation
was found in the lack of support of data index and column storage but support
only for a sequential method when
scanning the input data. Such a lack of data index affected the query
performance (Sakr & Gaber, 2014). Moreover, many
argued that MapReduce is not regarded to be the optimal solution for structured
data. It is known as shared-nothing
architecture, which supports scalability (Bakshi, 2012; Jinquan, Jie,
Shengsheng, Yan, & Yuanhao, 2012; Sakr & Gaber, 2014; White, 2012),
and the processing of large unstructured data sets (Bakshi, 2012). MapReduce has the
limitation of performance and efficiency (Lee et al., 2012).
References
Bakshi, K. (2012, 3-10 March 2012). Considerations for big data: Architecture
and approach. Paper presented at the Aerospace Conference, 2012 IEEE.
Bao, Y., Ren, L.,
Zhang, L., Zhang, X., & Luo, Y. (2012). Massive
sensor data management framework in cloud manufacturing based on Hadoop.
Paper presented at the Industrial Informatics (INDIN), 2012 10th IEEE
International Conference on.
CSA, C. S. A.
(2013). Big Data Analytics for Security Intelligence. Big Data Working Group.
De Mauro, A.,
Greco, M., & Grimaldi, M. (2015). What
is big data? A consensual definition and a review of key research topics.
Paper presented at the AIP Conference Proceedings.
Fadzil, A. F. A.,
Khalid, N. E. A., & Manaf, M. (2012). Performance
of scalable off-the-shelf hardware for data-intensive parallel processing using
MapReduce. Paper presented at the Computing and Convergence Technology
(ICCCT), 2012 7th International Conference on.
Hu, H., Wen, Y.,
Chua, T.-S., & Li, X. (2014). Toward scalable systems for big data
analytics: A technology tutorial. IEEE
Access, 2, 652-687.
Hu, P., &
Dai, W. (2014-7). Enhancing fault tolerance based on Hadoop cluster. International Journal of Database Theory and
Application, 7(1), 37-48.
Inukollu, V. N.,
Arsi, S., & Ravuri, S. R. (2014). Security issues associated with big data
in cloud computing. International Journal
of Network Security & Its Applications, 6(3), 45.
Jinquan, D., Jie,
H., Shengsheng, H., Yan, L., & Yuanhao, S. (2012). The Hadoop Stack: New
Paradigm for Big Data Storage and Processing. Intel Technology Journal, 16(4), 92-110.
Khan, N., Yaqoob,
I., Hashem, I. A. T., Inayat, Z., Mahmoud Ali, W. K., Alam, M., . . . Gani, A.
(2014). Big Data: Survey, Technologies, Opportunities, and Challenges. The Scientific World Journal, 2014.
Krishnan, K.
(2013). Data warehousing in the age of
big data: Newnes.
Lee, K.-H., Lee,
Y.-J., Choi, H., Chung, Y. D., & Moon, B. (2012). Parallel data processing
with MapReduce: a survey. ACM SIGMOD
Record, 40(4), 11-20.
Mishra, B. S. P.,
Dehuri, S., & Kim, E. (2016). Techniques
and Environments for Big Data Analysis: Parallel, Cloud, and Grid Computing
(Vol. 17): Springer.
Polato, I., Ré,
R., Goldman, A., & Kon, F. (2014). A comprehensive view of Hadoop
research—A systematic literature review. Journal
of Network and Computer Applications, 46, 1-25.
Sakr, S., &
Gaber, M. (2014). Large Scale and big
data: Processing and Management: CRC Press.
White, T. (2012).
Hadoop: The definitive guide: ”
O’Reilly Media, Inc.”.
Yang,
H.-c., Dasdan, A., Hsiao, R.-L., & Parker, D. S. (2007). Map-reduce-merge: simplified relational data
processing on large clusters. Paper presented at the Proceedings of the
2007 ACM SIGMOD international conference on Management of data.
Keywords: World Wide Web, Web, Performance
Bottlenecks, Large-Scale Data.
Introduction
The
journey of the Web starting with Web 1.0 is known as the “Web of Information
Connections,” followed by Web 2.0 which is is known as “Web of People
Connections” (Aghaei,
Nematbakhsh, & Farsani, 2012). Web 3.0 is known as “Web of Knowledge
Connections, “Web 4.0 is known as the “Web of Intelligence Connections” (Aghaei
et al., 2012).
Web 5.0 is known as “Symbionet Web” (Patel,
2013).
This project discusses
this journey of the Web starting from Web 1.0 until Web 5.0. The inception of the World Wide Web (W3)
known as the “Web” goes back to 1989 when Berners-Lee introduced it through a
project for CERN. The underlying concept
behind the Web is hypertext paradigm which links documents together. The project was the starting point to change
the way we communicate with each other.
Web
1.0 is the first generation of the Web, and it was read-only, with no
interaction with the users. It was used to broadcast information to the
users. It used the simple framework of
Client/Server which is known as a single point of failure. Web 2.0 was introduced in 2004 by Tim
O’Reilly as a platform which allows read-write and interaction of users. The topology of Web 2.0 is Peer-To-Peer to
avoid the single point of the failure in Web 1.0. All nodes are serving as server and client
and have the same capabilities to respond to users requests. The topology of Web 2.0 Peer-to-Peer is
called Master/Slave. Web 3.0 was introduced
by Markoff of New York Times in 2006 and is known as the Semantic Web. Berners-Lee introduced the concept of the
Semantic Web in 2001. The Semantic Web
has a layered architecture including URIs, RDF, Ontology Web Language (OWL),
XML and other components. Web 4.0 and
Web 5.0 are still in progress. Web 4.0
is known as the “Intelligent Web,” while Web 5.0 is known as “Symbionet
Web.” It is expected that the Artificial
Intelligence will play a key role in Web 4.0, and consequently Web 5.0. The project addressed the main sources for
the large-scale data in each Web generation.
Moroever, the key technologies and the underlying architecture and
framework for each Web generation are also discussed in this paper.
The project also discussed and
analyzed the bottleneck and the performance of the Web for each Web generation
from Client/Server simple topology of Web 1.0 to Peer-To-Peer of Web 2.0
topology, to the layered topology of Semantic Web of Web 3.0. Moreover, the bottleneck is also discussed
for Web 4.0 using the Internet of Things technology. Each generation has added tremendous value to
our lives and how we communicate with each.
Web 1.0 – The Universal
Access to Read-Only Static Pages
Web
1.0 is the first generation of the World Wide Web (W3), known as the Web (Aghaei
et al., 2012; Choudhury, 2014; Kujur & Chhetri, 2015; Patel, 2013).
The inception of the W3 project took place in CERTN in 1989 to enhance
the effectiveness of the CERN communication system (Kujur
& Chhetri, 2015).
Berners-Lee realized this hypertext paradigm could be applied globally (Kujur
& Chhetri, 2015). The W3 project allowed access to the
information online (T.
J. Berners-Lee, 1992).
The term “Web” for the world goes to the similarities for the
construction of a spider (T.
J. Berners-Lee, 1992).
The
underlying concept of W3 was using hypertext paradigm, through which documents
are referring to each using links (T.
J. Berners-Lee, 1992).
The user can access the document from that link universally (T.
J. Berners-Lee, 1992).
The user can create documents and link them into the Web using the
hypertext (T.
J. Berners-Lee, 1992).
If the data is stored in the database, the server can be modified to
access the database from W3 clients and present it to the Web, as the case with
the generic Oracle server using the SQL SELECT statement (T.
J. Berners-Lee, 1992).
Large sets of structured data such as the database cannot be handled by
Web 1.0 hypertext alone (T.
J. Berners-Lee, 1992).
The solution for this limitation is to add “search” functionality to the
hypertext paradigm (T.
J. Berners-Lee, 1992).
The indexes, which are regarded to be “special documents,” can be used
for the search where the user can provide a keyword that results in that
“special document” or “index” which has a link to the documents found as a
result of that keyword (T.
J. Berners-Lee, 1992). The
phone book was the first document which was published on the Web (T.
Berners-Lee, 1996; T. J. Berners-Lee, 1992).
Berners-Lee
is regarded to be the innovator of the Web 1.0 (Aghaei
et al., 2012; Choudhury, 2014; Kujur & Chhetri, 2015). Web 1.0 is defined as “It is an information
space in which the items of interest referred to as resources are identified by
a global identifier called as Unifrom Resource Identifiers (URIs)” (Kujur
& Chhetri, 2015; Patel, 2013). Web
1.0 was read-only passive Web with no interaction with the websites (Choudhury,
2014).
The content of the data and the data
management are the sole responsibility of the webmaster. In the
1990s, the data sources included digital technology and database systems which
organizations widely adopted storing a large amount of data, such as bank
trading transactions, shopping mall records, and government sector archives (Hu,
Wen, Chua, & Li, 2014). Companies such as Google and Yahoo began to
develop search functions and portals to information for users (Kambil,
2008). Web 1.0 lasted from 1989 until 2005 (Kujur
& Chhetri, 2015; Patel, 2013). Example of Web 1.0 includes the “Britannica
Online” which provide information for read-only (Loretz,
2017).
Key
Technologies of Web 1.0
The key protocols
for Web 1.0 are HyperText Markup Language (HTML), HyperText Transfer Protocol
(HTTP), and Universal Resource Identifier (URI) (Choudhury,
2014; Patel, 2013).
New protocols include XML,
XHTML. The Cascading Style Sheet (CSS)
Server-Side Scripting include ASP, PHP, JSP, CGI, and Perl (Patel,
2013). The Client-Side Scripting include JavaScript,
VBScript, and Flash (Patel,
2013).
Web
1.0 Architecture
The underlying
architecture of the Web 1.0 is Client/Server topology where the Server
retrieves data responding to the client requests where the browser is residing (T.
J. Berners-Lee, 1992). A common library of the information access
code of the network is shared by the clients
(T.
J. Berners-Lee, 1992). The servers existed at the time of W3 project
were Files, VMS/Help, Oracle, and GNU Info (T.
J. Berners-Lee, 1992).
The Client/Server topology is described as a single point of failure as
there is a total dependency on the server (Markatos,
2002).
Web
1.0 Performance Bottleneck
Web
1.0 framework consists of a web server, clients which are connected to the
server using the internet (Mosberger
& Jin, 1998).
HTTP is the protocol that connects the client and the server (Mosberger
& Jin, 1998).
In (Mosberger
& Jin, 1998), httperf tool was used to test the
load and the performance of the web server which responds to several client requests
(Mosberger
& Jin, 1998).
The httperf tool has two main goals (Mosberger
& Jin, 1998). The first goal is about the good
and predictable performance. The second
goal is about the “ease of extensibility” (Mosberger
& Jin, 1998).
Load sustainability is a key factor in a good performance of the web
server (Mosberger
& Jin, 1998).
There are various client performance limits which should not be regarded
as server performance limits (Mosberger
& Jin, 1998).
The client CPU imposes a limitation on the client (Mosberger
& Jin, 1998).
The size of the Transmission Transfer Protocol (TCP) port space whose
numbers are sixteen bits wide. Privilege
process reserve 1,024 of the 64K available ports. The port cannot be reused until it gets
expired. Thus, the TCP TIME_WAIT plays a role as its expired state allows the
port to be reused (Mosberger
& Jin, 1998). This scenario can cause a serious limit and
bottleneck for client sustainable offered rate (Mosberger
& Jin, 1998).
With one minute timeout, the sustainable rate is about 1,075 requests
per seconds. However, with the recommended value of RFC-793 to be four-minute time
out, the maximum rate would be 268 requests per second instead (Mosberger
& Jin, 1998).
The total and the per-process number of file descriptors that can be
opened are limited in most operating systems (Mosberger
& Jin, 1998).
The “per-process limits” is ranged from 256 to 2,048. The file descriptor cannot be used until it is
closed, the httperf timeout value plays a role in the number of the open file
descriptors. If the client confronts
with a bottleneck, the operating system of the client can be tuned to increase
the limit of the open file descriptors (Mosberger
& Jin, 1998).
The TCP connection typically has
a “socket receive” and “send buffer” (Mosberger
& Jin, 1998).
The clients loads are limited to the clients’ memory available for the
“socket receive” (Mosberger
& Jin, 1998).
