Dr. Aly, O.
Computer Science
Introduction
The purpose of this discussion is to discuss the supervised learning and how it can be used in large datasets to overcome the problem where everything is significant with statistical analysis. The discussion also addresses the importance of a clear purpose of supervised learning and the use of random sampling.
Supervised Learning (SL) Algorithm
In accordance with the (Hall, Dean, Kabul, & Silva, 2014), SL “refers to techniques that use labeled data to train a model.” It is comprised of “Prediction” (“Regression”) algorithm, and “Classification” algorithm. The “Regression” or “Prediction” algorithm is used for “interval labels,” while the “Classification” algorithm is used for “class labels” (Hall et al., 2014). In the SL algorithm, the training data represented in observations, measurements, and so forth are associated by labels reflecting the class of the observations (Han, Pei, & Kamber, 2011). The new data is classified based on the “training set” (Han et al., 2011).
The “Predictive Modeling” (PM) operation of the “Data Mining” utilizes the same concept of the human learning by using the observation to formulate a model of specific characteristics and phenomenon (Coronel & Morris, 2016). The analysis of an existing database to determine the essential characteristics “model” about the data set can implement using the PM operation (Coronel & Morris, 2016). The (SL) algorithm develops these key characteristics represented in a “model” (Coronel & Morris, 2016). The SL approach has two phases: (1) Training Phase, and (2) Testing Phase. In the “Training Phase,” a model utilizing a large sample of historical data called “Training Set” is developed. In the “Testing Phase,” the model is tested on new, previously unseen data, to determine the accuracy and the performance characteristics. The PM operation involves two approaches: (1) Classification Technique, and (2) Value Prediction Technique (Connolly & Begg, 2015). The nature of the predicted variables distinguish both techniques of the classification and value prediction (Connolly & Begg, 2015).
The “Classification Technique” involves two specializations of classifications: (1) “Tree Induction,” and (2) “Neural Induction” which are used to develop a predetermined class for each record in the database from a set of possible class values (Connolly & Begg, 2015). The application of this approach can answer questions like “What is the probability for those customers who are renting to be interested in purchasing home?”
The “Value Prediction,” on the other hand, implements the traditional statistical methods of (1) “Linear Regression,” and (2) “Non-Linear Regression” which are used to estimate a continuous numeric value that is associated with a database record (Connolly & Begg, 2015). The application of this approach can be used for “Credit Card Fraud Detection,” and “Target Mailing List Identification” (Connolly & Begg, 2015). The limitation of this approach is that the “Linear Regression” works well only with “Linear Data” (Connolly & Begg, 2015). The application of the PM operation includes the (1) “Customer Retention Management,” (2) “Credit Approval,” (3) “Cross-Selling,” and (4) “Direct Marketing” (Connolly & Begg, 2015). Furthermore, the Supervised methods such as Linear Regression or Multiple Linear Regression can be used if there exists a strong relationship between a response variable and various predictors (Hodeghatta & Nayak, 2016).
Clear Purpose of Supervised Learning
The purpose of the supervised learning must be clear before the implementation of the data mining process. Data mining process involves six steps in accordance to (Dhawan, 2014). They are as follows.
- The first step includes the exploration of the data domain. To achieve the expected result, understanding and grasping the domain of the application assist in accumulating better data sets that would determine the data mining technique to be applied.
- The second phase includes the data collection. In the data collection stage, all data mining algorithms are implemented on some data sets.
- The third phase involves the refinement and the transformation of the data. In this stage, the datasets will get more refined to remove any noise, outliner, missing values, and other inconsistencies. The refinement of the data is followed by the transformation of the data for further processing for analysis and pattern extraction.
- The fourth step involves the feature selection. In this stage, relevant features are selected to apply further processing.
- The fifth stage involves the application of the relevant algorithm. After the data is acquired, cleaned and features are selected, in this step, the algorithm is selected to process the data and produce results. Some of the commonly used algorithms include (1) clustering algorithm, (2) association rule mining algorithm, (3) decision tree algorithm, and (4) sequence mining algorithm.
- The last phase involves the observation, the analysis, and the evaluation of the data. In this step, the purpose is to find a pattern in the result produced by the algorithm. The conclusion is typically based on the observation and evaluation of the data.
Classification is one of the data mining techniques. Classification based data mining exists as the cornerstone of the machine learning in artificial intelligence (Dhawan, 2014). The process in the Supervised Classification begins with given sample data, also known as a training set, consists of multiple entries, each with multiple features. The purpose of this supervised classification is to analyze the sample data and to develop an accurate understanding or model for each class using the attributes present in the data. This supervised classification is used to classify and label test data. Thus, the precise purpose of the supervised classification is very critical to analyze the sample data and develop an accurate model for each class using the attributes present in the data. Figure 1 illustrates the supervised classification technique in data mining as depicted in (Dhawan, 2014).
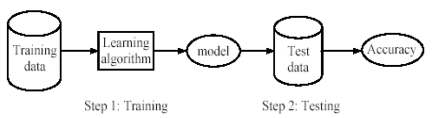
Figure 1: Linear Overview of steps involved in Supervised Classification (Dhawan, 2014)
The conventional techniques employed in the Supervised Classification involves the known algorithms of (1) Bayesian Classification, (2) Naïve Bayesian Classification, (3) Robust Bayesian Classifier, and (4) Decision Tree Learning.
Various Types of Sampling
A sample of records can be taken for any analysis unless the dataset is driven from a big data infrastructure (Hodeghatta & Nayak, 2016). A randomization technique should be used, and steps must be taken to ensure that all the members of a population have an equal chance of being selected (Hodeghatta & Nayak, 2016). This method is called probability sampling. There are various variations on this sampling type: Random Sampling, Stratified Sampling, and Systematic Sampling (Hodeghatta & Nayak, 2016), cluster, and multi-stage (Saunders, 2011). In Random Sampling, a sample is picked randomly, and every member has an equal opportunity to be selected. In Stratified Sampling, the population is divided into groups, and data is selected randomly from a group or strata. In Systematic Sampling, members are selected systematically, for instance, every tenth member of that particular time or event (Hodeghatta & Nayak, 2016). The most appropriate sampling technique to obtain a representative sample should be implemented based on the research question(s) and the objectives of the research study (Saunders, 2011).
In summary, supervised learning is comprised of Prediction or Regression, and Classification. In both approaches, a clear understanding of the SL is critical to analyze the sample data and develop an accurate understanding or model for each class using the attributes present in the data. There are various types of sampling: random, stratified and systematic. The most appropriate sampling technique to obtain a representative sample should be implemented based on the research question(s) and the objectives of the research study.
References
Connolly, T., & Begg, C. (2015). Database Systems: A Practical Approach to Design, Implementation, and Management (6th Edition ed.): Pearson.
Coronel, C., & Morris, S. (2016). Database systems: design, implementation, & management: Cengage Learning.
Dhawan, S. (2014). An Overview of Efficient Data Mining Techniques. Paper presented at the International Journal of Engineering Research and Technology.
Hall, P., Dean, J., Kabul, I. K., & Silva, J. (2014). An Overview of Machine Learning with SAS® Enterprise Miner™. SAS Institute Inc.
Han, J., Pei, J., & Kamber, M. (2011). Data mining: concepts and techniques: Elsevier.
Hodeghatta, U. R., & Nayak, U. (2016). Business Analytics Using R-A Practical Approach: Springer.
Saunders, M. N. (2011). Research methods for business students, 5/e: Pearson Education India.