Concurrent TCP connections can cause a bottleneck and poor performance (Mosberger
& Jin, 1998).
For
the server side performance, the granularity of the process scheduling in
operating systems is measured in millisecond ranges and plays a key role in the
performance of the server responding to several requests from several clients (Mosberger
& Jin, 1998).
Tools such as httperf check the network activity for input and output
using select() functions and monitor the real-time using gettimeofday()
functions (Mosberger
& Jin, 1998).
The limited number of the ephemeral ports is ranged from 1,024 to 5,000
which can cause a problem when running out of ports (Mosberger
& Jin, 1998).
Tools such as httperf re-use the ports as soon as they are
released. However, the incompatibility
of the TCP between Unix and NT broke this solution where Unix allows pre-empting
the TIME_WAIT state, while NT did not allow it during the arrival of the SYN
segment (Mosberger
& Jin, 1998).
Allocating the ports using round-robin method solves this problem. Several thousand TCP control blocks can
cause slow system calls (Mosberger
& Jin, 1998). The hash table is usually used to look up the
TCP control blocks for incoming network traffic is standard for execution time (Mosberger
& Jin, 1998).
However, some BSD-derived systems still use linear control block search
for the bind() and connect() system calls, which can increase the slow system
calls. The solution was found when
system closes the connection. Thus,
tools such as httperf applied the concept of closing the connection by using
RESET (Mosberger
& Jin, 1998).
Web 2.0 – The Universal
Access to Read-Write Web Pages
In 2004, Dale Dougherty the Vice-President of O’Reilly Media defined Web 2.0 as read-write web (Aghaei et al., 2012; Choudhury, 2014; Kujur & Chhetri, 2015; Patel, 2013). Web 2.0 is defined by Tim O’Reilly as cited in (Aghaei et al., 2012; Choudhury, 2014; Kujur & Chhetri, 2015; Miller, 2008) as follows : “Web 2.0 is the business revolution in the computer industry caused by the move to the internet as platform, and an attempt to understand the rules for success on that new platform. Chief among those rules is this: Build applications that harness network effects to get better the more people use them.” Others defined Web 2.0 as a “Transition” from Web 1.0 where information is isolated to computing platforms that are interlinked together which function as a local software for the user (Miller, 2008). In an attempt to differentiate between Cloud Computing and Web 2.0, Tim stated as cited in (Miller, 2008) “Cloud computing refers specifically to the use of the Internet as a computing platform; Web 2.0, as I’ve defined it, is an attempt to explore and explain the business rules of that platform.”
Web 2.0 has shifted Web 1.0 not only from read-only to be read-write but also to be technology centric, business-centric and user-centric (Choudhury, 2014). The technology-centric is found in the platform concept of the Web 2.0 which is different from a client/server framework of Web 1.0. The platform technology is associated with blogs, wikis, and Really Simple Syndication (RSS) feeds (Choudhury, 2014). The business-centric concept is reflected in the shift to the internet as a platform and comprehending the key success factors using this new platform concept on the internet (Choudhury, 2014). The user-centric concept is the shift from companies publishing content for read, to communities of users who are interacting and communicating with each other using the new platform on the internet (Choudhury, 2014). Tim O’Reilly identified a list of the differences between Web 1.0 and Web 2.0 (O’Reilly, 2007) (see Figure 1).
Figure 1: Web 1.0 vs. Web 2.0 Examples (O’Reilly, 2007).
Web
2.0 has other attributes such as “wisdom web,” “people-centric web,” and
“participative web” with reading the writing capabilities (Aghaei
et al., 2012; Choudhury, 2014; Kujur & Chhetri, 2015; Patel, 2013).T With Web 2.0, the user can have
flexible web design, updates, collaborative content creation and
modification (Aghaei
et al., 2012; Patel, 2013). The support for collaboration is one of the
major characteristics of Web 2.0, where people can share data (Patel,
2013).
Examples of Web 2.0 implementation
include a social network such as MySpace, Facebook, Twitter, media sharing such
as Youtube (Patel,
2013). Thus, the data for Web 2.0 is generated from
all these resources of MySpace, Facebook, Twitter and so force. With
Web 2.0, the data is growing very fast and entering a new level of “Petabyte
age” (Demirkan
& Delen, 2013).
Key
Technologies of Web 2.0
Web
2.0 utilized key technologies to allow people to communicate with each other
through the new platform on the internet (Aghaei
et al., 2012).
The key technologies of Web 2.0 include The RSS, Blogs, Mashups, Tags,
Folksonomy, and Tag Clouds (Aghaei
et al., 2012).
Three development approaches to create Web 2.0 applications: Asynchronous JavaScript and XML (AJAX), Flex
and Google Web Toolkit (Aghaei
et al., 2012).
Web
2.0 Architecture
Web 2.0 has
various architecture patterns (Governor,
Hinchcliffe, & Nickull, 2009). Three main levels of the Web 2.0 architecture
patterns starting from the most concrete to the most abstract which is
high-level design pattern (Governor
et al., 2009).
Some of these Web 2.0 architecture patterns include Service-Oriented
Architecture (SOA), Software as a Service (SaaS), Participation-Collaboration,
Asynchronous Particle Update, Mashup,
Rich User Experience (RUE), the Synchronized Web, Collaborative Tagging, Declarative
Living and Tag Gardening, Semantic Web Grounding, Persistent Rights Management,
and Structured Information (Governor
et al., 2009).
Web
2.0 Performance Bottleneck
In Web 1.0, the
Client/Server architecture provided users to access the data through the
internet. However, the users had the
experience of “wait” (Miller,
2008). As discussed earlier, the client has
bottlenecks in addition to the server’s bottleneck. The issue in Web 1.0 is that all
communications among computers had to go through the server first (Miller,
2008). Due to the requirement of having every client
passes through the server first, the concept of Peer-to-Peer was established to
solve this overload and bottleneck on the server side. Web 2.0 works with Peer-to-Peer framework (Aghaei
et al., 2012; Patel, 2013). While in Web 1.0, the server has the full
responsibility and capabilities to respond to clients, in Web 2.0 using the
Peer-to-Peer computing, each computer has the same responsibilities and
capabilities as the server (Miller,
2008). This new relationship between computers is
referred to as master/slave where the central sever acts as the master and the
client computers act as the slave (Miller,
2008). In Peer-to-Peer framework in Web 2.0, each
computer servers as a client as well as a server (Miller,
2008).
Peer-To-Peer framework provided the
capability of streaming live video from a single source to a large number of
receivers or peers over the internet without any special support from the
network (Magharei
& Rejaie, 2006, 2009). This capability is called P2P streaming
mechanism (Magharei
& Rejaie, 2006, 2009). There are two main bottlenecks with a P2P
streaming mechanism (Magharei
& Rejaie, 2006, 2009). The first bottleneck is called the “bandwidth
bottleneck,” and the second bottleneck is called “content bottleneck” (Magharei
& Rejaie, 2006, 2009). The “bandwidth bottleneck” is experienced by
the peer when the aggregate bandwidth available from all other peers is not
sufficient to fully utilize the incoming access link bandwidth (Magharei
& Rejaie, 2006, 2009). The “content bottleneck” is experienced by
the peer when the useful content from other peers is not sufficient to fully
utilize the bandwidth available in the network (Magharei
& Rejaie, 2006, 2009).
The discussion on the bottleneck in
Web 2.0 is not limited to Peer-to-Peer but also to platform computing. In Web
2.0, the user interacts with the web as it is not only read as the case in Web
1.0 but also has the write capabilities.
This feature of read-write capabilities can cause a bottleneck with a
high concurrent reading and writing operations using a large set of data (Choudhury,
2014). A data-intensive application or very
large-scale data transfer can cause a bottleneck, and it can be very costly (Armbrust
et al., 2009).
To solve this issue is to send disks or even whole computers via
overnight delivery services (Armbrust
et al., 2009).
When the data is moved to the Cloud, the data does not have any
bottleneck any longer because the data transfer is within the Cloud such as
storing the data in S3 in Amazon Web
Services, which can be transferred without any bottleneck to EC2 (Elastic
Compute Cloud) (Armbrust
et al., 2009).
WAN bandwidth can cause a bottleneck, and the intra-cloud networking
technology can also have a performance bottleneck (Armbrust
et al., 2009).
One Gigabit Ethernet (1GbE) reflects a bandwidth that can have a
bottleneck because it is not sufficient to process a large set of data using
technology such as Map/Reduce. However,
in the Cloud Computing, the 10Gigabit Ethernet is used for such aggregation
links (Armbrust
et al., 2009).
Map/Reduce is a processing
strategy to divide the operation into two jobs Map and then Reduce using the
“filtering-join-aggregation” tasks (Ji,
Li, Qiu, Awada, & Li, 2012). When using the classic Hadoop MapReduce, the
cluster is not artificially segregated into Map and reduce slots (Krishnan,
2013). Thus, the application jobs are bottlenecked
on the Reduce operation which limits the scalability in the job execution (Krishnan,
2013).
Because of the scalability bottleneck faced by the traditional Map/Reduce,
Yahoo introduced YARN for Yet Another Resource Negotiators to overcome such
scalability bottleneck in 2010 (White,
2012).
There are additional performance
issues which cannot be predicted. For
instance, there is a performance degradation when using Virtual Machines (VMs) which
share CPU and main memory in the Cloud Computing platform (Armbrust
et al., 2009). Moreover, the bottleneck at the computing
platform can be caused when moving a large set of data continuously to a remote
CPUs (Foster,
Zhao, Raicu, & Lu, 2008). The Input/Output (I/O) operations can also
cause a performance degradation issue (Armbrust
et al., 2009; Ji et al., 2012). Flash
memory is another aspect that can minimize the performance. The scheduling of VMs for High-Performance
Computing (HPC) apps is another unpredictable performance issue (Armbrust
et al., 2009).
The issue of such scheduling for HPC is to ensure that all threads of a
program are running concurrently which is not provided by either VMs or the
operating systems (Armbrust
et al., 2009).
Another issue with the computing platform about bottleneck is the
availability of the cloud environment is threatened when there is a flooding attack
which will affect the available bandwidth, processing power and the memory (Fernandes,
Soares, Gomes, Freire, & Inácio, 2014). Thus, to minimize the bottleneck issue when
processing a large set of data in the computing platform, the data must be
distributed over many computers (Foster
et al., 2008; Modi, Patel, Borisaniya, Patel, & Rajarajan, 2013).
Web 3.0 – Semantic Web
Web 3.0 is the
third generation of the Web. It was
introduced by John Markoff of the New York Times in 2006 (Aghaei
et al., 2012).
Web 3.0 is known as “Semantic Web” as well as the “Web of Cooperation” (Aghaei
et al., 2012), and as “Executable Web (Choudhury,
2014; Kujur & Chhetri, 2015; Patel, 2013). Berners-Lee introduced the concept of Semantic
Web in 2001 (T.
Berners-Lee, Hendler, & Lassila, 2001). The underlying concept of Web 3.0 is to link,
integrate and analyze data from various datasets to obtain new information
stream (Aghaei
et al., 2012).
Web 3.0 has a variety of capabilities (Aghaei
et al., 2012).
When using Web 3.0, the data management can be improved, the accessibility
of the mobile internet can be supported, creativity and innovation are
simulated, the satisfaction of the customers is enhanced, and the collaboration
in the social web is organized (Aghaei
et al., 2012; Choudhury, 2014). Another key factor for Web 3.0 is that the
web is no longer understood only by human but also by machines (Aghaei
et al., 2012; Choudhury, 2014). In other words, the web is understood by human
and machines in Web 3.0, where the machines first understand the web followed
by a human (Aghaei
et al., 2012; Choudhury, 2014). Web 3.0 supports world wide database and web oriented
architecture which was described as a web of document (Patel,
2013).
Web 3.0 characteristics include portable
personal web, and consolidating dynamic content, lifestream, individuals, RDF,
and user engagements (Aghaei
et al., 2012; Patel, 2013). Examples of Web 3.0 include Google Map, My
Yahoo (Patel,
2013). Since Web 3.0 is described as the mobile and
sensor-based era, the majority of the data sources are from mobile and
sensor-based devices (Chen,
Chiang, & Storey, 2012).
Key
Technologies of Web 3.0
While
in Web 2.0 the content creativity of users is the target, in Web 3.0 the linked
data sets are the target. Web 3.0 is not only for publishing data on the web
but also linking related data (Choudhury,
2014). Linked Data principles introduced by
Berners-Lee as the rules to publish and connect data on the web in 2007 (Aghaei
et al., 2012; Choudhury, 2014). These rules are summarized below:
URI should be used as Names of Things. HTTP URIs should be used to look up those
Names.
Useful Information should be provided
using the standards of RDF, SPARQL by looking up the URIs.
Links to other URIs should be included to
discover more things.
In (T.
Berners-Lee et al., 2001) the technology of
the Semantic Web included XHTML, SVG, and SMIL and placed on top of the XML
layer. XSLT is used for the
transformation engines, while XPath and XPointer are used for path and pointer
engines (T.
Berners-Lee et al., 2001). CSS and XSL are used for the style engines
and formatters (T.
Berners-Lee et al., 2001).
Web
3.0 Architecture
The
Semantic Web framework is a multi-layered architecture. The degree of the structure among objects is
based on a model called Resource Description Framework” (RDF) (Aghaei
et al., 2012; Patel, 2013). The structure of the semantic data include
from the bottom up, the Unicode and URI at the bottom of the framework,
followed by the Extensible Markup Language (XML), RDF, RDF Schema, Ontology Web
Language (OWL), Logic and Proof and Trust at the top (see Figure 2).
Figure 2: Web 3.0 – Semantic Web Layered Architecture (Patel, 2013).
There
are eight categories for Web Semantic identified by (T.
Berners-Lee et al., 2001) to describe the
relation of Web Semantic with Hypermedia Research. The first category describes the basic node,
link and anchor data mode. The second
category reflects the typed nodes, links, and anchors. The Conceptual Hypertext is the third
category of this relation. Virtual Links
and Anchors is the fourth category, while searching and querying is the fifth
category. Versioning and Authentication
features, Annotation and User Interface Design beyond the navigational
hypermedia reflect the last three categories of the relation of Semantic Web
with Hypermedia Research (T.
Berners-Lee et al., 2001).
Web
3.0 is expected to include four major drivers in accordance with Steve Wheeler
as cited in (Chisega-Negrila,
2016). The first driver includes the distributed
computing. The second driver includes
the extended smart phone technology. The third driver includes the
collaborative intelligence. The last
driver is the 3D visualization and interaction (Chisega-Negrila,
2016).
Web
3.0 Performance Bottleneck
The result of the research in (Firat & Kuzu, 2011) found that the components of the Semantic Web of XML, RDF and OWL help overcome hypermedia bottlenecks in various areas of the eLearning such as the cognitive overload, disorientation in hypermedia (Firat & Kuzu, 2011). However, Web 3.0 faces the bottleneck of the search in sensor networks (Nicolaidis & Iniewski, 2017), as the use of mobile technology has been increasing (see Figure 3) (Nicolaidis & Iniewski, 2017).
Figure 3: Increasing Use of the Mobile Technology (Nicolaidis & Iniewski, 2017)
The
wireless communication in sensor networks is causing the bottleneck with the
increasing number of requests (Nicolaidis
& Iniewski, 2017).
Thus, the time to answer queries gets increased, which result in
decreasing the search experience of the users (Nicolaidis
& Iniewski, 2017).
Thus, the approach of the push-based is used to force sensors to push
regularly their new readings to a base station, which decrease the latency to
the users’ requests (Nicolaidis
& Iniewski, 2017). However, this approach cannot
guarantee that the data is up-to-date as it can be outdated (Nicolaidis
& Iniewski, 2017).
If there are no much changes, the update can be sent when there is a
change. However, if the changes are too often, this approach can cause
congestion of the wireless channel resulting in delayed or missing messages (Nicolaidis
& Iniewski, 2017).
Prediction-Model-Based approaches are proposed to reduce the volume of
the data when transmitting dynamic sensor data (Nicolaidis
& Iniewski, 2017).
However, to create an accurately predicted model, a series of sensor
readings need to be transmitted (Nicolaidis
& Iniewski, 2017).
Using the prediction approach, the latency is reduced because the
prediction at a based station instead of contacting a sensor over the non-reliable
multi-hop connection (Nicolaidis
& Iniewski, 2017).
Moreover, scaling the systems to more sensors causes another bottleneck
which needs to be solved by utilizing the distribution approach (Nicolaidis
& Iniewski, 2017).
Moreover,
in (Konstantinou,
Spanos, Stavrou, & Mitrou, 2010), the contemporary
Semantic Web is defined as the counterpart of the Knowledge Acquisition
bottleneck where it was too expensive to acquire and encode the large amount of
knowledge that is needed for the application (Konstantinou
et al., 2010).
The annotation of the content in Web Semantic is still an open issue and
is regarded as an obstacle for Semantic Web applications which need the considerable
volume of data to demonstrate their utility (Konstantinou
et al., 2010).
Web 4.0 – Intelligent Web
The rapid increase in the communication using wireless enables another major transition in the Web (Kambil, 2008). This transition enables people to connect with objects anywhere and anytime at the physical world as well as at the virtual world (Kambil, 2008). Web 4.0 is the fourth generation of Web and is known as “web of intelligence connections” (Aghaei et al., 2012) or “Ultra-Intelligent Electronic Agent” (Choudhury, 2014; Kujur & Chhetri, 2015; Patel, 2013). It is read-write, execution, and concurrency web with intelligent interactions (Aghaei et al., 2012; Patel, 2013). Some consider it as “Symbiotic Web” where human and machines can interact in symbiosis fashion (Aghaei et al., 2012; Choudhury, 2014; Kujur & Chhetri, 2015; Patel, 2013) and as “Ubiquitous Web” (Kujur & Chhetri, 2015; Patel, 2013; Weber & Rech, 2009). Using Web 4.0, machines will be intelligent reading the web content and deliver web pages with superior performance at the real-time (Aghaei et al., 2012; Choudhury, 2014). It is also known as WebOS which will act as the “Middleware” which will act as an operating system (Aghaei et al., 2012; Choudhury, 2014). WebOS is expected to resemble or be equivalent to our brain which will highly interact intelligently (Aghaei et al., 2012; Choudhury, 2014). As indicated in (Aghaei et al., 2012) “the web is moving toward using artificial intelligence to become an intelligent web.” Web 4.0 will reflect the integration between people and virtual worlds and objects at the real-time (Kambil, 2008). The Artificial Intelligence technologies are expected to play a role in Web 4.0 (Weber & Rech, 2009).
The major challenges for Web 4.0
generating value that is based on full integration of the physical objects and
virtual objects with other contents that are generated by users (Kambil,
2008). This challenge could lead to the next
generation of Supervisory Control and Data Acquisition (SCADA) applications (Kambil,
2008). The challenge can also lead to generating
value from sources such as “entertainment” which collect information from human
and objects (Kambil,
2008).
The migration of virtual world to
physical is another challenge in Web 4.0 (Patel,
2013). A good example of Web 4.0 is provided by (Patel,
2013),
which is to search or Google your home to locate an object such as your car
key.
An application of the Web 4.0 is
implemented by Rafi Haladjian and Olivier who created the first consumer
electronics in Amazon, which can recognize you and provide recommended product
and personalized advice (Patel,
2013). The time frame for Web 4.0 is expected to be
2020 – 2030 (Loretz,
2017; Weber & Rech, 2009). Web
4.0 is still in progress.
Web 4.0 and “Internet of Things”
Some like (Loretz, 2017) considers “Internet of Things” as part of Web 3.0 and Web 4.0, while others like (Pulipaka, 2016) categorize it under Web 4.0. Thus, the discussion on the “Internet of Things” from the bottleneck perspective is addressed under the Web 4.0 section of this paper.
As indicated in (Atzori, Iera, & Morabito, 2010) Internet of Things (IoT) is regarded to be “one of the most promising
fuels of Big Data expansion” (De Mauro, Greco, & Grimaldi, 2015). IoT seems promising as Google
acquired Nest for $3.2 billion in January 2014 (Dalton, 2016). The
Nest is a smart hub producer at the forefront of the Internet of Things (Dalton, 2016). This acquiring can tell the
importance of the IoT. IoT is becoming
powerful because it affects our daily life and the behavior of the users (Atzori et al., 2010). The underlying concept of the
IoT is the ubiquitous characteristics that using various devices such as
sensors, mobile phones and so forth (Atzori et al., 2010).
As cited in (Batalla & Krawiec, 2014) “Internet of Things (IoT) is global
network infrastructure, linking physical and virtual objects through the exploitation
of data capture and communication capabilities” (Batalla & Krawiec, 2014). IoT is described by (Batalla & Krawiec, 2014) as “a huge connectivity platform for self-managed objects.” IoT is increasingly growing, and the reasons for such strong growth go to
the inexpensive cost of the computing including sensors and the growth of Wi-Fi
(Gholap & Asole, 2016; Gubbi, Buyya,
Marusic, & Palaniswami, 2013), and 4G-LTE (Gubbi et al., 2013). Other factors include the growth of mobiles, the rise of software
developments, the emergence of standardized low-power wireless technologies (Gholap & Asole, 2016).
With the advancement in the Web, from static web pages in Web 1.0 to network web in Web 2.0, to ubiquitous
computing web in Web 3.0, the increased requirement for “data-on-demand” using complex, and intuitive queries becomes
significant (Gubbi et al., 2013). With IoT, many objects and many
things surrounding people will be on the network (Gubbi et al., 2013). The Radio Frequency IDentification (RFID) and the technologies of
the sensor network emerge to respond to the IoT network challenges where
information and communication systems are embedded in the environment around us
invisibly (Gubbi et al., 2013). The computing criterion for the
IoT will go beyond the traditional scenarios of the mobile computing which
utilize the smartphones and portables (Gubbi et al., 2013). IoT will evolve to connect existing everyday objects and embed
intelligence into our environment (Gubbi et al., 2013).
Web 4.0 and IoT Performance Bottleneck
The elements of IoT include the RFID, Wireless Sensor Networks (WSN),
Addressing Schemes, Data Storage and Analytics, and Visualization (Gubbi et al., 2013). IoT will require the persistence
of the network to channel the traffic of the data ubiquitously. IoT confronts a bottleneck at the interface
between the gateway and wireless sensor devices (Gubbi et al., 2013). The bottleneck at the interface is between the Internet and smart
object networks of the RFID or WSN subnets (Jin, Gubbi, Marusic, & Palaniswami,
2014). Moreover, the scalability of the address of
the device of the existing network must be sustainable (Gubbi et al., 2013). The performance of the network or
the device functioning should not be affected by adding networks and devices (Gubbi et al., 2013; Jin et al., 2014). The Uniform Resource Name (URN) system will play a significant role in the development of IoT to overcome these issues (Gubbi et al., 2013).
Moreover, although Cloud can enhance and simplify the communication of
IoT, the Cloud can still represent a bottleneck in certain scenarios (Botta, de Donato, Persico, & Pescapé,
2016). As indicated in (Gubbi et al., 2013), the high capacity and large-scale web data generated by IoT and as IoT
grows, the Cloud becomes a bottleneck (Gubbi et al., 2013). A framework proposed by (Gubbi et al., 2013) to enable scalability of the cloud to provide the capacity that is required for IoT. While the proposed
framework of (Gubbi et al., 2013) enables the separation of the networking, computation, storage and
visualization theme, it allows the independent growth in each domain, at the
same time enhances each other in an environment that is shared among them (Gubbi et al., 2013).
Web 4.0 and IoT New Challenges
IoT faces additional challenges such as Addressing and Networking Issues (Atzori et al., 2010). The investigation effort has been exerted about the integration of RFID tags
into IPv6. Mobile IP is proposed as a
solution for the mobility in IoT scenarios (Atzori et al., 2010). Moreover, the DNS (domain name servers), which provide IP address of a
host from a certain input name, does not seem to serve the IoT scenarios where
communications are among objects and not hosts. Object Name Service (ONS) is
proposed as a solution to the DNS issue (Atzori et al., 2010). ONS will associate a reference
to a description of the object and the related RFID tag identifier, and it must
work in a bidirectional manner (Atzori et al., 2010). For the complex operation of
IoT, the Object Code Mapping Service (OCMS) is still an open issue (Atzori et al., 2010). TCP as the Transmission Control
Protocol is found inadequate and
inefficient for the transmission control of end-to-end in the IoT (Atzori et al., 2010). The TCP issue is still an open
issue for IoT (Atzori et al., 2010). Other issues of IoT include
Quality of Service, Security, and
Privacy.
Web 5.0 – Symbionet Web
Web 5.0 is still in progress and can be regarded as “Symbionet Web” (Loretz, 2017; Patel, 2013) or “Telepathic Web” (Loretz, 2017). In Web 5.0, people will be able to have their own Personal Servers (PS), where they can store and communicate with their personal data using Smart Communicator (SC) such as Smart Phones, Tablets and so forth (Patel, 2013). The Smart Communications will be 3D Virtual World of the Symbionet (Patel, 2013). Web 5.0 will be aware of your emotions and feelings (Kambil, 2008). Objects such as tools such as headset are investigated for emotional interaction (Kambil, 2008). While there is a claim from some companies that they map emotions and feelings, this claim can be hard to imagine because emotions and feelings are complex (Kambil, 2008). However, some technologies are examining the emotions effect (Kambil, 2008). There is an idea that there will “brain implant” which enables the person to communicate with the internet and web by thoughts (Loretz, 2017). The person will be able to open pages just by thoughts (Loretz, 2017). The time frame for Web 5.0 is after 2030 (Loretz, 2017).
Conclusion
This
project discussed the Web from the inception of Web 1.0 until the last generation
of Web 5.0. The project addressed the main
characteristics of each generation and the main sources for generating the
large-scale web data. Web 1.0 is known
as the “Web of Information Connections” where information is broadcasted by
companies for users to read. Web 2.0 is
known as the “Web of People Connections” where people connected. Web 3.0 is known as the “Web of Knowledge
Connections” where people share knowledge.
Web 4.0 is known as the “Web of Intelligence Connections” where
Artificial Intelligence is expected to play a role. Web 5.0 is known as the “Symbionet Web” where
emotions and feelings are expected to be communicated to the machines, and be
part of the Web interactions.
The
project also discussed the key technologies and the underlying architecture of
each Web generation. Moreover, this paper also discussed and analyzed the
performance bottlenecks when accessing the large-scale data for each Web
generation, and the proposed solutions for some of these bottlenecks and the open
issues.
References
Aghaei, S., Nematbakhsh,
M. A., & Farsani, H. K. (2012). Evolution of the world wide web: From WEB
1.0 TO WEB 4.0. International Journal of
Web & Semantic Technology, 3(1), 1.
Armbrust,
M., Fox, A., Griffith, R., Joseph, A. D., Katz, R. H., Konwinski, A., . . .
Stoica, I. (2009). Above The Clouds: A Berkeley View of Cloud Computing.
Atzori,
L., Iera, A., & Morabito, G. (2010). The internet of things: A survey. Computer networks, 54(15), 2787-2805.
Batalla,
J. M., & Krawiec, P. (2014). Conception of ID layer performance at the
network level for Internet of Things. Personal
and Ubiquitous Computing, 18(2), 465-480.
Berners-Lee,
T. (1996). WWW: Past, present, and future. Computer,
29(10), 69-77.
Berners-Lee,
T., Hendler, J., & Lassila, O. (2001). The semantic web.
Berners-Lee,
T. J. (1992). The world-wide web. Computer
networks and ISDN systems, 25(4-5), 454-459.
Botta,
A., de Donato, W., Persico, V., & Pescapé, A. (2016). Integration of Cloud
Computing and Internet Of Things: a Survey. Future
Generation computer systems, 56, 684-700.
Chen,
H., Chiang, R. H., & Storey, V. C. (2012). Business Intelligence and
Analytics: From Big Data to Big Impact. MIS
quarterly, 36(4), 1165-1188.
Chisega-Negrila,
A. M. (2016, 2016). IMPACT OF WEB 3.0 ON
THE EVOLUTION OF LEARNING, Bucharest.
Choudhury,
N. (2014). World Wide Web and its journey from web 1.0 to web 4.0.
Dalton,
C. (2016). Brilliant Strategy for
Business: How to plan, implement and evaluate strategy at any level of
management: Pearson UK.
De
Mauro, A., Greco, M., & Grimaldi, M. (2015). What is big data? A consensual definition and a review of key research
topics. Paper presented at the AIP Conference Proceedings.
Demirkan,
H., & Delen, D. (2013). Leveraging the capabilities of service-oriented
decision support systems: Putting analytics and big data in cloud. Decision Support Systems, 55(1),
412-421.
Fernandes,
D. A., Soares, L. F., Gomes, J. V., Freire, M. M., & Inácio, P. R. (2014).
Security issues in cloud environments: a survey. International Journal of Information Security, 13(2), 113-170.
doi:/10.1007/s10207-013-0208-7
Firat,
M., & Kuzu, A. (2011). Semantic web for e-learning bottlenecks:
disorientation and cognitive overload. International
Journal of Web & Semantic Technology, 2(4), 55.
Foster,
I., Zhao, Y., Raicu, I., & Lu, S. (2008). Cloud Computing and Grid Computing 360-Degree Compared. Paper
presented at the 2008 Grid Computing Environments Workshop.
Gholap,
K. K., & Asole, S. (2016). Today’s Impact of Big Data on Cloud. International Journal of Engineering
Science, 3748.
Governor,
J., Hinchcliffe, D., & Nickull, D. (2009). Web 2.0 Architectures: What entrepreneurs and information architects
need to know: ” O’Reilly Media, Inc.”.
Gubbi,
J., Buyya, R., Marusic, S., & Palaniswami, M. (2013). Internet of Things
(IoT): A vision, architectural elements, and future directions. Future Generation computer systems, 29(7),
1645-1660.
Hu,
H., Wen, Y., Chua, T.-S., & Li, X. (2014). Toward scalable systems for big
data analytics: A technology tutorial. IEEE
Access, 2, 652-687.
Ji,
C., Li, Y., Qiu, W., Awada, U., & Li, K. (2012). Big Data Processing in Cloud Computing Environments. Paper
presented at the 2012 12th International Symposium on Pervasive Systems,
Algorithms and Networks.
Jin,
J., Gubbi, J., Marusic, S., & Palaniswami, M. (2014). An information
framework for creating a smart city through internet of things. IEEE Internet of Things Journal, 1(2),
112-121.
Kambil,
A. (2008). What is your Web 5.0 strategy? Journal
of business strategy, 29(6), 56-58.
Konstantinou,
N., Spanos, D.-E., Stavrou, P., & Mitrou, N. (2010). Technically
approaching the semantic web bottleneck. International
Journal of Web Engineering and Technology, 6(1), 83-111.
Krishnan,
K. (2013). Data warehousing in the age of
big data: Newnes.
Kujur,
P., & Chhetri, B. (2015). Evolution of World Wide Web: Journey From Web 1.0
to Web 4.0 IJCST, 6(1).
Magharei,
N., & Rejaie, R. (2006). Understanding
mesh-based peer-to-peer streaming. Paper presented at the Proceedings of
the 2006 international workshop on Network and operating systems support for
digital audio and video.
Magharei,
N., & Rejaie, R. (2009). Prime: Peer-to-peer receiver-driven mesh-based
streaming. IEEE/ACM Transactions on
Networking (TON), 17(4), 1052-1065.
Markatos,
E. P. (2002). Tracing a large-scale peer
to peer system: an hour in the life of gnutella. Paper presented at the
Cluster Computing and the Grid, 2002. 2nd IEEE/ACM International Symposium on.
Miller,
M. (2008). Cloud Computing, Web-Based Applications That Change the Way You Work
and Collaborate Online. Michael Miller.
Modi,
C., Patel, D., Borisaniya, B., Patel, A., & Rajarajan, M. (2013). A survey
on security issues and solutions at different layers of Cloud computing. The Journal of Supercomputing, 63(2),
561-592.
Mosberger,
D., & Jin, T. (1998). httperf—a tool for measuring web server performance. ACM SIGMETRICS Performance Evaluation
Review, 26(3), 31-37.
Nicolaidis,
I., & Iniewski, K. (2017). Building
Sensor Networks: CRC Press.
O’Reilly,
T. (2007). What is web 2.0.
Patel,
K. (2013). Incremental journey for World Wide Web: introduced with Web 1.0 to
recent Web 5.0–a survey paper.
Weber,
S., & Rech, J. (2009). An overview and differentiation of the evolutionary
steps of the web XY movement: the web before and beyond 2.0. Handbook of Research on Web 2.0, 3.0, and X.
0: Technologies, Business, and Social Applications: Technologies, Business, and
Social Applications, 12.
White, T. (2012). Hadoop:
The definitive guide: ” O’Reilly Media, Inc.”.
Internet of Things (IoT)
is regarded to be “one of the most promising fuels of Big Data expansion” (De
Mauro, Greco, & Grimaldi, 2015). IoT seems promising as Google acquired Nest
for $3.2 billion in January 2014 (Dalton, 2016). The
Nest is a smart hub producer at the forefront of the Internet of Things (Dalton, 2016). This acquiring can tell the
importance of the IoT. IoT is becoming
powerful because it affects our daily life and the behavior of the users (Atzori, Iera, & Morabito, 2010). The underlying concept of the
IoT is the ubiquitous characteristics that using various devices such as
sensors, mobile phones and so forth (Atzori et al., 2010).
As cited in (Batalla & Krawiec, 2014) “Internet of Things (IoT) is a global network infrastructure, linking
physical and virtual objects through the exploitation of data capture and
communication capabilities” (Batalla & Krawiec, 2014). IoT is described by (Batalla & Krawiec, 2014) as “a huge connectivity platform for self-managed objects.” IoT is increasingly growing, and the reasons for such strong growth go to
the inexpensive cost of the computing including sensors and the growth of Wi-Fi
(Gholap & Asole, 2016; Gubbi, Buyya,
Marusic, & Palaniswami, 2013), and 4G-LTE (Gubbi et al., 2013). Other factors include the growth of mobiles, the rise of software
developments, the emergence of standardized low-power wireless technologies (Gholap & Asole, 2016).
With the advancement in the Web, from static web
pages in Web 1.0 to network web in Web
2.0, to ubiquitous computing web in Web 3.0, the increased requirement for “data-on-demand”
using complex, and intuitive queries
becomes significant (Gubbi et al., 2013). With IoT, many objects and many
things surrounding people will be on the network (Gubbi et al., 2013). The Radio Frequency IDentification (RFID) and the technologies of
the sensor network emerge to respond to the IoT network challenges where
information and communication systems are embedded in the environment around us
invisibly (Gubbi et al., 2013). The computing criterion for the
IoT will go beyond the traditional scenarios of the mobile computing which
utilize the smartphones and portables (Gubbi et al., 2013). IoT will evolve to connect existing everyday objects and embed intelligence
into our environment (Gubbi et al., 2013).
Performance Bottleneck
The elements of IoT include the RFID, Wireless Sensor Networks (WSN), Addressing Schemes, Data Storage and Analytics, and Visualization (Gubbi et al., 2013). IoT will require the persistence of the network to channel the traffic of the data ubiquitously. IoT confronts a bottleneck at the interface between the gateway and wireless sensor devices (Gubbi et al., 2013). The bottleneck at the interface is between the Internet and smart object networks of the RFID or WSN subnets (Jin, Gubbi, Marusic, & Palaniswami, 2014). Moreover, the scalability of the address of the device of the existing network must be sustainable (Gubbi et al., 2013). The performance of the network or the device functioning should not be affected by adding networks and devices (Gubbi et al., 2013; Jin et al., 2014). The Uniform Resource Name (URN) system will play a significant role in the development of IoT to overcome these issues (Gubbi et al., 2013).
Moreover, although Cloud can enhance and simplify
the communication of IoT, the Cloud can still represent a bottleneck in certain
scenarios (Botta, de Donato, Persico, & Pescapé,
2016). As indicated in (Gubbi et al., 2013), the high capacity and large-scale web data generated by IoT and as IoT grows,
the Cloud becomes a bottleneck (Gubbi et al., 2013). A framework proposed by (Gubbi et al., 2013) to enable scalability of the cloud to provide the capacity that is required for IoT. While the proposed
framework of (Gubbi et al., 2013) enables the separation of the networking, computation, storage and
visualization theme, it allows the independent growth in each domain, at the
same time enhance each other in an environment that is shared among them (Gubbi et al., 2013).
IoT New Challenges
IoT faces additional challenges such as Addressing and Networking Issues (Atzori et al., 2010). The investigation effort has been exerted about the integration of RFID tags into IPv6. Mobile IP is proposed as a solution for the mobility in IoT scenarios (Atzori et al., 2010). Moreover, the DNS (domain name servers), which provide IP address of a host from a certain input name, does not seem to serve the IoT scenarios where communications are among objects and not hosts. Object Name Service (ONS) is proposed as a solution to the DNS issue (Atzori et al., 2010). ONS will associate a reference to a description of the object and the related RFID tag identifier, and it must work in a bidirectional manner (Atzori et al., 2010). For the complex operation of IoT, the Object Code Mapping Service (OCMS) is still an open issue (Atzori et al., 2010). TCP as the Transmission Control Protocol is found inadequate and inefficient for the transmission control of end-to-end in the IoT (Atzori et al., 2010). The TCP issue is still an open issue for IoT (Atzori et al., 2010). Other issues of IoT include Quality of Service, Security, and Privacy.
In conclusion, IoT is a promising domain that will change
how we communicate and how we live our everyday life.
There are still major issues such as the bottleneck when dealing with
large-scale of data, addressing and network issues such as DNS, and TCP. Various efforts are exerted in the research
field and industry to address these issues.
However, there are still open issues that are under investigation, which
place the IoT in the “work in progress” status, and it is not fully matured.
References
Atzori, L., Iera, A., &
Morabito, G. (2010). The internet of things: A survey. Computer networks, 54(15), 2787-2805.
Batalla, J. M.,
& Krawiec, P. (2014). Conception of ID layer performance at the network
level for Internet of Things. Personal
and Ubiquitous Computing, 18(2), 465-480.
Botta, A., de
Donato, W., Persico, V., & Pescapé, A. (2016). Integration of Cloud
Computing and Internet Of Things: a Survey. Future
Generation computer systems, 56, 684-700.
Dalton, C.
(2016). Brilliant Strategy for Business:
How to plan, implement and evaluate strategy at any level of management:
Pearson UK.
De Mauro, A.,
Greco, M., & Grimaldi, M. (2015). What
is big data? A consensual definition and a review of key research topics.
Paper presented at the AIP Conference Proceedings.
Gholap, K. K.,
& Asole, S. (2016). Today’s Impact of Big Data on Cloud. International Journal of Engineering
Science, 3748.
Gubbi, J., Buyya,
R., Marusic, S., & Palaniswami, M. (2013). Internet of Things (IoT): A
vision, architectural elements, and future directions. Future Generation computer systems, 29(7), 1645-1660.
Jin,
J., Gubbi, J., Marusic, S., & Palaniswami, M. (2014). An information
framework for creating a smart city through internet of things. IEEE Internet of Things Journal, 1(2),
112-121.
As indicated in (Berners-Lee, 1996), the Web was intended as “universe of accessible network information… Universal access means that you put it on the Web and you can access it from anywhere.” There is one space for being a universe, which is represented in the URL (Uniform Resource Locators) space which starts with HTTP. The web allowed the hypertext links to point to anything (Berners-Lee, 1996). The URLs are the most common type of Uniform Resource Identifiers (URIs) (Berners-Lee, Hendler, & Lassila, 2001). The resources are identified by global identifiers called Universal Document Identifier (UDI) (Berners-Lee, 1996) (now called Uniform Resource Identifiers) (URI) (Jacobs & Walsh, 2004). The benefits of the URIs include linking, bookmarking, caching, and indexing by search engines (Jacobs & Walsh, 2004). URIs have different schemes such as HTTP, FTP, LDAP to access the identified resource (Jacobs & Walsh, 2004). The communication between agents over the network of resources involves URIs, messages, and data (Jacobs & Walsh, 2004). This communication can use any of the Web protocol of The HyperText Transfer Protocol (HTTP), FTP (File Transfer Protocol), SOAP (Simple Object Access Protocol), and SMPT (Simple Mail Protocol Transfer) (Jacobs & Walsh, 2004). The HTTP URI scheme is defined regarding TCP-based HTTP servers (Jacobs & Walsh, 2004).
Web 1.0 is the first generation of
the Web (Aghaei, Nematbakhsh, &
Farsani, 2012; Choudhury, 2014; Patel, 2013). In Web 1.0, the
access was read-only (Aghaei et al., 2012;
Choudhury, 2014; Patel, 2013). Web 1.0 is regarded as a web of cognition (Aghaei et al., 2012). It started with a place of information for business to
publish the information publicly (Aghaei et al., 2012). In Web 1.0, no user
interaction was available, and the users were allowed to search the information
only and read it. The information was
published using static HTML (HyperText Markup
Language) (Aghaei et al., 2012;
Choudhury, 2014; Patel, 2013). The core protocols
for Web 1.0 included HTTP, HTML, and URI (Aghaei et al., 2012;
Choudhury, 2014; Patel, 2013). Web 1.0 had three
major limitations. The first limitation is reflected in the pages that can only be understood by humans (web readers) where
there is no machine compatible content (Choudhury, 2014; Patel,
2013). The second limitation reflected the content
of the websites that can only be updated
and managed solely by the webmasters who use framesets (Choudhury, 2014; Patel,
2013). The third limitation reflected the lack of
dynamic representation to acquire only static information where no web console
to perform dynamic events (Choudhury, 2014).
The second generation of Web is Web
2.0, which was introduced in 2004 (Aghaei et al., 2012). It is distinguished
from Web 1.0 as it is read-write web and interactive unlike Web 1.0, and it is
known as people-centric web, and participative web (Aghaei et al., 2012). The characteristics
of the Web 2.0 include flexible web design, creative reuse, updates,
collaborative content creation and modification (Aghaei et al., 2012). The main
technologies and services of Web 2.0 include blogs, really simple syndication
(RSS), wikis, mashups, tags, folksonomy, and tag clouds (Aghaei et al., 2012). In Web 2.0, three
main approaches are used to develop such interactive applications: Asynchronous JavaScript and XML (AJAX), Flex,
and the Google Web Toolkit (Aghaei et al., 2012). Web 2.0 has three major limitations (Choudhury, 2014). The first
limitation is the constant iteration cycle of modification and update to
services. The second limitation is reflected in the ethical issues concerning
the development and the usage of Web 2.0 (Choudhury, 2014). The third
limitation is represented in the interconnectivity and knowledge sharing
between platforms across community boundaries which are still limited (Choudhury, 2014).
The third generation of the Web is Web
3.0, which was introduced in 2006 as “semantic
web” (Aghaei et al., 2012; Kambil,
2008; Patel, 2013)
or “executable Web” (Choudhury, 2014). Web 3.0 includes two
main platforms of the semantic technologies and the social computing (Aghaei et al., 2012; Patel,
2013).
The semantic technologies open standards which can be applied on the top of the
web, while the social computing allows the cooperation of the machine and the
organization of a large number of social
web communities (Aghaei et al., 2012). With Web 3.0, the
data can be linked, integrated and analyzed using data sets to obtain a new stream of information (Aghaei et al., 2012). With Web 3.0, the
data management is improved, the accessibility of the mobile internet is supported, the creativity and innovation are
simulated, customers’ satisfaction is enhanced, and the collaboration of the
social web is organized (Aghaei et al., 2012). The Semantic Web emerged to overcome the problem of the
current web which is represented in the “web of documents” (Aghaei et al., 2012). The Semantic Web is
defined as the “Web of Data,” where primary
objects are regarded as things which can be linked (Aghaei et al., 2012;
Choudhury, 2014; Patel, 2013). The World-Wide Web Consortium (W3C) team developed
Resource Description Framework (RDF) to provide a framework to describe and
exchange meta-data on the Web (Devlic & Jezic, 2005), to improve and extend, and standardize
the existing systems, tools and languages (Aghaei et al., 2012; Choudhury, 2014;
Patel, 2013).
In 2007, Berners-Lee developed rules
known as Linked Data principles to publish and connect data on the web for
Semantic Web (Aghaei et al., 2012). These rules include
URI, HTTP, RDF as follows:
URIs should be used as names for things,
HTTP URIs should be used to look up
those names,
URI should be used to provide useful
information using the standards RDF, SPARQL, and
Links to other URIs should be
included to discover more things (Aghaei et al., 2012).
Web 4.0 is the fourth generation of
the Web and is known as the Web of Integration (Aghaei et al., 2012), and is considered as
an “Ultra-Intelligent Electronic Agent,” “symbiotic web” and “ubiquitous web” (Patel, 2013). In Web 4.0 machines
can read the contents of the web, and
execute and decide the first execution to load the website fast with a high
quality and superior performance and develop more commanding interfaces (Patel, 2013). Web 4.0 will be
read-write and concurrency web. The
first Web 4.0 was the consumer electronic where consumers are recognized, and
personalized advice is offered as the case with Amazon (Patel, 2013). The migration of
online functionality into the physical world is regarded to be the most
critical development of Web 4.0 (Patel, 2013).
Web 5.0 is the fifth generation of
the Web and is in progress, and there is no exact definition of how it
would be (Patel, 2013). However, Web 5.0 can be regarded as decentralization
of the “Symbionet Web,” whose servers can use a part of “memory and calculation
power” of each interconnected SmartCommunicator (SC) such as smartphones, or
tablets, in order to calculate billions of data to develop 3D world, and feed the
Artificial Intelligence (Patel, 2013).
From the computing platform perspective, each generation of the Web has its characteristics. The underlying computing platform of the Web 1.0 was the traditional client-server based distributed computing (Aghaei et al., 2012; Patel, 2013).
The computing platform of Web 2.0 is represented in grid, cluster, and cloud
computing (Foster, Zhao, Raicu, & Lu, 2008). The grid computing emerged from
distributed computing and parallel processing technologies (Dubitzky, 2008). Grid computing supports various
kinds of applications ranging from high-performance
computing (HPC) to high throughput computing (HTC) (Foster et al., 2008). With grid computing resources are shared to provide advantages such as overcoming
of bottlenecks face by much large-scale
application, the adaption to unexpected failure, integration of heterogeneous
resources and systems, and providing cost/performance ratio making
high-performance computing affordable (Dubitzky, 2008). However, grid computing faced challenges resulted from the complexity of the heterogeneity of the
underlying software and hardware resources, decentralized control, techniques
to deal with the faults and loss of resources, security, and privacy (Dubitzky, 2008).
As indicated in (Ji, Li, Qiu, Awada, & Li, 2012), with the success of Web 2.0, the needs to store and analyze the growing
data, such as search logs, crawled web content, and click streams have been increased.
The Cloud computing evolved out of grid computing and relied on grid
computing as its backbone and infrastructure support (Foster et al., 2008).
The computing platform for Web 3.0 is reflected in the mobile and sensor-based
applications which analyze the location and the context-aware techniques for
collecting, processing, analyzing and visualizing such large-scale (Chen, Chiang, & Storey, 2012).
The computing platform for Web 4.0 is reflected in the increased real-time integration between users and the virtual worlds and objects they interact with (Kambil, 2008), while the computing platform for Web 5.0 is reflected in the decentralized smart communicator as indicated in (Patel, 2013).
In summary, HTTP, HTML, and URI have been the core of the Web since Web 1.0, HTTP is used for communication, HTML is used for web pages, and URI is used for identifying web objects such as web pages or frames. Although additional Web versions are merged from Web 2.0 to Web 5.0, these protocols are still the core, which is preserved by the new generation of the Web. The new generations of the Web are emerged to address some of the limitation of the previous generation and advance the capabilities of the Web.
References
Aghaei, S., Nematbakhsh, M. A.,
& Farsani, H. K. (2012). Evolution of the world wide web: From WEB 1.0 TO
WEB 4.0. International Journal of Web
& Semantic Technology, 3(1), 1.
Berners-Lee, T.
(1996). WWW: Past, present, and future. Computer,
29(10), 69-77.
Berners-Lee, T.,
Hendler, J., & Lassila, O. (2001). The semantic web.
Chen, H., Chiang,
R. H. L., & Storey, V. C. (2012). Business Intelligence and Analytics: From
Big Data to Big Impact. MIS quarterly, 36(4),
1165-1188.
Choudhury, N.
(2014). World Wide Web and its journey from web 1.0 to web 4.0.
Devlic, A., &
Jezic, G. (2005). Location-aware
information services using user profile matching.
Dubitzky, W.
(2008). Data Mining in Grid Computing
Environments: John Wiley & Sons.
Foster, I., Zhao,
Y., Raicu, I., & Lu, S. (2008). Cloud
Computing and Grid Computing 360-Degree Compared. Paper presented at the
2008 Grid Computing Environments Workshop.
Jacobs, I., &
Walsh, N. (2004). Architecture of the world wide web.
Ji, C., Li, Y.,
Qiu, W., Awada, U., & Li, K. (2012). Big
Data Processing in Cloud Computing Environments. Paper presented at the
2012 12th International Symposium on Pervasive Systems, Algorithms and
Networks.
Kambil, A.
(2008). What is your Web 5.0 strategy? Journal
of business strategy, 29(6), 56-58.
Patel,
K. (2013). Incremental journey for World Wide Web: introduced with Web 1.0 to
recent Web 5.0–a survey paper.
Socio-Technical Plan for Innovative Proactive Model
The number of the physical objects which are being connected to the Internet is growing at
very speed rate realizing the concept of the Internet of Things (Al-Fuqaha, Guizani, Mohammadi, Aledhari, & Ayyash, 2015). The computational intelligence and the
machine learning techniques have gained popularity in different domains. The internet of things and internet of people
are terms which can indicate the increasing interaction between humans and
machines. Internet of Things (IoT) is regarded
to be “one of the most promising fuels of Big Data expansion” (De Mauro, Greco, & Grimaldi, 2015).
Internet of things is the core component of Web 4.0. The Web has gone from the first generation of
Web 1.0 which was about static web pages, broadcasting information for
read-only. Web 1.0 was innovated by Berners-Lee (Aghaei, Nematbakhsh, & Farsani, 2012; Choudhury, 2014; Kambil, 2008;
Patel, 2013),
and is known as the “Web of Information Connections” (Aghaei et al., 2012). Web 2.0
which came out in 2004 is read-write and is known as the “Web of People
Connections (Aghaei et al., 2012) to connect people. Web 3.0 which came out in 2006 is known as
“Semantic Web” or the “Web of Knowledge Connections” to share knowledge,
followed by Web 4.0 is known as the “Web of Intelligence Connections” where Artificial
Intelligence (AI) is expected to play a role.
The current technology as indicated in TED’s video of (Hougland, 2014) can assist
people to save lives in case of unexpected health issues such as the heart
attack or stroke, by wearing a band in hand. There are also other tools for elder people
to save them when they fall, and they
need help while living alone by themselves with no assistance. These tools are reactive tools based on a
reactive model which can assist after the fact.
The major question for this project is:
“Can the “Web of Intelligence Connections” be
intelligent enough to be proactive and provide us with useful information on a daily basis?”
To
answer this very critical question, the researcher is proposing a
Proactive Model and the required Socio-Technical plan, besides the methods,
models, scenario planning for the future and the analytical plan for the
innovative model.
Introduction
Internet of Things (IoT) is a novel paradigm which is
rapidly gaining ground in modern wireless telecommunications domain (Atzori, Iera, & Morabito, 2010). The underlying
concept of the IoT is the pervasive presence of a variety of things or objects
around us such as Radio-Frequency Identification (RFID) tags, sensors,
actuators, mobile phones, and so forth.
The RFID and sensor network technologies will meet the challenge where
information and communication systems are invisibly embedded in the environment
around us (Gubbi, Buyya, Marusic, & Palaniswami, 2013).
For technology to get embedded as it gets disappeared from the consciousness of the users, the IoT demands things, such as a shared understanding of the situation of the users and their appliances (Gubbi et al., 2013). Other demands of the IoT for the technology to disappear from the conscious of the users include the software frameworks and pervasive communication networks to process and convey the contextual information to where it is relevant, and the analytics tools of IoT aiming for autonomous and smart behavior (Gubbi et al., 2013). Figure 1 illustrates the Semantics of the IoT showing the end users and application areas based on data, adapted from (Gubbi et al., 2013).
Figure 1: Internet of Things Semantics showing the end
users and application areas based on data. Adapted from (Gubbi et al., 2013).
Giving the potentials of the IoT and Semantic Webs, the
researcher is proposing an innovative model called “Proactive Model” which will
change how we live our lives. This new
model will introduce advanced tools through which people will communicate daily
about what to eat, what to exercise, what to drink, and basically what to do to
live a healthy life and to avoid any unexpected catastrophic event such as
stroke or heart attack. The existing
tools will still be available. However, the innovative approach of the
Proactive Model will be pervasive and embedded into our daily lives, and the
use of the reactive models will be minimum.
The Proactive Model is based on
the Internet of Things technologies and Web 4.0 and semantic web.
Forces such as technology, ease of
use, user acceptance, culture and so forth may affect the implementation of the
Proactive Model. The IoT is still facing
technical issues such as the bottleneck when processing large-scale of data,
DNS and TCP which need to be modified to better serve the IoT services (Atzori et al., 2010; Gubbi et al., 2013), and the Proactive Model which is based
on the IoT technology. Security and
privacy may be an obstacle to the implementation of the Proactive Model as the
data about our body, our activities and ourselves will be transmitted
continuously on a second-by-second basis somewhere in the Cloud. The supporting forces, as well as the
challenging forces, are discussed in detail later in this project.
Scope
The current model is a reactive model
which waits until the catastrophic event such as heart attack, a stroke happens.
As indicated in TED’s video of (Hougland, 2014), you can place a band in your hand which can assist
elder people or people who are highly likely exposed to some health issues such
as heart attack which can prevent them from living their lives. There are additional similar tools which can
help elder people who live alone to call for help when they fall, or any
unexpected thing happens to them. All
these tools are reactive tools which will still exist after the Proactive Model
but will have minimal use because the Proactive Model will take over.
The features of the
Proactive Model which distinguish it from the current reactive model include
the monitor of the health activities such as exercises, the monitor of the healthy
diets and the health factors levels such as potassium, and cholesterol, and the
monitor of the daily energy and performance.
These three major monitor features are the key factors for the success
of the Proactive Model. The Proactive
Model is expected to be intelligent and smart to guide individuals. It is
not limited to the elder people, but it will be available to all people at all
age levels. Thus, the result is promising
for the young generation and the elder generation, which will lead to the more
cognitive ability to their activities, diets and daily energy and performance.
The future of the
Proactive Model is very promising as the plan is to extend it to act as a
personal assistant providing guidance not only at the activities, diets or
energy level but also at the financial level.
The Proactive Model is expected to provide financial recommendations
such as closest and less expensive gym, and gas stations and so forth. Thus, the benefits of the Proactive Model
will embrace every aspect of our lives.
While the Proactive
Model provides very promising benefits to all people at all age levels, it has
the limitation that it does not measure psychological emotions or feelings, nor
depressions or emotional disorders. Moreover,
the cost of the Proactive Model may not be affordable especially for the
initial production release, which will make it only available for those who can
afford it. However, the plan is to make
it more affordable for all users.
Purpose
The purpose of this project is to propose an innovative
Proactive Model and its Socio-Technical plan in the age of Big Data and
Internet of Things (IoT). The innovative
Proactive Model is based on the IoT
technology, which is based on Web 4.0 the
Semantic Web. The Socio-Technical plan
is a critical component of the proposed model.
The key elements of both technical and social systems relevant to IoT technology
which is the underlying technology of the Proactive Model are identified through the analysis of the
current forces in both systems. The identification of these elements will allow
investigating how the technical and
social systems can be integrated together to create an environment which
supports effective Proactive Model while suppressing the dysfunctional aspects
of this new work environment. The
Socio-Technical plan includes not only the social and technology system, but
also other systems such as the medical system, policy makers and governance
system, and users, community, and culture system.
The potential impact of the
Socio-Technical plan in the context of the IoT technology and the Proactive
Model will involve not only the positive outcome and the impact which is
reflected in the “Joint Optimization,” but also in the “Affectability” of the system,
which will lead to better innovation, better performance, and a better
dialogical approach involving careful cognitive awareness of values, emotions,
and interests of all social groups.
Proactive Model Forces
The Socio-Technical plan will consider forces and factors which can affect the innovation such as complexity, compatibility, acceptance, ease of use, culture, trust, security, privacy and so forth. Figure 2 illustrates the integration of the technical system with the social system and the technical and social forces for the proposed innovative “Proactive Model.” These forces are not isolated or autonomous, nor they are static. They are dynamic, and the changes must be considered at both level the technical level as well as the social level. Thus, the arrows from technical to social and from social to technical illustrate the dynamic nature of the Socio-Technical system of the Proactive Model.
Figure 2. The Dynamic Innovative
Proactive Model Technical and Social Forces.
Supporting Forces
As illustrated in Figure 2, the technical forces include the
communication, energy, interoperability, security, device management, data
analytics, and recycling management. The
social forces include the ease of use, user acceptance, privacy and ethics, education and training, governance,
management support, business dynamics, partner collaboration, and culture and
religion. Some of these forces are supporting forces while other are
challenging forces. The supported
forces include the Web 4.0 technology and semantic web which provides a new
innovative paradigm which can support this new innovative Proactive Model
Socio-Technical system. The success of the existing reactive model and tools
which did not exist a few years ago is an
indication about the possibility of advanced
and better tools and models which are more intelligent using the Web
Intelligence technology. The need for
better health and better cognitive awareness system is a supporting
factor. When using the current reactive
model, the ambulance can be called as
indicated in TED’s video of (Hougland, 2014), to save the life of the person. Such a service is costly and can add stress to
the patients. However, with the
Proactive Model, this cost is reduced to the minimum. Thus, the reduction in cost is a supporting
factor in this innovative Proactive Model.
Moreover, the existing support of integrating Social and Technical
systems together is another supporting factor as the Proactive Model will not
start from scratch when integrating these two systems together, but rather
expanding on the current integrated systems to enhance the optimization as well
as the affectibility.
Challenging Forces
While there are supporting
forces for the Proactive Model, there are more challenging forces than the
supporting forces. The concept might be
new and not convincing that there will be a device to be used on a daily basis
other than the smartphones or tablets.
The device that is based on the
Proactive Model is to guide the person on
what food to eat, what exercises to do,
what food to avoid, what time to sleep, and so forth. The device will act intelligently as a bodyguard for the body be based on the measure of the vitamins in the body and the
nutrition elements that are needed for
the body. If there is a smart device now
to measure the glucose level of the diabetic people which is based on the current technology, there must
be other types of devices that are smarter based on the Web of Intelligence
Connections and Semantic Web of Web 4.0.
The technical complexity of developing such a device which will act as a
doctor who diagnoses the body on a daily
basis. Sensors might be required; blood reading might be required as the case with the diabetic
people, or saliva test, a patch to measure the blood pressure. These requirements must be communicated to
the medical experts. Thus, the
communication between technical experts and medical expert is another
challenging, in addition to the challenges of communicating this new technology
and model to the users. The security is
another challenge which will require securing all these data which will be
collected daily on the body needs, and organs functions. This data is expected to generate a large
amount of data which can be categorized
as Big Data. The analytical aspect of
such streaming data is another challenge which may require new algorithm. The recycling data is another challenge. This data which is collected on a daily basis might be
needed for a year for the analytical
purpose. However, after the end of the
life cycle of the data, it must be recycled fully and completely to protect the
privacy of the users. The privacy and
the ethics are challenges for this Proactive Model Socio-Technical system as it
is very critical to ensure the protection of the sensitive data especially if
this data deals with the body and the health of the person. The device of the Proactive Model may face
additional challenges in the culture and
religion domain, despite the anticipated benefits of such a technology. The business dynamics is another challenge
for this new model. The partner
collaboration is another challenge which needs
to be addressed to make sure all parties such as medical experts, technical
experts, executives and so forth are collaborating and working together to
achieve such a promising model.
Methods
As indicated in the challenging forces, collaboration and
communication among the involved parties are
required for the success of such a model. A method must be used to guarantee not only
the successful communication and collaboration among the involved parties but also the success of such a new
model. Thus, there is a requirement and
need for a structure of a group which focuses on providing a solution to a
particular problem in this new paradigm and new technology such as the Think
Tank (Caliva & Scheier, 1992). The “Think Tank” is the proposed method to be
used in the process of the development and implementation of this new
model. Think Tank has two models; the
“one roof” model and the “without a roof” models (Whittenhauer, n.d.). The
“without roof” model is described to be more effective than the “one roof” model because it does not require the funding
which is required for the “one roof” on travel costs and so forth. Thus, the Proactive Model will be using the
“without a roof” Think Tank model. The Think Tank for the Proactive Model will be named as Proactive Think Tank. The main objective of the “Proactive Think
Tank” is to drive not only the innovation of the Proactive Model but also the adoption of the new devices
at every age from teenagers, to adults to
seniors. The Proactive Think Tank will
ensure the integration of the technical system and social system to enhance the
optimization and the affectability of the Socio-Technical plan of the Proactive
Model.
Besides the Think Tank approach, the Delphi method will be used to provide the group communication process and make it effective enough to allow a group of individuals from different domains functioning as a whole to be able to deal with the complexity of this innovation (Saizarbitoria Iñaki, Arana Landín, & Casadesús Fa, 2006), which involves experts from technology and computer science domain, policy makers, users, community, and medical domain. The panel of the experts will not only be involved in the current design but also in the future of the Proactive Model and the Socio-Technical plan for that model. The key factors to ensure the success of the Proactive Model and the Socio-Technical plan are the selection of the members of the panel which should be based on their knowledge, capabilities, and independence. When using the Delphi method, the danger of dominant influence of any of the panel members is minimized because the identification of the members is hidden when expressing opinions.
Models
The traditional Socio-Technical approach is to design the technical component and then fit people to it (Appelbaum, 1997; L. Chen & Nath, 2008). This traditional approach leads to performance issues at high social costs (Appelbaum, 1997). Thus, the integration of social and technical elements is very critical. As indicated in (Geels, 2004), the focus should not just be on innovation, but also on the use and the functionality. In (Geels, 2004), the sectoral systems of innovation are expanded to be socio-technical systems. While the emphasis of the existing innovation systems is on the production side where innovations emerge, the expanded Socio-Technical systems involve production, diffusion, and use of technology (Geels, 2004). See Figure 3 for the basic elements and resources of Socio-Technical Systems, adapted from (Geels, 2004).
Figure 3. The Basic
Elements and Resources of Socio-Technical System. Adapted from (Geels, 2004).
The Socio-Technical systems are not autonomous
systems. However, they are the outcome
of the human activities, which are embedded
in social groups sharing certain characteristics such as certain roles,
responsibilities, norms, perceptions and so forth (Geels, 2004).
On the production side, the social groups can include education entities
such as schools and universities, public/private laboratories, technical
institutes, suppliers, banks, engineers and so forth. On the functional and user side, the social
group includes public authorities,
consumers, media, and so forth. Thus,
the Socio-Technical systems can form a structuring context for human actions on
both sides of the production and functional and user sides (Geels, 2004).
The Socio-Technical theory, which was introduced at the Tavistock
Institute in London in mid of 20th century, indicates that any
organization or the organizational work system has two independent sub-systems;
the social and the technical sub-systems (L. Chen & Nath, 2008). The social
sub-system is concerned with the attributes of people and users such as
attitude, skills, values and so forth, and the relationship between people,
reward systems, and the authority structures, while the technical sub-system is
concerned with the processes, tasks, and technology required to transform
inputs to outputs (L. Chen & Nath, 2008). The
underlying concept of the Socio-Technical theory is that the technical system
and social system must be integrated to determine the best overall solutions
for the organization (L. Chen & Nath, 2008). In contrast with the traditional and
conventional approach, using the Socio-Technical theory, the re-design of the
work system of the organization must consider the impact of each sub-system on
the other and the requirement for each sub-system simultaneously (L. Chen & Nath, 2008).
As proposed in (Hayashi & Baranauskas, 2013), the Socio-Technical
perspective might contribute to the dialogical approach to involve careful
listening and understand one another, as well as awareness of each other’s
values, emotions, and interests (Hayashi & Baranauskas, 2013). The design of the Socio-Technical system is based on the underlying concept and premise
that a work unit or an organization is a combination of both social and
technical elements (Appelbaum, 1997). Both
social and technical elements should work together to accomplish the ultimate
goal (Appelbaum, 1997). Thus,
the work system develops and produces both physical products and
social/psychological outcomes (Appelbaum, 1997). The
positive outcome called “Joint Optimization” is the key success factor for
these two elements of the social and technical (Appelbaum, 1997). Thus,
the Socio-Technical system for Proactive Model should involve all social groups
from software engineers and the employees to consumers at all levels. Moreover,
the “Affectability” concept which is proposed by (Hayashi & Baranauskas, 2013), for the Socio-Technical
perspective in the context of the educational technology, is another key
success factor for the Proactive Model.
The Joint Optimization and Affectability of the Socio-Technical Plan of the Proactive Model are implemented through the integration of all systems involved such as the technical system, social system, medical system, governance system. The integration and the communication of these systems to work together in harmony is a critical requirement for the Proactive Model. The Affectability of the Socio-Technical Plan will be demonstrated in the final product of the Proactive Model such as ease of use, user acceptance, and user trust. The proposed Socio-Technical Plan for the Proactive Model involves not only people and technology but also other domains such as medical as it plays a significant role in guiding health activities, diets, and energy. Figure 4 illustrates the proposed Four-Runner Socio-Technical Plan for the Proactive Model which is based on the IoT technology and Semantic Web.
Figure 4. The Proposed Four-Runner Socio-Technical Approach for the Innovative Proactive Model.
The innovation is not about developing new products, but it is about reinventing business process and building entirely new markets to meet untapped customer needs (Albarran, 2013). For some businesses, innovation is deliberative and planned, while for others innovation is the direct result of a triggering event such as a change in external market conditions or internal performance which forces a change in business strategy (Gershon). Three main types of innovations: product innovation, process innovation, and business model innovation. This innovative Proactive Model is not only about product innovation, but also process innovation and business model innovation. The product innovation is reflected in the final product which provides the health and financial benefits to people and organization. The process innovation and business model innovation reflect the integration of all systems to generate Joint Optimization and Affectability for the Socio-Technical plan and the product of the Proactive Model. The process model is illustrated in Figure 5.
Figure 5: Proposed Scenario Planning Model for the Innovative Proactive Model.
The key benefit of this proposed Scenario Planning process
is to reveal the different strategy of
the future based on which more flexible and more thoughtful and better decision
can be made. The process innovation model begins with the
analysis of the external and internal forces such as technical complexity for
the product, culture challenges, communication with other involved parties’
challenges. The second phase of this innovative process is
about the uncertainty analysis. The
third phase of this process involves strategic planning which contains all scenarios from best-case scenarios
to the worst-case scenarios. The fourth phase involves the opportunities
and strategy alternative, followed by the last phase of the strategy selection.
The proposed business model innovation involves new departments which are not a conventional department in organizations. Human Resources Department, Financial Department, Marketing Department, Information Technology, and Sales Departments are good examples of the conventional and traditional department in the organization. However, the innovative business model involves other departments such as medical department, governance department, and so forth in the organization. The Join Optimization and the Affectability of the Socio-Technical plan of the Proactive Model require the integration of these parties. Embedding new departments such as medical department and governance department in the organization can ensure the success of the process innovation and the product innovation. Figure 6 illustrates the business model innovation for the Proactive Model.
Figure 6.
Innovative Business Model for the Innovative Proactive Model.
Analytical Plan
As illustrated in the proposed Scenario Planning, the
analysis begins with the internal and external forces such as communication and
integration between these units of technology, medical, governance, and people.
The analysis should also cover the technical complexity and the current
algorithm and machine learning. The
analysis can reveal the need for the new
algorithm, or new models. The analysis
plan should also include the uncertainty factors which can have a negative
impact on the implementation of the Proactive Model. One major uncertainty factor is the
acceptance of users, which needs to be analyzed and measured regarding population, age, profession, income,
and so forth.
The analytical plan for this Proactive Model includes the proto-type analysis which is the
first product pre-release to ensure the product is
implemented in accordance with the
design specifications and requirements.
The proto-type analysis can take between 1-3 months analysis based on
the model of the device, simple model, medium model, and complex model. The
analysis plan will also include more comprehensive analysis based on a survey on the acceptance of the product, ease
of the product, and trust of the product.
As indicated in (Wu, Zhao, Zhu, Tan, & Zheng, 2011) understanding the reasons for
the acceptance or rejection of a new product is very challenging. However, the Technology Acceptance Model
(TAM) is regarded to be the most powerful theory to analyze the explain the
technology usage behavior and whether the product acceptance is based on ease of use, trust or other
factors. This model has been extended to
include the trust factor as indicated in (Wu et al., 2011). This comprehensive
analysis plan includes the TAM model as illustrated in Figure 7. The analysis covers the relationship among
the identified variables, and the direct effect of
the variables to provide insight into the central tendencies of the
relationships. Thus, statistical
analysis will be used such as coefficient, correlation, ranges, central
tendencies, and analysis of variances ANOVA.
The Innovation Diffusion Theory (IDT) is another well-established theory to analyze the user adoption (L.-d. Chen, Gillenson, & Sherrell, 2004). The innovation diffusion is achieved through the acceptance of the users and the use of new ideas or things such as the Proactive Model-based device. As indicated d in (L.-d. Chen et al., 2004), the relative advantages, the compatibility, complexity, “triability,” and observability were found to explain 49 to 87 percent of the variance in the rate of its adoption. Other studies found that relative advantage, compatibility, and complexity were found consistently related to the rate of innovation adoption (L.-d. Chen et al., 2004). Thus, these critical variables will be used in the comprehensive analysis of the innovative Proactive Model which is based on IoT technology, and the Joint Optimization of the proposed Socio-Technical plan.
Figure 7. The Proposed Model for the innovative Proactive Model based on TAM and IDT Model to Analyze and Evaluate the User Acceptance, and all other Variables.
Anticipated Results
The organizations involved in this innovative Proactive
Model represent diverse industries such as IT, Health, Policy Makers and
Governance. Other organizations such as
Financial, and insurance may get involved to shape additional features of the
Proactive Model. Tremendous efforts are
expected to be exerted at all
organizations level. The commitment and
the determination of these organization must drive this innovation because it
will change the way we live our daily lives.
The initial reaction of users might not be completely positive. It might receive rejection or resistance from
users and medical industry, as it might be
threatening to the medical field. This innovation is to enhance the
medical field and health insurance. The initial user interface might be
challenging. However, the user interface is expected to be advanced and more
intuitive to all users. The cost factor
will play another role in the adoption of the new innovative Proactive
Model. Until the cost goes down, only
the users who can afford it will be able to enjoy the benefits of such
innovation. The anticipated result also
involves the impact of the culture and religion on the adoption of this
innovation. It might not get adopted
completely in certain communities due to culture and certain practices. This innovation is not expected to celebrate
success completely for several decades.
However, afterward, this
innovation will be embedded into our lives and will become invisible as it is
expected to be part of our lives.
Conclusion
The internet has changed the way we
live our lives today, and how we communicate with each other, and how we
perform our work. The interaction
between people is completely different today than the interaction between
people a few decades ago. The human innovation has moved along from
sending messages using birds which arrive in several days or months, to sending
messages using smartphone which arrives at
the receiver instantaneously.
Technology without social consideration will be hard to
sell. Organizations and businesses such
as Blockbuster and Yahoo are good
examples for those organizations which did not consider the social system and
did not lean to the users’ requirements, besides the lack of strategic scenario
planning. Thus, the researcher proposed
an innovative Proactive Model which is based
on the IoT, Web 4.0 and Semantic Web with a proposed Socio-Technical system to
ensure the success of this innovation.
The purpose of the Proactive Model is not only to save lives but also to
live healthy lives. The current model is
reactive waiting until a catastrophic event happens to react and save the life
of people. The IoT technology and Semantic Web have the
potential to add a new dimension to our lives, and how we live our daily lives
and how not only people communicate with each other but also how devices will
communicate with each anywhere and anytime.
This project also covered the external and internal forces
which can have a positive and negative
impact on the implementation and adoption of the Proactive Model. The analysis of these factors provides a
good insight into the anticipated results
of the innovation and the timeframe for full implementation. The project also discussed the methods to be
implemented to ensure communications and sound decisions from the involved
experts are made using Delphi method and the Think Tank approach as well.
For the analytical plan, the analysis will start with the
external and internal forces to overcome any challenges at that level. The analysis plan includes the uncertainty
associated not only with the diffusion of innovation but also with the
underlying concept of the Proactive Model to live smart life. After the consideration of the Socio-Technical
plan and the strategic scenario planning, the first release will be analyzed and evaluated using the prototype for one to three months. Any modification to the original design and
all involved components such as sensors are
implemented, a more comprehensive analysis plan will be conducted.
The comprehensive analytical plan applies the concept of TAM and IDT
models to evaluate and analyze the acceptance of users, the ease of use, and
trust, which can lead to the behavioral intention for use. The anticipated result based on the
historical records for innovation indicate the minimal use at the beginning of
the product release. However, after few years, the product will be mature
enough and known enough to be used ubiquitously
as it is expected to be embedded and invisible in our lives. Our today’s life will be described by the future
generations as a primitive generation, the same way we now describe the
“stone age” generation.
Areas of Future Research
The IoT is a promising domain which requires future research. It
is part of the Web 4 and Semantic Web.
The Proactive Model is based on
these advanced technologies. There are
several areas for more research using this technology. Examples of these areas of future research
include robotic models such as robotic taxi (Atzori et al., 2010), robotic assistant, robotic teachers, and
robotic cars which can be on the road without drivers. The smart
environment requires more research in different areas such as comfortable homes
and offices for all people with automated systems with minimum cost. The industrial plant is another area for more
research to integrate robotics and automation at a higher level using IoT. As indicated in (Atzori et al., 2010), the machine/robot can help in improving the
automation in industrial plants with a massive deployment of RFID tags
associated with the production
parts. Interconnection of various
systems to develop a smart city can provide ubiquitous services to improve the
quality of life in the city by making it easier and more convenient for people
to find information of interest (Al-Fuqaha et al., 2015).
The underlying concept behind the areas for future research
is the IoT technology and the Semantic Web technology which involves Artificial
Intelligence. The key element is the
intelligence and how we can turn all systems to be smart to be under the human
services. The future innovations are
anticipated to involve smart and intelligent robotics devices and systems. The implications of these robotic innovations
are not trivial. However, if these innovations do not sound feasible today,
they might be very much feasible and embedded into the human lives several
decades from today.
References
Aghaei, S., Nematbakhsh, M. A., &
Farsani, H. K. (2012). Evolution of the world wide web: From WEB 1.0 TO WEB
4.0. International Journal of Web &
Semantic Technology, 3(1), 1.
Al-Fuqaha, A., Guizani,
M., Mohammadi, M., Aledhari, M., & Ayyash, M. (2015). Internet of things: A
survey on enabling technologies, protocols, and applications. IEEE Communications Surveys & Tutorials,
17(4), 2347-2376.
Albarran, A. B. (2013). Media management and economics research in a
transmedia environment: Routledge.
Appelbaum, S. H. (1997).
Socio-technical systems theory: an intervention strategy for organizational
development. Management decision, 35(6),
452-463.
Atzori, L., Iera, A.,
& Morabito, G. (2010). The internet of things: A survey. Computer networks, 54(15), 2787-2805.
Chen, L.-d., Gillenson,
M. L., & Sherrell, D. L. (2004). Consumer acceptance of virtual stores: a
theoretical model and critical success factors for virtual stores. ACM SIGMIS Database, 35(2), 8-31.
Chen, L., & Nath, R.
(2008). A socio-technical perspective of mobile work. Information Knowledge Systems Management, 7(1, 2), 41-60.
Choudhury, N. (2014).
World Wide Web and its journey from web 1.0 to web 4.0.
De Mauro, A., Greco, M.,
& Grimaldi, M. (2015). What is big
data? A consensual definition and a review of key research topics. Paper
presented at the AIP Conference Proceedings.
Geels, F. W. (2004). From
sectoral systems of innovation to socio-technical systems: Insights about
dynamics and change from sociology and institutional theory. Research policy, 33(6-7), 897-920.
Gershon, R. A. MEDIA
INNOVATION: Disruptive Technology and the Challenges of Business Reinvention:
Kalamazoo, Western Michigan University.
Gubbi, J., Buyya, R.,
Marusic, S., & Palaniswami, M. (2013). Internet of Things (IoT): A vision,
architectural elements, and future directions. Future Generation computer systems, 29(7), 1645-1660.
Hayashi, E. C., &
Baranauskas, M. C. C. (2013). Affectibility in educational technologies: A
socio-technical perspective for design. Journal
of Educational Technology & Society, 16(1), 57.
Kambil, A. (2008). What
is your Web 5.0 strategy? Journal of
business strategy, 29(6), 56-58.
Patel, K. (2013).
Incremental journey for World Wide Web: introduced with Web 1.0 to recent Web
5.0–a survey paper.
Saizarbitoria Iñaki, H.,
Arana Landín, G., & Casadesús Fa, M. (2006). A Delphi study on motivation
for ISO 9000 and EFQM. International
Journal of Quality & Reliability Management, 23(7), 807-827.
Wu, K., Zhao, Y., Zhu,
Q., Tan, X., & Zheng, H. (2011). A meta-analysis of the impact of trust on
technology acceptance model: Investigation of moderating influence of subject
and context type. International Journal of Information Management, 31(6),
572-581.
Introduction: The purpose of this discussion is to discuss and analyze a business that had a good plan, but something went wrong because of circumstances which are beyond their control. These circumstances can be new technology, market changes, innovative competitors and so forth. The discussion also addresses an example to illustrate a potential impact for the socio-technical plan which will be proposed in later discussions.
There are various examples for some of the businesses that had good plans, but something went wrong. These examples include Netscape, AOL, AltaVista, MySpace, Yahoo, Sun, Sony, Sun Microsystem, and more (Newman, 2010). The focus of this discussion is limited to Yahoo.
Yahoo:
Yahoo was founded in 1994 two Stanford University
graduates Jerry Yang and David Filo (Thomas,
2016). For the past two decades, Yahoo strove to
develop one of the most visited sites and a robust online display advertising
business (Dwoskin,
2016; Thomas, 2016). Yahoo was a “veritable web titan,” a leader
in email, online news, and search during the 1990s and early 2000s (Thomas,
2016). It was described as “one-stop shop bringing
together news and other services for users lacking expertise in navigating the
internet” (Thomas,
2016).
However, after the competition with Google and Facebook,
Yahoo could not survive (Dwoskin,
2016; Forbes, 2016; Thomas, 2016). Google viewed the core challenge as an
algorithmic problem to find the best Web sites through automated indexing
instead of using manual indexing as the case with Yahoo. Moreover, Google and Facebook attracted the
best engineers and employed a leaner operation to remain flexible and sensitive
to what prospective customers want.
Thus, the lessons learned from Yahoo which could not survive in the face
of Google and Facebook include several factors:
Focus on one thing and become the best at it, effective automation,
quality hiring, and lean operation (Forbes,
2016). Moreover, Google realized the importance of
acquisition and made some strategic acquisitions such as YouTube, whose team
developed Android OS, and recently DeepMind.
Yahoo, on the other hand, was not good or did not pay attention to the
acquisition strategies and their integration. The last but not least, planning and
optimization for large-scale data processing, engineering, business, and
branding ensures the continuing innovation and help in capturing new markets (Forbes,
2016).
Internet of Things Semantics
and Socio-Technical: Internet of Things (IoT) is a novel
paradigm which is rapidly gaining ground in modern wireless telecommunications
domain (Atzori, Iera, & Morabito,
2010). The underlying
concept of the IoT is the pervasive presence of a variety of things or objects
around us such as Radio-Frequency Identification (RFID) tags, sensors,
actuators, mobile phones, and so forth.
The RFID and sensor network technologies will meet the challenge where
information and communication systems are invisibly embedded in the environment
around us (Gubbi, Buyya, Marusic, & Palaniswami, 2013). The IoT and
Internet of People are term which can indicate the increassing interaction between
humans and machiens. The IoT is regarded
as “one of the most promising fuels of Big Data expansion” (De Mauro, Greco, & Grimaldi, 2015). IoT is the core
component of Web 4.0. The current
technology, as indicated in TED’s video of (Hougland, 2014), can assist people to save lives in case of unexpected
health issues such as the hearth attack or stroke, by wearing a band in
hand. There are also other tools for the
elder people to save them when they fall, and they need help while living alone
by themeselves with no assistance. These
tools of the current technologies are reactive tools which can asist after the
fact. The question is “Can the “Web of
Intelligence Connections” be intelligent enough to be proactive and provide u
with useful information on a daily basis?”
The researcher is proposing an innovative model called “Proactive Model”
which will change how we live our lives.
This new model will introduce advanced tools through which people will
communicate daily about what to eat, when to exercies, what to drink, and
basically what to do to live healthy and to avoid any unexpected catastrophic
event such as stroke or heart attack.
The existing tools will still be available. However, the innovative
approach of the Proactive Model will be pervasive and embedded into our daily
lives and the use of the reactive models will be minimum.
As proposed in (Hayashi &
Baranauskas, 2013), the Socio-Technical perspective might contribute to
the dialogical approach to involve careful listening and understand one
another, as well as awareness of each other’s values, emotions, and interests (Hayashi &
Baranauskas, 2013). The design of
the Socio-Technical system is based on
the underlying concept and premise that a work unit or an organization is a
combination of both social and technical elements (Appelbaum, 1997). Both social
and technical elements should work together to accomplish the ultimate goal (Appelbaum, 1997). Thus, the
work system develops and produces both physical products and
social/psychological outcomes (Appelbaum, 1997). The positive
outcome called “Joint Optimization” is the key success factor for these two
elements of the social and technical (Appelbaum, 1997). Thus, the Socio-Technical system for IoT
should involve all social groups from software engineers and the employees to
consumers at all levels. Moreover, the “Affectability” concept which is
proposed by (Hayashi &
Baranauskas, 2013), for the Socio-Technical perspective in the context
of the educational technology, is another key success factor.
Thus, the potential impact of the Socio-Technical plan in the
context of the IoT technology will involve not only the positive outcome and
impact reflected in the “Joint Optimization,” but also in the “Affectability”
of the system, which will lead to better innovation, better performance, and a
better dialogical approach involving careful cognitive awareness of values,
emotions, and interests of all social groups. The Socio-Technical plan will consider forces
and factors which can affect the innovation such as complexity, acceptance,
ease of use, culture, trust, security, privacy and so forth.
References
Appelbaum, S. H. (1997).
Socio-technical systems theory: an intervention strategy for organizational
development. Management decision, 35(6),
452-463.
Atzori, L., Iera,
A., & Morabito, G. (2010). The internet of things: A survey. Computer networks, 54(15), 2787-2805.
De Mauro, A.,
Greco, M., & Grimaldi, M. (2015). What
is big data? A consensual definition and a review of key research topics.
Paper presented at the AIP Conference Proceedings.
Gubbi, J., Buyya,
R., Marusic, S., & Palaniswami, M. (2013). Internet of Things (IoT): A
vision, architectural elements, and future directions. Future Generation computer systems, 29(7), 1645-1660.
Hayashi, E. C.,
& Baranauskas, M. C. C. (2013). Affectibility in educational technologies:
A socio-technical perspective for design. Journal
of Educational Technology & Society, 16(1), 57.